Tutoriel
Ce tutoriel fournit un exemple étape par étape de l'application de l'OCR à un document PDF numérisé. Les fichiers d'exemple sont disponibles à l'emplacement suivant :
C:\Users\<UserName>\Documents\Altova\MapForce<YEAR>\MapForceExamples\Tutorial\OCR
Fichier source : document PDF numérisé
Notre fichier source est un document PDF numérisé d'une page appelée Catalog2025.pdf (capture d'écran ci-dessous).
Étape 1 : Créer un modèle PXT et charger le document PDF
À ce stade, nous avons créé un fichier PXT et importé notre document PDF numérisé (voir également Flux de travail OCR).
Étape 2 : Réviser les mots détectés
Lorsque le document ocr.pdf nouvellement créé s'ouvre dans une fenêtre séparée, l'OCR est automatiquement appliqué au document. Les résultats de l'OCR sont affichés dans l'arborescence des objets (capture d'écran ci-dessous). Ils peuvent également être affichés dans la zone de numérisation du document si la commande Afficher superpositions de la barre d'outils est activée.
Dans notre exemple, nous avons activé les commandes Afficher superpositions et Afficher toutes superpositions. Les mots surlignés en vert sont inclus dans l'arborescence des mots détectés. Les mots affichés en rouge ont été exclus car la fiabilité de l'OCR était peut-être inférieure au seuil.
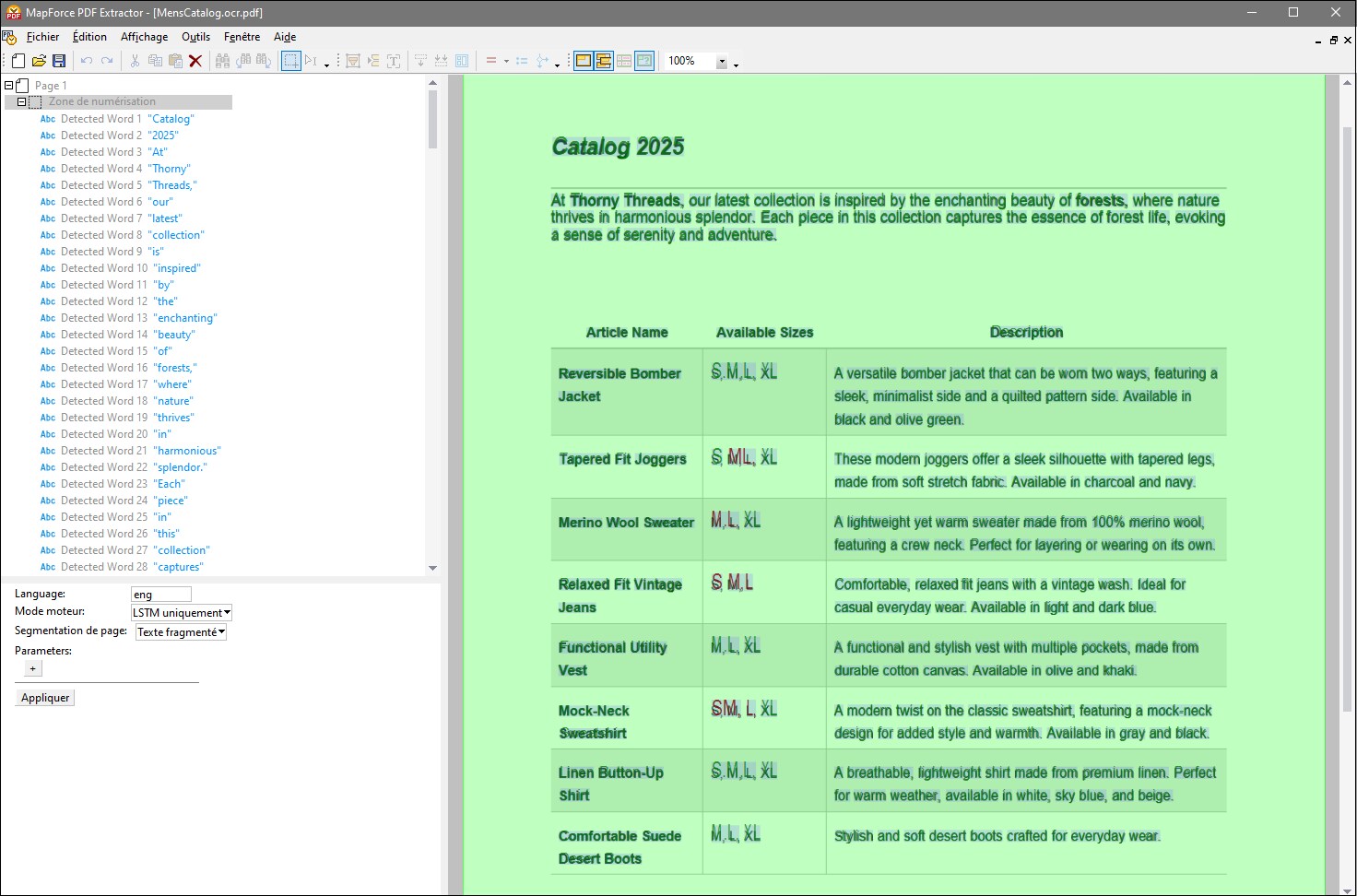
Dans l'ensemble, le processeur OCR a correctement détecté la plupart du texte, à l'exception de certaines tailles. Dans ce tutoriel, nous présentons l'une des approches possibles pour corriger les résultats. Par exemple, dans la cellule contenant des informations sur les tailles de l'article Tapered Fit Joggers, deux mots ont été identifiés (S et XL) et un mot détecté a été exclu (ML). Pour corriger ces résultats, procédez comme suit :
1.Cliquez sur ML dans le volet d'affichage PDF et supprimez ce mot. Faites de même pour XL.
2.Double-cliquez sur S et modifiez le texte pour inclure d'autres tailles : S, M, L, XL. Une fois la modification terminée, appuyez sur Entrée. Les mots modifiés apparaissent désormais sous la forme UserWords au bas de l'arborescence des objets. Notez que la zone de texte modifiée peut chevaucher d'autres mots détectés (capture d'écran ci-dessous). Si tel est le cas, l'extraction de texte risque de ne pas fonctionner correctement.
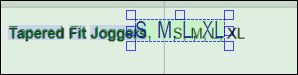
3.Positionnez la zone de texte de manière à ce qu'elle corresponde étroitement au texte d'origine, comme illustré ci-dessous. Cela garantit que le texte est extrait correctement.

