Fuente y destino de combinación
Los objetos Fuente de combinación y Destino de combinación están relacionados. Una fuente de combinación le permite extraer un fragmento de la página actual. Puede crear varias fuentes de combinación y unirlas en un único destino de combinación que identifica todos los fragmentos recopilados de distintas páginas como un único grupo de páginas. El destino de combinación procesa los fragmentos en el orden en que se han agregado.
El uso conjunto de objetos Fuente de combinación y Destino de combinación resulta beneficioso cuando los datos están bien organizados y delimitados en una página. Sin embargo, cuando en el documento hay, por ejemplo, una fila que empieza en una página y termina en la siguiente, es más recomendable usar el objeto Collage.
Para más información sobre cómo agregar objetos a la estructura jerárquica, consulte el apartado Insertar un objeto.
Propiedades en el panel Propiedades
Para el objeto Fuente de combinación se pueden configurar dos propiedades en el panel Propiedades: Región y Destino de combinación. La propiedad Región se refiere a la ubicación de una fuente de combinación en la página. Para más detalles, consulte la propiedad Región en el objeto División. La propiedad Destino de combinación indica el nombre del objeto Destino de combinación que reunirá las Fuentes de combinación relevantes en un grupo.
Tenga en cuenta que los valores del parámetro Destino de combinación de todas las fuentes de combinación que quiere unir en el mismo destino de combinación, así como el nombre de la fuente de combinación correspondiente (la propiedad Nombre) deben ser los mismos. De lo contrario, el destino de combinación no podrá unir estas fuentes de combinación.
Ejemplo
Este ejemplo ilustra cómo usar los objetos Fuente de combinación y Destino de combinación. El documento PDF del cual pretendemos extraer datos se llama BookCatalog.pdf. El documento contiene dos páginas (imagen siguiente) con diseños que no son del todo iguales. Por una parte, la página 1 contiene un encabezado, una tabla y un pie de página. Por otra parte, en la página 2, la tabla continúa y también hay un pie de página. La plantilla de extracción mencionada en este ejemplo se encuentra en la siguiente carpeta: MapForceExamples\BookCatalog.pxt.
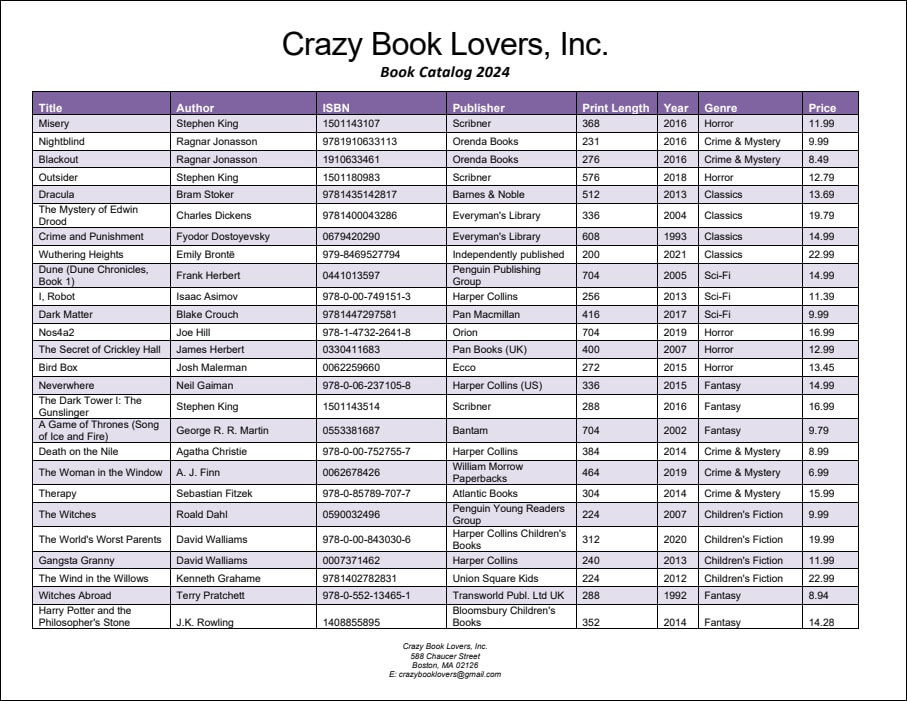
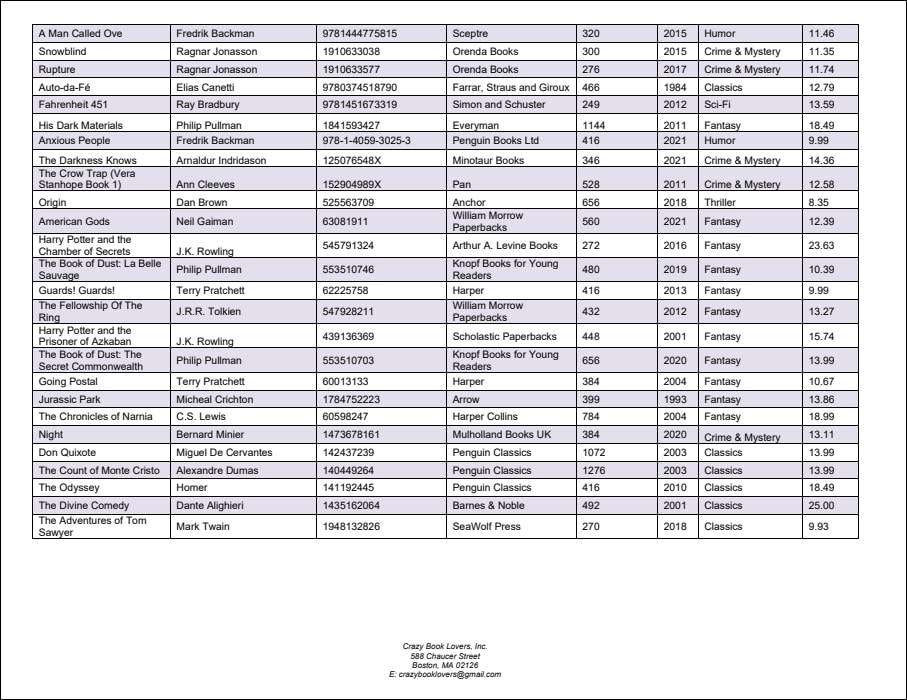
Objetivos
Los objetivos de este ejemplo son:
•Extraer el nombre de la empresa
•Extraer todos los datos de la tabla de ambas páginas
•Excluir el pie de página y el encabezado del procesamiento
Implementación
Para alcanzar estos objetivos, hemos creado la siguiente estructura jerárquica:
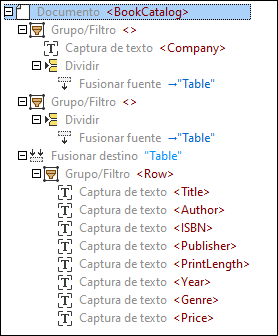
