Exemple : Filtrer avec contexte de priorité
Lorsqu’une fonction est connectée à un filtre, le contexte de priorité n’affecte non seulement la fonction elle-même, mais aussi l’évaluation du filtre. Le mappage ci-dessous illustre un cas typique lorsque vous nécessitez de définir un contexte de priorité pour pouvoir obtenir le résultat correct. Vous trouverez ce mappage sous le chemin suivant : <Documents>\Altova\MapForce2024\MapForceExamples\Tutorial\FilterWithPriority.mfd.
| Note : | Ce mappage utilise des composants XML, mais la même logique que celle décrite ci-dessous s’applique pour tous les autres types de composants dans MapForce, y compris EDI, JSON, etc. Pour les bases de données, il est conseillé d’effectuer des filtres en utilisant des composants SQL WHERE au lieu des filtres standard. |
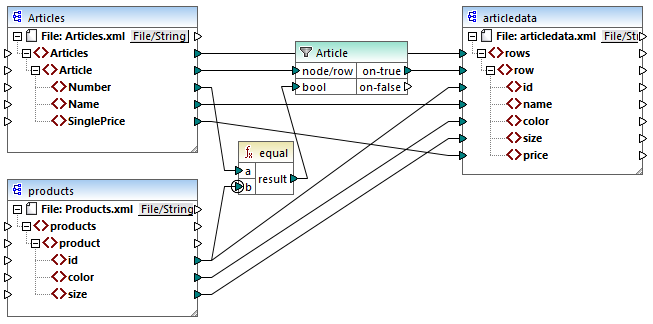
L’objectif du mappage ci-dessus est de copier des données de personnes depuis Articles.xml dans un nouveau fichier XML avec un schéma différent, articledata.xml. Dans le même temps, le mappage doit consulter les détails de chaque article dans le fichier Products.xml et les joindre à l’enregistrement d’article respectif. Veuillez noter que chaque enregistrement dans Articles.xml ait un Number et que chaque enregistrement dans Products.xml ait un id. Si ces deux valeurs sont égales, alors toutes les autres valeurs (Name, SinglePrice, color, size) doivent être copiées dans la même ligne dans la cible.
Cet objectif a été accompli en ajoutant un filtre. Chaque filtre nécessite une condition Booléenne en tant qu’entrée ; seuls les nœud/lignes qui satisfont la condition seront copiés dans la cible. À cet effet, il existe une fonction equal dans le mappage. La fonction equal vérifie si le nombre d’article et l’ID de produit sont égaux dans les deux sources. Le résultat est ensuite fourni en tant qu’entrée dans le filtre. Si true, alors l’item Article est copié dans la cible.
Veuillez noter qu'un contexte de priorité a été défini dans le deuxième paramètres d’entrée de la second fonction equal. Dans ce mappage, le contexte de priorité fait la grande différence, et le fait de ne pas le configurer entraînera un résultat de mappage incorrect.
Mappage initial : Aucun contexte de priorité
Voici la logique de mappage sans contexte de priorité :
•Conformément à la règle de mappage général, pour chaque Article qui satisfait la condition de filtre, une nouvelle row est créée dans la cible. La connexion entre Article et row (par le biais de la fonction et du filtre) se charge de cette partie.
•Le filtre vérifie la condition pour chaque article. Pour ce faire, il itère à travers tous les produits, et apporte plusieurs produits dans le contexte actuel.
•Pour remplir l’id du côté cible, MapForce suit la règle générale (pour chaque item dans la source, crée un item dans la cible). Néanmoins, comme expliqué ci-dessus, tous les produits provenant de Products.xml se trouvent dans le contexte actuel. Il n’y a pas de connexion entre les product vers un autre endroit dans la cible afin de lire l’id d’un produit spécifique uniquement. En conséquence, plusieurs éléments id seront créés pour chaque Article dans la cible. La même chose se produit avec color et size.
Pour résumer : des items provenant de Products.xml possèdent le contexte du filtre (qui doit itérer à travers chaque produit) ; c’est pourquoi, les valeurs id, color et size seront copiées dans chaque cible row autant de fois qu’il y a des produits dans le fichier source, et généreront un résultat incorrect comme celui ci-dessous :
<rows> |
Solution A : Utiliser le contexte de priorité
Le problème ci-dessus a été résolu en ajoutant un contexte de priorité dans la fonction qui calcule la condition Booléenne du filtre.
En particulier, si le second paramètres d’entrée de la fonction equal est désigné en tant que contexte de priorité, la séquence provenant de Products.xml est mis en priorité. Cela se traduit par la logique de mappage suivante :
•Pour chaque produit, remplir l’entrée b de la fonction equal (en d’autres termes, mettre la priorité sur b). À ce niveau, les détails du produit actuel se trouvent dans le contexte.
•Pour chaque article, remplir l’entrée a de la fonction equal et vérifier si la condition de filtre est vraie. Si oui, placer les détails de l’article également dans le contexte actuel.
•Ensuite, copier les détails de l’article et du produit depuis le contexte actuel dans les items respectifs dans la cible.
La logique de mappage ci-dessus produit le résultat correct, par exemple :
<rows> |
Solution B : Utiliser une variable
En tant qu'une solution alternative, vous pouvez apporter chaque article et produit qui correspond la condition du filtre dans le même contexte avec l’aide d’une variable intermédiaire. Les variables sont pertinentes pour des scénarios comme celui-ci parce qu’elles vous permettent de stocker des données temporairement dans le mappage, et vous aident donc à modifier le contexte selon vos besoins.
Pour des scénarios comme celui-ci, vous pouvez ajouter au mappage une variable qui a le même schéma que le composant de cible. Dans le menu Insertion, cliquer sur Variable, et fournir le schéma articledata.xsd en tant que structure lorsque vous y êtes invité.
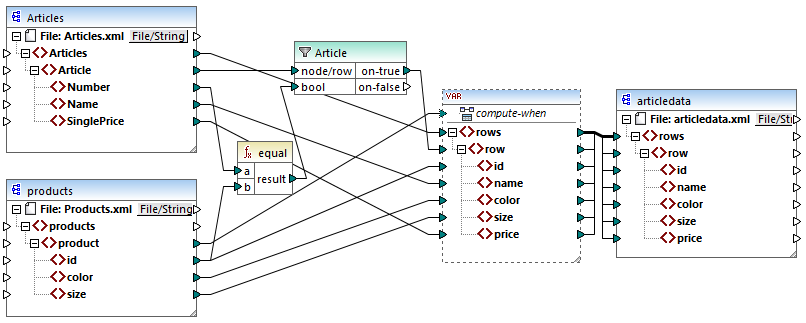
Dans le mappage ci-dessus, les choses suivantes se produisent :
•Le contexte de priorité n’est plus utilisé. À la place de cela il y a une variable, qui a la même structure que le composant de cible.
•Comme d’habitude, l’exécution de mappage commence à partir du nœud racine de cible. Avant de remplir la cible, le mappage collectionne des données dans la variable.
•La variable est calculée dans le contexte de chaque produit. Cela se produit parce qu’il y a une connexion provenant de product vers l’entrée compute-when de la variable.
•La condition de filtre est donc vérifiée dans le contexte de chaque produit. Il faut que la condition soit vraie, la structure de la variable sera remplie et transmise vers la cible.