4.Répétez les mêmes étapes pour toutes les autres tailles qui ont été détectées de manière incorrecte.
Étape 3 : Enregistrer le modèle OCR et définissez le modèle PXT
Une fois que vous avez terminé de modifier les mots détectés, enregistrez le modèle OCR et revenez à la fenêtre PXT. À ce stade, l'objectif principal est de créer un modèle qui vous permette d'extraire le texte détecté par le processeur OCR. Suivez les instructions ci-dessous :
1.Assurez-vous que la commande Afficher suggestions de la barre d'outils est activée.
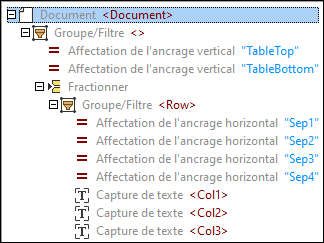
2.Utilisez la première suggestion de tableau automatique pour créer une structure de tableau dans le volet Schéma.

En conséquence, l'arborescence d'objets suivante a été créée :
3.Comme nous avons utilisé la suggestion de tableau qui ne contenait qu'une seule ligne, nous devons déplacer TableBottom vers le bas pour inclure toutes les lignes du tableau. Pour ce faire, cliquez sur l'ancrage vertical TableBottom dans l'arborescence, cliquez sur le libellé TableBottom dans le volet d’affichage PDF et faites glisser la ligne vers le bas.

La modification de TableBottom met à jour les résultats dans le volet Output et inclut toutes les données du tableau.
4.Donnez aux objets de l'arborescence des noms significatifs, comme indiqué ci-dessous. La modification des noms des objets met également à jour les éléments XML dans le volet Sortie.
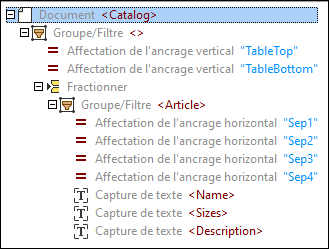
5.Créez des captures de texte pour l'année du catalogue et la description, comme indiqué ci-dessous.

Sortie
Le modèle a extrait avec succès les données OCR de notre document PDF numérisé. Le résultat s'affiche dans le volet Sortie :
<Catalog> <Year>2025</Year> <Info>At Thorny Threads, our latest collection is inspired by the enchanting beauty of forests, where nature thrives in harmonious splendor. Each piece in this collection captures the essence of forest life, evoking a sense of serenity and adventure.</Info> <Article> <Name>Reversible Bomber Jacket</Name> <Sizes>S, M, L, XL</Sizes> <Description>A versatile bomber jacket that can be worn two ways, featuring a sleek, minimalist side and a quilted pattern side. Available in black and olive green.</Description> </Article> <Article> <Name>Tapered Fit Joggers</Name> <Sizes>S, M, L, XL</Sizes> <Description>These modern joggers offer a sleek silhouette with tapered legs, made from soft stretch fabric. Available in charcoal and navy.</Description> </Article> <Article> <Name>Merino Wool Sweater</Name> <Sizes>M, L, XL</Sizes> <Description>A lightweight yet warm sweater made from 100% merino wool, featuring a crew neck. Perfect for layering or wearing on its own.</Description> </Article> <Article> <Name>Relaxed Fit Vintage Jeans</Name> <Sizes>S, M, L</Sizes> <Description>Comfortable, relaxed fit jeans with a vintage wash. Ideal for casual everyday wear. Available in light and dark blue.</Description> </Article> <...> </Catalog> |
Si vous remarquez des problèmes avec les données extraites dans le volet Sortie, vous pouvez ajuster le modèle OCR, l'enregistrer et vérifier à nouveau les résultats dans la fenêtre PXT.
Étapes suivantes
La définition du modèle d'extraction PDF est terminée. L'étape suivante consiste à importer le modèle dans MapForce et à créer un mappage pour traiter les données PDF extraites.