오늘날 비즈니스에서 PDF는 널리 사용되는 데이터 형식이지만, PDF에 포함된 데이터는 다른 시스템으로 쉽게 전송하거나 활용하기 어렵습니다. PDF는 일반적으로 사람이 읽기 쉽도록 다양한 형식과 레이아웃으로 디자인되어 있어, 체계적인 데이터 추출이 매우 어렵습니다. PDF는 텍스트, 이미지, 표 등 다양한 요소를 포함할 수 있으며, 데이터는 기계가 읽을 수 있는 형식으로 구성되어 있지 않습니다. 일반적인 PDF 데이터 추출 도구는 특히 복잡한 레이아웃을 가진 PDF의 경우 정확한 결과를 제공하지 못할 수 있습니다. 바로 여기서 MapForce PDF 추출기가 유용하게 활용됩니다.
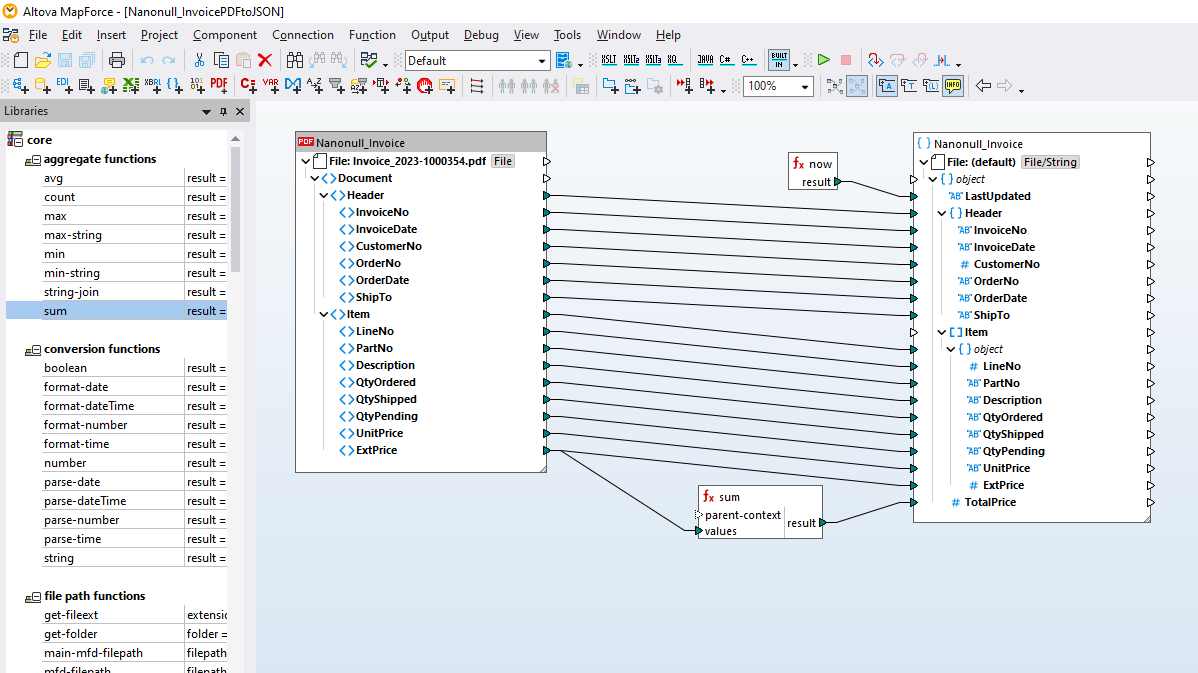
MapForce PDF 추출기는 사용하기 쉬운 유틸리티로, PDF 문서의 구조를 빠르고 쉽게 정의하고, 문서에서 데이터를 추출할 수 있습니다. 추출된 PDF 데이터는 MapForce 내에서 추가적인 변환 및 XML, JSON, 데이터베이스, 엑셀 등 다양한 형식으로의 변환 작업을 수행하는 데 활용될 수 있습니다. 이는 PDF 데이터 통합 및 ETL 프로젝트를 위한 최고의 도구입니다.