Bajo el elemento raíz llamado BookCatalog, hay un objeto Grupo/Filtro que procesa sólo los objetos de la primera página del documento PDF, dado que la propiedad Seleccionar grupos está configurada en 1. El objeto Grupo/Filtro incluye dos Capturas de texto como nodos secundarios: Company, que se refiere al nombre de la empresa en la parte superior del documento PDF, y CatalogYear (imágenes siguientes).


Este objeto Grupo/Filtro también contiene una Fuente de combinación como nodo secundario cuya región comprende todas las filas de la primera página excepto el encabezado. Hemos definido la región manualmente (en vez de usar sugerencias de tabla automáticas). A continuación, se puede ver un extracto de la región de la primera Fuente de combinación.

El segundo objeto Grupo/Filtro procesa la segunda página del documento PDF (Seleccionar grupos configurado en 2) y también incluye una Fuente de combinación. La razón para crear dos grupos separados es que los diseños de las páginas no son los mismos. Por lo tanto no podemos aplicar la misma lógica de procesamiento a estas páginas.
El objeto Destino de combinación reúne los fragmentos de ambas Fuentes de combinación en un grupo. Para que el Destino de combinación pueda coleccionar las Fuentes de combinación relevantes correctamente, las fuentes y destinos de combinación correspondientes deben tener el mismo nombre (Table en nuestro ejemplo). Una vez que se hayan recogido todos los fragmentos, se agrupan en filas (el objeto Grupo/Filtro con Capturas de Texto). Cada fila contiene información sobre un libro, su autor, el ISBN, la casa editorial, la extensión de la impresión, el año, el género y el precio. El objeto Grupo/Filtro está envuelto en el objeto División y muestra el resultado de la división del Destino de Fusión en diferentes filas de datos.
Resultados
Ya está completa la definición de las reglas de extracción. El panel Resultados muestra la estructura que hemos definido y los datos que hemos decidido extraer del documento PDF. El siguiente extracto de código muestra una parte de los resultados.
<BookCatalog>
<Company>Crazy Book Lovers, Inc.</Company>
<CatalogYear>2024</CatalogYear>
<Book>
<Title>Dune (Dune Chronicles, Book 1)</Title>
<Author>Frank Herbert</Author>
<ISBN>0441013597</ISBN>
<Publisher>Penguin Publishing Group</Publisher>
<PrintLength>704</PrintLength>
<Year>2005</Year>
<Genre>Sci-Fi</Genre>
<Price>14.99</Price>
</Book>
<Book>
<Title>Dark Matter</Title>
<Author>Blake Crouch</Author>
<ISBN>9781447297581</ISBN>
<Publisher>Pan Macmillan</Publisher>
<PrintLength>416</PrintLength>
<Year>2017</Year>
<Genre>Sci-Fi</Genre>
<Price>9.99</Price>
</Book>
<Book>
<Title>Nos4a2</Title>
<Author>Joe Hill</Author>
<ISBN>978-1-4732-2641-8</ISBN>
<Publisher>Orion</Publisher>
<PrintLength>704</PrintLength>
<Year>2019</Year>
<Genre>Horror</Genre>
<Price>16.99</Price>
</Book>
<...>
</BookCatalog>