Documents numérisés (OCR)
L'extracteur PDF de MapForce peut effectuer une reconnaissance optique de caractères (OCR) sur des documents PDF numérisés, vous permettant ainsi d'en extraire le texte. Cette rubrique fournit une présentation de la structure des documents OCR et décrit les objets OCR.
La fonctionnalité OCR de l'extracteur PDF est basée sur Tesseract OCR et est intégrée en tant qu'étape de prétraitement.
Présentation de la structure des documents OCR
L'extracteur PDF traite un document PDF numérisé comme un objet structuré appelé Document, qui est divisé en Pages. Chaque Page contient une ScanArea et des DetectedWords et peut également contenir des UserWords. L'arborescence ci-dessous montre la hiérarchie des objets OCR :
Document
Pages
Page
Mot utilisateur
Zone de numérisation
Mot détecté
Les principales caractéristiques de chaque objet sont décrites ci-dessous :
•Document : contient une liste de pages.
•Page : contient des Mots utilisateurs, Zones de numérisation et des Mots détectés. Par défaut, il existe un objet Page pour chaque page d'un document.
•Zone de numérisation : définit la région numérisée par l'OCR. Par défaut, il existe une zone de numérisation pour chaque page ; la zone de numérisation couvre l'ensemble de la page et est définie sur le mode de segmentation de page Texte fragmenté (voir détails ci-dessous).
•Mot utilisateur : mots saisis manuellement.
•Mot détecté : détecté automatiquement par l'OCR. Si vous modifiez un Mot détecté, il devient un Mot utilisateur. Les Mots détectés peuvent être inclus, exclus ou remplacés par un Mot utilisateur si nécessaire.
Menu contextuel des Mots détectés
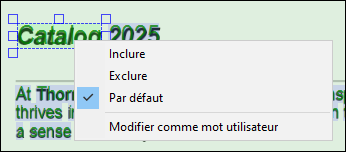
Chaque Mot détecté dispose d'un menu contextuel (capture d'écran ci-dessous) qui vous permet de :
•Inclure ou exclure explicitement le mot détecté. Le processeur OCR peut détecter correctement un mot, mais ne lui attribuer qu'un niveau de confiance de 20 %. Dans ce cas, vous pouvez inclure le mot manuellement. Le processeur peut également détecter un mot de manière incorrecte, auquel cas vous devrez l'exclure.
•Sélectionner l'option par défaut, qui laisse le processeur OCR décider des mots à inclure ou à exclure. Les Mots détectés sont automatiquement inclus si le niveau de confiance est suffisamment élevé (≥ 50 %). Les Mots détectés sont exclus s'ils sont masqués derrière une autre Zone de numérisation.
•Modifier les Mots détectés en tant que Mots utilisateur. Pour modifier un Mot détecté, vous pouvez également double-cliquer dessus dans la zone de numérisation du document PDF.
Propriétés de la Zone de numérisation
L'objet Zone de numérisation possède les propriétés suivantes :
•Langue
•Mode du moteur
•Segmentation de page
•Paramètres
Langue
Spécifie le fichier de données linguistiques utilisé par Tesseract. Cela garantit que le moteur OCR reconnaît les règles alphabétiques et linguistiques correctes (par exemple, l'anglais). Par défaut, PDF Extractor prend en charge les options suivantes :
•deu
•eng
•fra
•jpn
•spa
La plupart des langues qui utilisent l'alphabet latin peuvent être traitées avec succès avec l'option eng. Si la reconnaissance de votre langue n'est pas précise, vous devrez peut-être télécharger un fichier de données linguistiques supplémentaire :
1.Téléchargez le fichier de données linguistiques approprié (par exemple, grc.traineddata) à partir de la page suivante :
https://github.com/tesseract-ocr/tessdata_fast
2.Copiez le fichier de données linguistiques dans le dossier suivant :
C:\ProgramData\Altova\SharedBetweenVersions\TesseractFiles
3.Définissez le paramètre de langue dans le volet Propriétés sur la nouvelle langue (par exemple, grc).
Mode moteur
Définit le moteur de reconnaissance utilisé par Tesseract :
•Par défaut : permet à Tesseract de choisir automatiquement.
•LSTM uniquement (par défaut) : utilise le nouveau moteur basé sur un réseau neuronal. PDF Extractor est installé avec le package LSTM uniquement et prend en charge cinq langues (voir les détails ci-dessus).
•Tesseract uniquement : utilise l'ancien moteur.
•LSTM et Tesseract combinés : exécute les deux moteurs ensemble pour des résultats potentiellement plus fiables.
Si vous souhaitez utiliser l'option Tesseract, procédez comme suit :
1.Effectuez une copie des fichiers Tesseract existants au cas où vous auriez besoin de les restaurer ultérieurement. Les fichiers se trouvent dans le dossier suivant :
C:\ProgramData\Altova\SharedBetweenVersions\TesseractFiles
2.Téléchargez les données d'apprentissage pertinentes pour l'option Tesseract :
https://github.com/tesseract-ocr/tessdata
3.Remplacez les anciens fichiers Tesseract par les nouveaux.