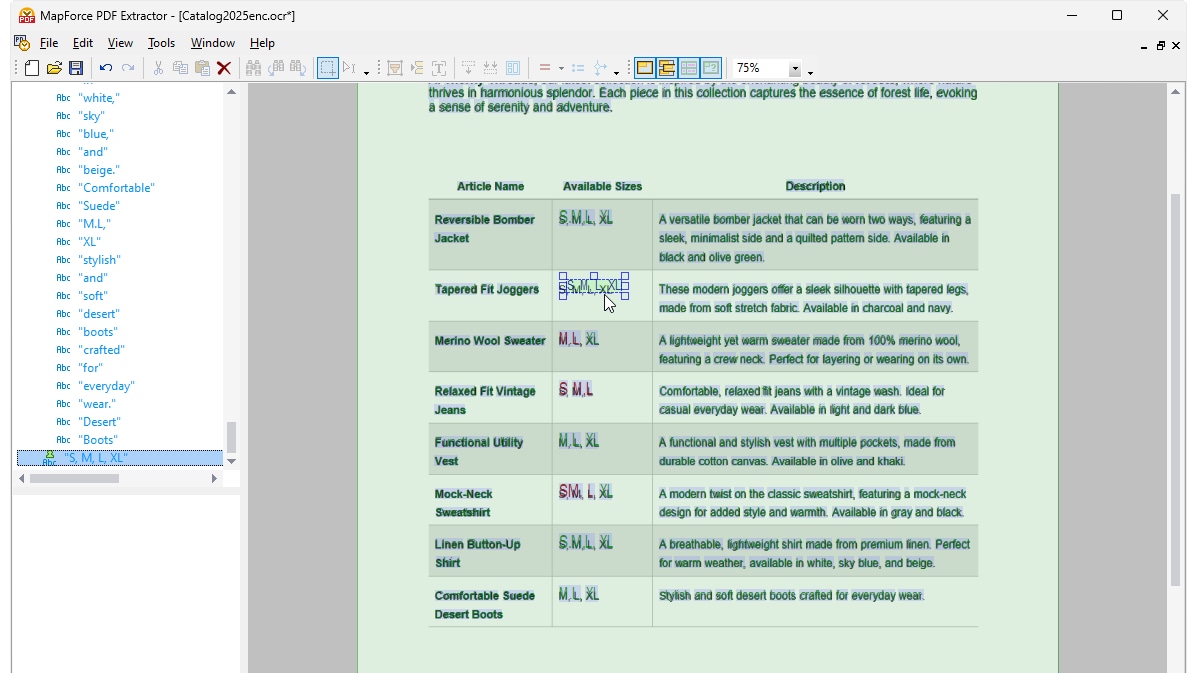
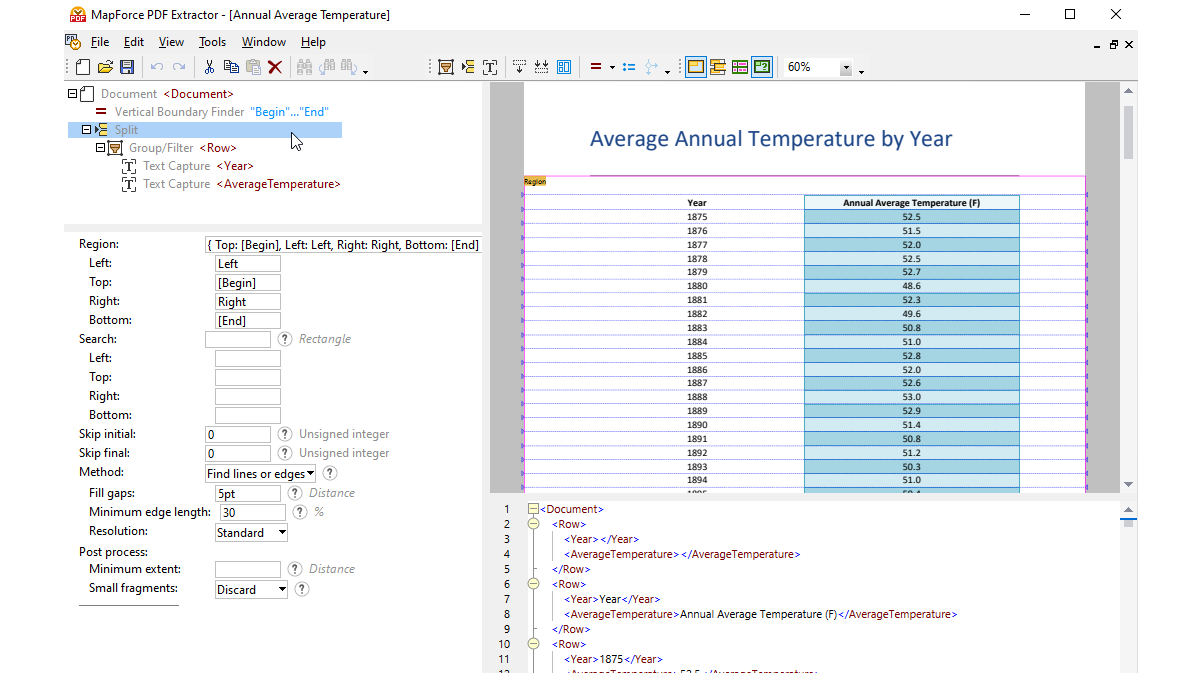
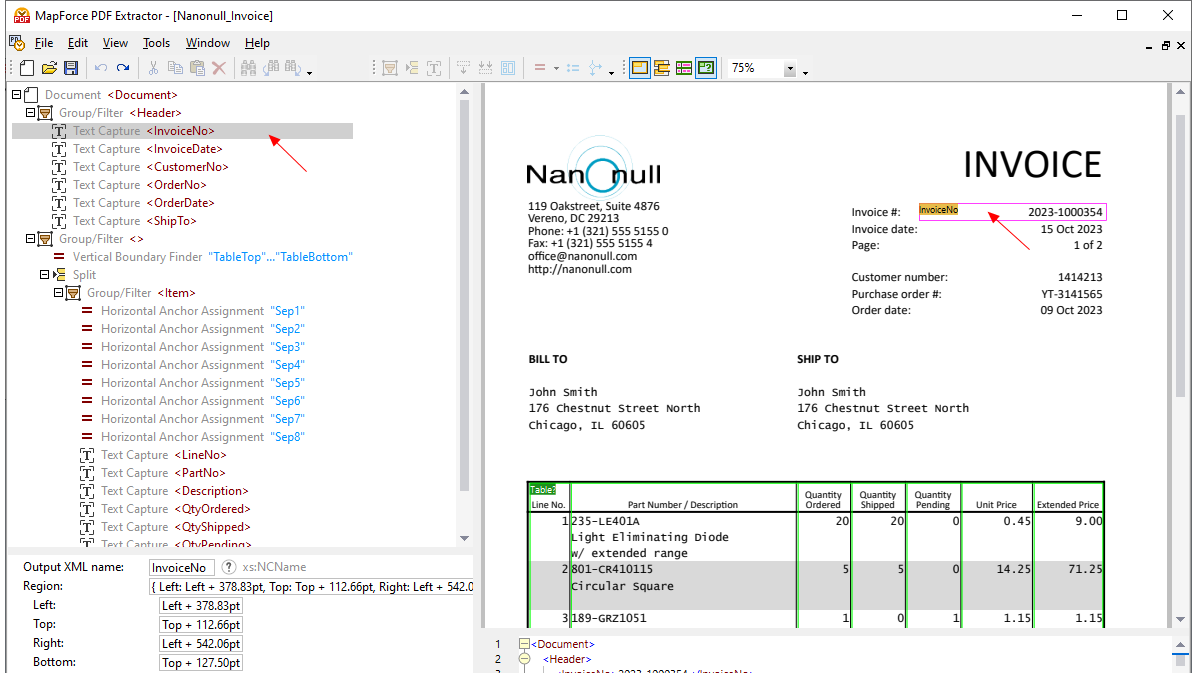
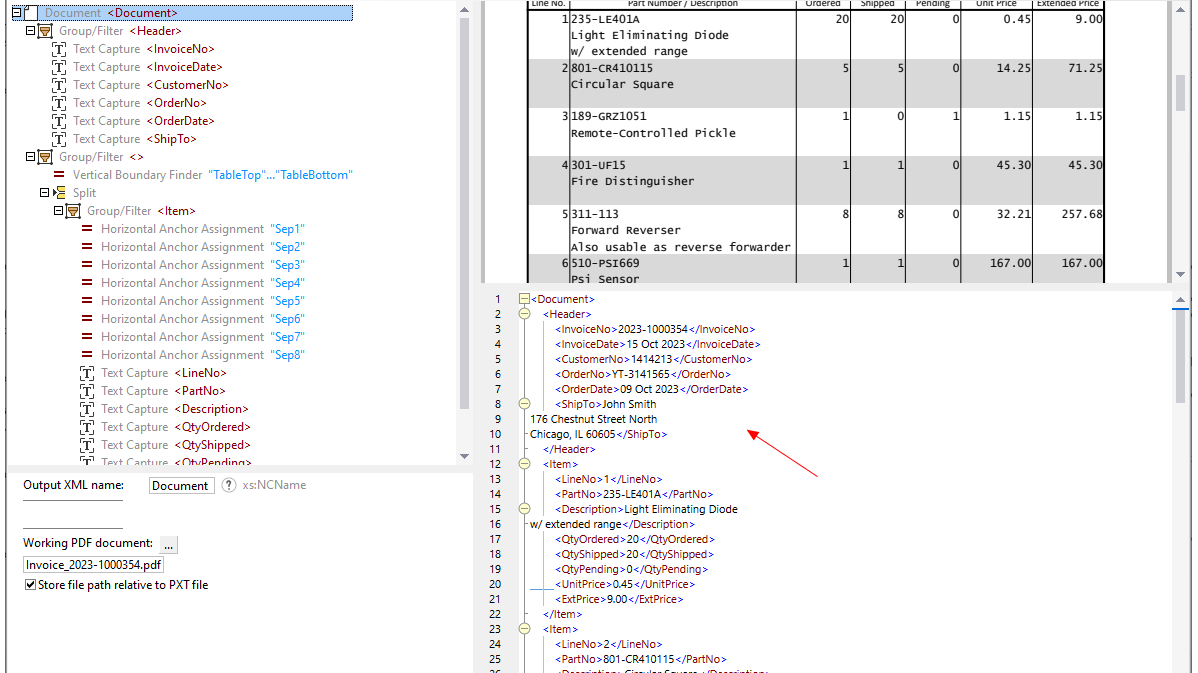
MapForce PDF 추출기를 사용하면 시각적인 도구를 활용하여 PDF 문서의 구조를 정의하고, 효율적으로 데이터를 추출할 수 있습니다. PDF 추출기는 매우 유연한 도구로, 전체 문서가 아닌 특정 부분의 텍스트만 추출하거나, 동일한 PDF 파일의 여러 페이지에서 정보를 조합하고, 표를 행 단위로 분리하거나, 데이터를 그룹으로 정리하는 등의 작업을 수행할 수 있습니다.
