Expressions régulières
Lors de la conception d'un mappage MapForce, vous pouvez utiliser des expressions régulières ("regex") dans les contextes suivants :
•Dans les paramètres pattern des fonctions match-pattern et tokenize-regexp
•Pour filtrer les nœuds dans lesquels une fonction de nœud doit s'appliquer. Pour plus d'informations, voir Appliquer des fonctions de nœud et les défauts par condition.
•Pour séparer du texte basé sur un pattern, lorsque vous créez des modèles MapForce FlexText, voir FlexText et Expressions régulières.
La syntaxe et la sémantique d'expression régulière pour XSLT et XQuery sont tels que définis dans Annexes F de "XML Schema Part 2: Datatypes Second Edition".
Note : Lors de la génération de code C++, C# ou Java, les fonctions avancées de la syntaxe d'expression régulière peuvent différer légèrement. Voir la documentation regex de chaque langage pour plus d'informations.
Terminologie
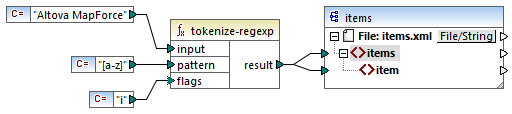
Examinons la terminologie d'expression régulière basique en analysant la fonction tokenize-regexp en tant qu'un exemple. Cette fonction partage du texte dans une séquence de strings, avec l'aide des expressions régulières. Pour ce faire, la fonction prend les paramètres d'entrée suivants :
input | Le string d'entrée à traiter par la fonction. L'expression régulière fonctionnera sur ce string. |
pattern | Le pattern d'expression régulière à appliquer. |
flags | Paramètre optionnel qui définit des options supplémentaires (flags) qui déterminent comment l'expression régulière est interprétée, voir "Flags" ci-dessous. |
Dans le mappage ci-dessous, le string d'entrée est "Altova MapForce". Le paramètre pattern est un caractère d'espace et aucun flag d'expression régulière n'est utilisé.

En conséquence, le texte est partagé à chaque fois que le caractère d'espace se produit, le résultat de mappage est donc le suivant :
<items> |
Veuillez noter que la fonction tokenize-regexp exclut les caractères correspondants du résultat. Autrement dit, le caractère d'espace dans cet exemple est omis de la sortie.
L'exemple ci-dessus est très basique et le même résultat peut être obtenu sans expression régulière, avec la fonction tokenize. Dans un scénario plus pratique, le paramètre pattern contiendrait une expression régulière plus complexe. L'expression régulière peut consister en :
•Littéraux
•Classes de caractère
•Gammes de caractère
•Classe niées
•Caractères Meta
•Quantificateurs
Littéraux
Utiliser des littéraux pour faire correspondre les caractères exactement tels qu'ils sont écrits (littéralement). Par exemple, si le string d'entrée est abracadabra, et pattern est le littéral br, le résultat sera :
<items> |
L'explication est que le littéral br avait deux correspondances dans le string d'entrée abracadabra. Une fois avoir retiré les caractères correspondants du résultat, la séquence de trois strings illustrée ci-dessus est produite.
Classes de caractère
Si vous contenez un ensemble de caractères dans des crochets ([ et ]), cela crée une classe de caractère. Un seul (et uniquement un seul) des caractères contenu dans la classe de caractère a une correspondance, par exemple :
•Le pattern [aeiou] correspond à toute voyelle de casse minuscule.
•Le pattern [mj]ust correspond à "must" et "just".
Note : Le pattern est sensible à la casse, donc un "a" de casse minuscule ne correspond pas à la casse majuscule "A". Pour rendre la correspondance insensible à la casse, utiliser le flag i, voir ci-dessous.
Gammes de caractère
Utiliser [a-z] pour créer une gamme entre les deux caractères. Seul un des caractères trouvera une correspondance un à la fois. Par exemple, le pattern [a-z] correspond à tout caractère de casse minuscule entre "a" et "z".
Classes niées
L'utilisation du caret ( ^ ) en tant que le premier caractère après le crochet ouvert nie la classe de caractère. Par exemple, le pattern [^a-z] correspond à tout caractère ne se trouvant pas dans la classe de caractère, y compris les caractères de nouvelle ligne.
Correspondant à un caractère
Utiliser le méta-caractère du point ( . ) pour faire correspondre chaque caractère unique, sauf pour le caractère de nouvelle ligne. Par exemple, le pattern . correspond à tout caractère unique.
Quantificateurs
Dans le cadre d'une expression régulière, des quantificateurs définissent combien de fois le caractère ou sous-expression précédente est autorisée à se produire pour que la correspondance puisse avoir lieu.
? | Correspond à zéro ou une occurrence de l'item qui précède. Par exemple, le pattern mo? fera se correspondre "m" et "mo". |
+ | Correspond à une ou plusieurs occurrences de l'item qui précède. Par exemple, le pattern mo+ correspondra à "mo", "moo", "mooo", etc. |
* | Correspond à zéro or plusieurs occurrences de l'item qui précède. |
{min,max} | Correspond à n'importe quel nombre d'occurrences entre min et max. Par exemple, le pattern mo{1,3} fait se correspondre "mo", "moo" et "mooo". |
Parenthèses
Les parenthèses ( et ) sont utilisées pour regrouper des parties d'un regex. Elles peuvent être utilisées pour appliquer des quantificateurs dans une sous-expression (contrairement à uniquement un seul caractère), ou avec une alternance (voir ci-dessous).
Alternance
La barre verticale | signifie "ou". Elle peut être utilisée pour faire correspondre n'importe laquelle des différentes sous-expressions séparées par |. Par exemple, le pattern (horse|make) sense fera se correspondre les deux "horse sense" et "make sense".
Flags
Il s'agit de paramètres optionnels qui définissent comme l'expression régulière doit être interprétée. Chaque flag correspond à une lettre. Les lettres peuvent se trouver dans n'importe quel ordre et peuvent être répétées.
s | Si ce flag est présent, le processus de correspondance fonctionne dans le mode "dot-all".
Si le string d'entrée contient "hello" et "world" dans deux lignes différentes, l'expression régulière hello*world correspondra uniquement si le flag s est défini. |
m | Si ce flag est présent, le processus de correspondance fonctionne dans le mode multi-ligne.
Dans le mode multi-ligne, le symbole caret ^ correspond au début d'une ligne, c'est à dire le début du string entier et le premier caractères après un caractère de nouvelle ligne.
Le caractère dollar $ correspond à la fin d'une ligne, c'est à dire la fin du string entier et le caractère juste avant un caractère de nouvelle ligne.
Nouvelle ligne est le caractère #x0A. |
i | Si ce flag est présent, le processus de correspondance fonctionne dans le mode insensible à la casse. Par exemple, l'expression régulière [a-z] plus le flag i font se correspondre toutes les lettres a-z et A-Z.
|
x | Si ce flag est présent, les caractères d'espace blanc sont supprimés de l'expression régulière avant le processus de mise en correspondance. Les caractères d'espace blanc sont #x09, #x0A, #x0D et #x20.
Note: Les caractères d'espace blanc se trouvant dans une classe de caractère ne sont pas supprimés, par exemple, [#x20]. |