Exemple : Créer des hiérarchies depuis des fichiers texte CSV et de longueur fixe
Cet exemple est disponible sous le chemin suivant : <Documents>\Altova\MapForce2026\MapForceExamples\Tutorial\Tut-headerDetail.mfd. L'exemple utilise un fichier CSV (Orders.csv) qui dispose du format suivant :
•Champ 1 : H définit un enregistrement d'en-tête et D un enregistrement de détail.
•Champ 2 : Une clé commune pour les enregistrements d'en-tête et de détail.
•Chaque enregistrement Header ou Detail sur une ligne séparée.
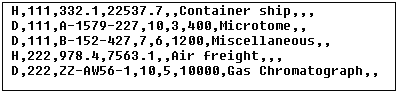
Les contenus du fichier Orders.csv sont indiqués ci-dessous.
L'objectif du mappage est le suivant :
•Mapper le fichier plat CSV à un fichier XML hiérarchique
•Filtrer les enregistrements Header, conçus avec un H
•Associer les enregistrements de détail respectifs, conçus avec un D, avec chacun des enregistrements d'en-tête.
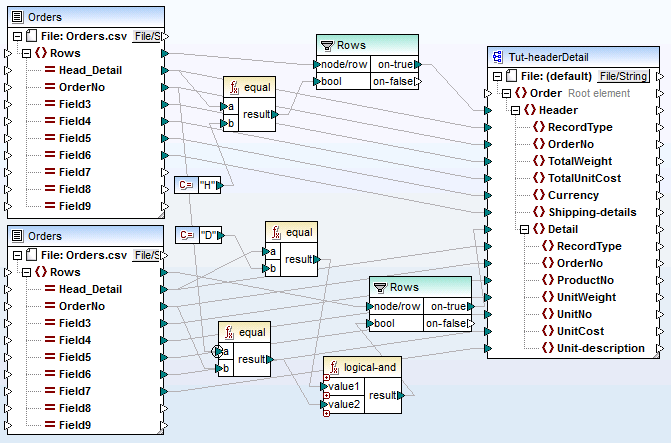
tut-headerDetail.mfd
Afin d'y parvenir, les enregistrements d'en-tête et de détail doivent avoir un champ en commun. Dans ce cas, le champ commun, ou la clé, est le deuxième champ du fichier CSV, c'est à dire OrderNo. Dans le fichier CSV, l'enregistrement du premier en-tête et les deux enregistrements de détail suivants contiennent la valeur commune 111.
Le fichier Orders.csv a été inséré deux fois pour rendre le mappage plus intuitif.
Le fichier de schéma Tut-headerDetail.xsd possède une structure hiérarchique : "Order" est l'élément racine, avec "Header" en tant que son élément enfant, et "Detail" étant un élément enfant de "Header".
Le premier fichier Orders.csv fournit les enregistrements Header (et tous les champs mappés) vers l'item "Header" dans le fichier cible de schéma. Le composant de filtre est utilisé pour filtrer tous les enregistrements ne commençant pas avec H. L'item Rows fournit ces enregistrements filtrés à l'item "Header" dans le fichier de schéma.
Le second fichier Orders.csv fournit les enregistrements Detail (et tous les champs mappés) en filtrant les enregistrements "Detail" qui correspondent à la clé OrderNo de l'enregistrement "Header". Cela est obtenu en :
•Comparant le champ OrderNo de l'enregistrement "Header" avec le même champ des enregistrements "Detail", en utilisant la fonction equal (le contexte de priorité est défini sur le paramètre a pour une meilleure performance).
•Utilisant la fonction Logical-and non seulement pour fournir ces enregistrements "Detail" contenant le même champ OrderNo, en tant qu'enregistrement "Header".
L'item Rows fournit ces enregistrements filtrés aux items "Header" et "Detail" dans le fichier de schéma, par le biais du paramètre on-true du composant de filtre.
Cliquer sur l'onglet Sortie pour produire le fichier XML affiché ci-dessous. Chaque enregistrement "Header" contient ses données et tous les enregistrements "Detail" associés qui ont le même "OrderNo".

Examinons à présent un autre exemple, qui utilise un fichier CSV légèrement différent et qui est disponible dans le dossier <Documents>\Altova\MapForce2026\MapForceExamples\Tutorial\ en tant que Head-detail-inline.mfd. La différence est que :
• Aucun désignateur d'enregistrement (H ou D) n'est disponible
•Un champ de clé commun, le premier champ du fichier CSV, existe toujours aussi bien pour les enregistrements header que detail (Head-key, Detail-key...). Le champ est mappé sur OrderNo dans la cible de schéma
•Le champ "Header" et tous les champs "Detail" respectifs se trouvent sur la même ligne.
![]()
Le mappage a été conçu comme suit :
•Les champs clé sont mappés vers les items OrderNo respectifs dans la cible de schéma.
•L'item "Detail" dans le fichier cible de schéma a été dupliqué et est affiché en tant que Detail (2). Cela vous permet de mapper le deuxième ensemble d'enregistrements de détail vers l'item correct.
•Le résultat de ce mappage est en principe le même fichier XML qui a été produit dans le premier exemple.
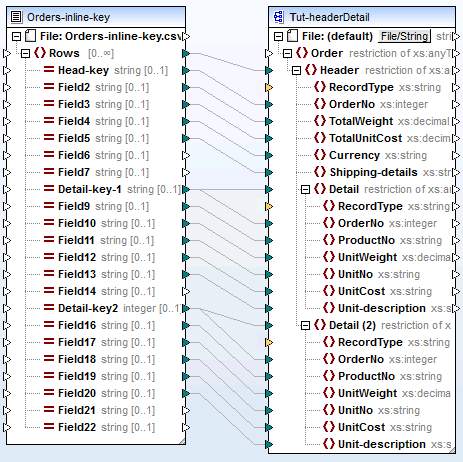
Head-detail-inline.mfd