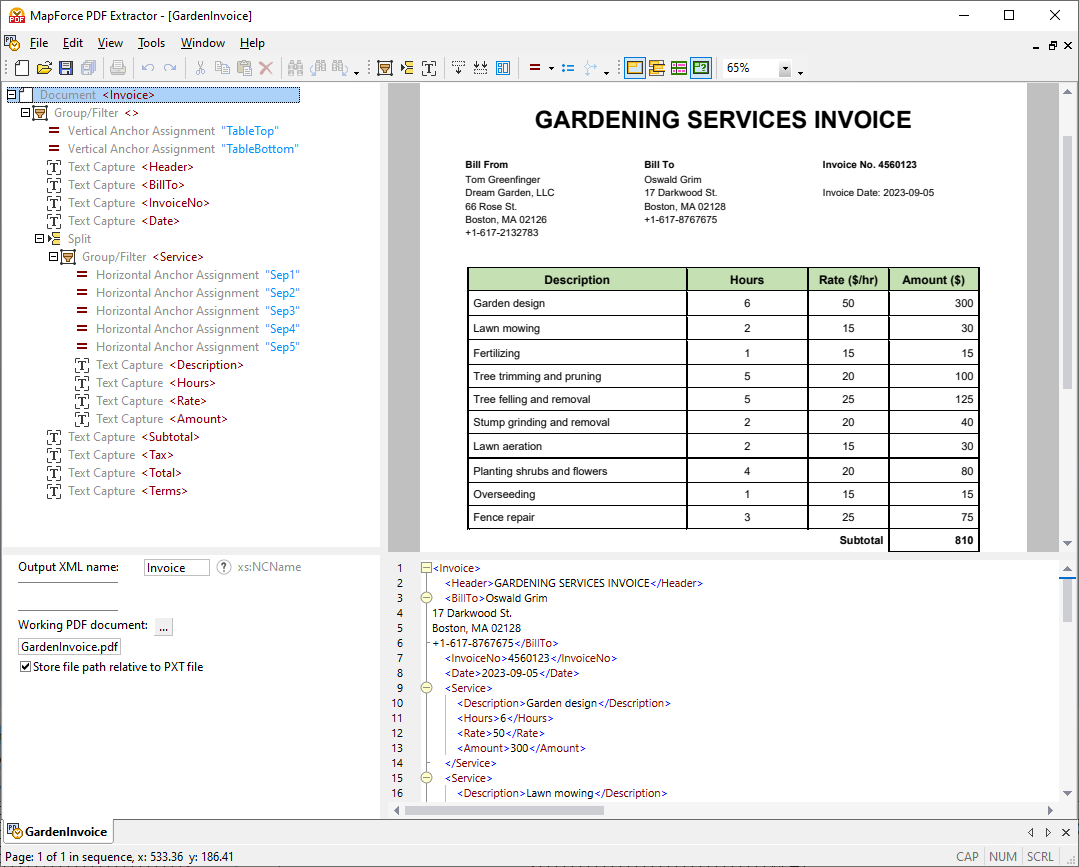
MapForce PDF 추출기는 직관적이고 간편한 디자인을 갖추고 있어, 클릭 및 드래그 앤 드롭 기능을 활용하여 PDF 문서의 구조를 시각적으로 쉽게 정의할 수 있습니다. 이제까지 PDF 파일에 갇혀 있던 방대한 양의 데이터를 다른 형식으로 변환하여 활용할 수 있게 되었습니다.