Vous pouvez également placer les fichiers téléchargés dans un nouveau dossier et modifier le chemin d'accès par défaut de TesseractData dans la clé de registre suivante dans l'Éditeur du Registre :
Computer\HKEY_LOCAL_MACHINE\SOFTWARE\Altova\MapForce PDF Extractor\Settings
Segmentation de page
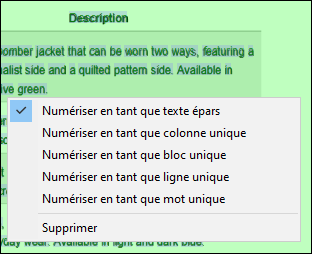
Détermine la manière dont Tesseract interprète la mise en page du texte dans la ScanArea. Les options disponibles sont recensées ci-dessous :
•Par défaut : permet à Tesseract de décider automatiquement.
•Auto : segmentation automatique des pages ; aucune détection de l'orientation ou du script (système d'écriture tel que latin, arabe, etc.).
•Auto avec OSD : segmentation automatique avec détection de l'orientation et du script.
•Bloc unique : traite la zone comme un bloc unique (comme un paragraphe).
•Bloc unique de texte vertical : traite la zone comme un bloc de texte vertical (rarement utilisé en dehors de cas particuliers tels que certains tableaux).
•Colonne unique : considère une colonne de texte de taille variable.
•Ligne unique : considère la zone comme une ligne de texte unique.
•Mot unique : considère la zone comme un mot unique.
•Texte fragmenté (par défaut) : détecte le texte dans des positions arbitraires sans ordre particulier ; utile pour l'OCR pleine page.
•Texte fragmenté avec OSD : identique à ce qui précède, mais détecte également l'orientation et le script.
Le choix du mode de segmentation approprié peut améliorer la précision de la reconnaissance. Par exemple, si une zone ne contient qu'une seule ligne, l'utilisation de la ligne unique produit souvent de meilleurs résultats que le texte fragmenté. Pour les documents généraux, le texte fragmenté est la meilleure option.
Les modes de segmentation de page sont également disponibles via le menu contextuel qui s'ouvre lorsque vous cliquez sur un emplacement vide de la zone de numérisation du document PDF (capture d'écran ci-dessous).
Paramètres
Options que vous pouvez transmettre directement à Tesseract. Ils vous permettent d'ajuster le comportement de l'OCR : Par exemple, vous pouvez limiter la reconnaissance à certains caractères (par exemple, tessedit_char_whitelist=0123456789 pour les chiffres uniquement). Vous pouvez ajouter plusieurs paramètres, chacun sous la forme d'une paire clé-valeur.
Tesseract prend en charge de nombreux paramètres, mais tous ne sont pas forcément utiles pour l'extraction quotidienne de PDF. Voici quelques-uns des paramètres utiles :
•tessedit_zero_rejection – désactive le rejet des caractères incertains.
•tessedit_no_rejects – empêche le rejet de mots, même avec un faible niveau de confiance.
•tessedit_char_blacklist – exclut certains caractères de la reconnaissance.
•tessedit_char_whitelist – limite la reconnaissance à un ensemble donné de caractères.
•tessedit_char_unblacklist – réactive les caractères précédemment mis sur liste noire.
•chs_leading_punct – définit les caractères de ponctuation autorisés au début d'un mot.
•chs_trailing_punct1 – définit les caractères de ponctuation autorisés à la fin d'un mot.
•chs_trailing_punct2 – définit les caractères de ponctuation pouvant apparaître après chs_trailing_punct1.
•numeric_punctuation – spécifie les symboles de ponctuation traités comme faisant partie des chiffres.
Après avoir modifié un paramètre dans le volet Propriétés, cliquez sur Appliquer pour appliquer les modifications.
Liens utiles
Pour plus d'informations sur les différentes options de Tesseract, consultez la référence de classe Tesseract et toutes les options OCR de Tesseract. Pour des informations générales sur Tesseract, veuillez vous reporter au manuel d'utilisation de Tesseract.
Nouvelle Zone de numérisation
Vous pouvez ajouter une nouvelle Zone de numérisation comme suit :
1.Faites glisser un rectangle sur la zone qui vous intéresse.
2.Cliquez avec le bouton droit sur la sélection et choisissez le mode de segmentation de page (décrit ci-dessus).
3.Configurez les propriétés de la nouvelle Zone de numérisation selon vos besoins.
Flux de travail OCR
Pour une description générale des procédures OCR dans PDF Extractor, voir Flux de travail OCR. Pour un exemple étape par étape, voir Tutoriel.