Documentos escaneados (OCR)
MapForce PDF Extractor puede aplicar el reconocimiento óptico de caracteres (OCR) en documentos PDF escaneados, lo que le permite extraer texto de ellos. Este tema ofrece una descripción general de la estructura de documentos OCR y describe los objetos OCR.
La funcionalidad OCR de PDF Extractor se basa en Tesseract OCR y está integrada como paso previo al procesamiento.
Descripción general de la estructura del documento OCR
PDF Extractor trata un documento PDF escaneado como un objeto estructurado denominado Documento, que se divide en Páginas. Cada página contiene un área de escaneo y palabras detectadas, y también puede contener palabras del usuario. El árbol de modelos que aparece a continuación muestra la jerarquía de los objetos OCR:
Documento
Páginas
Página
Palabra del usuario
Área de escaneo
Palabra detectada
A continuación describimos las características de cada objeto:
•Documento: contiene una lista de páginas.
•Página: contiene palabras del usuario, áreas de escaneo y palabras detectadas. De forma predeterminada, hay un objeto Página por cada página de un documento.
•Área de escaneo: define la región escaneada por el OCR. De forma predeterminada, hay un ScanArea por cada págin. El área de escaneo cubre toda la página y está configurada en el modo de segmentación de página Texto disperso (ver detalles a continuación).
•Palabra del usuario: palabras introducidas a mano.
•Palabra detectada: detectada automática por el OCR. Si edita una palabra detectada, se convierte en una palabra del usuario. Las palabras detectadas se pueden incluir, excluir o sustituir por una palabra del usuario si es necesario.
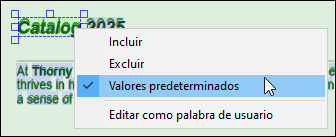
Menú contextual de Palabra detectada
Cada objeto Palabra detectada tiene un menú contextual (imagen siguiente) que le permite:
•Incluir o excluir explícitamente la palabra detectada. El procesador OCR puede detectar correctamente una palabra, pero asignarle solo un 20 % de confianza, en cuyo caso es posible que desee incluir la palabra manualmente. El procesador también podría detectar incorrectamente una palabra, que tal vez deba excluir.
•Seleccione la opción predeterminada, que permite al procesador OCR decidir qué incluir o excluir. Las palabras detectadas se incluyen automáticamente si el nivel de confianza es lo suficientemente alto (≥ 50 %). Las palabras detectadas se excluyen si están ocultas detrás de otra área de escaneo.
•Editar palabras detectadas como palabras del usuario. Para editar una palabra detectada, también puede hacer doble clic sobre ella en el área de escaneo del documento PDF.
Propiedades de Área de escaneo
El objeto Área de escaneo tiene estas propiedades:
•Idioma
•Modo del motor
•Segmentación de páginas
•Parámetros
Idioma
Especifica el archivo de datos de idioma utilizado por Tesseract. Esto garantiza que el motor OCR reconozca el alfabeto y las reglas lingüísticas correctas (por ejemplo, inglés). De forma predeterminada, PDF Extractor admite las siguientes opciones:
•deu
•eng
•fra
•jpn
•spa
La mayoría de los idiomas que utilizan el alfabeto latino se pueden procesar correctamente con la opción eng. Si el reconocimiento de su idioma no es preciso, es posible que tenga que descargar un archivo de datos de idioma adicional:
1.Descargue el archivo de datos del idioma correspondiente (por ejemplo, grc.traineddata) de la siguiente página:
https://github.com/tesseract-ocr/tessdata_fast
2.Copie el archivo de datos de idioma en la siguiente carpeta:
C:\ProgramData\Altova\SharedBetweenVersions\TesseractFiles
3.Configure el parámetro de idioma en el panel Propiedades con el nuevo idioma (por ejemplo, grc).
Modo del motor
Define qué motor de reconocimiento utiliza Tesseract:
•Predet.: permite a Tesseract elegir el motor automáticamente.
•Solo LSTM (predeterminado): utiliza el nuevo motor basado en redes neuronales. PDF Extractor se instala con el paquete exclusivo para LSTM y admite cinco idiomas (ver detalles más arriba).
•Solo Tesseract: utiliza el motor heredado anterior.
•LSTM y Tesseract combinados: funciona con ambos motores a la vez para obtener resultados potencialmente más fiables.
Si desea utilizar la opción Tesseract, siga los pasos que se indican a continuación:
1.Haga una copia de los archivos Tesseract existentes por si necesita restaurarlos más adelante. Los archivos están en esta carpeta:
C:\ProgramData\Altova\SharedBetweenVersions\TesseractFiles
2.Descargue los datos de entrenamiento pertinentes para la opción Tesseract:
https://github.com/tesseract-ocr/tessdata
3.Reemplace los archivos antiguos de Tesseract por los nuevos.
También puede colocar los archivos descargados en una nueva carpeta y editar la ruta predeterminada de TesseractData en la siguiente clave del registro en Editor del Registro:
Computer\HKEY_LOCAL_MACHINE\SOFTWARE\Altova\MapForce PDF Extractor\Settings
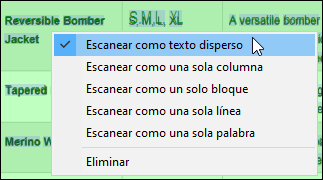
Segmentación de páginas
Determina cómo Tesseract interpreta el diseño del texto en el área de escaneo. A continuación mostramos las opción disponibles.
•Predeterminada: permite a Tesseract decidir automáticamente.
•Automática: Segmentación automática de páginas; sin detección de orientación ni escritura (sistema de escritura como latín, árabe, etc.).
•Automática con OSD: segmentación automática con detección de orientación y escritura.
•Un solo bloque: trata el área como un solo bloque (como un párrafo).
•Un solo bloque de texto vertical: trata el área como un bloque de texto vertical (rara vez se utiliza excepto en casos especiales, como ciertas tablas).
•Una sola columna: supone una columna de texto de tamaño variable.
•Una sola línea: supone que el área es una sola línea de texto.
•Una sola palabra: supone que el área es una palabra.
•Texto disperso (predet.): detecta texto en posiciones aleatorias sin un orden concreto; útil para el OCR de páginas completas.
•Texto disperso con OSD: Igual que la opción anterior, pero también detecta la orientación y el tipo de escritura.
Elegir el modo de segmentación adecuado puede mejorar la precisión del reconocimiento. Por ejemplo, si un área contiene solo una línea, la opción Una sola línea suele producir mejores resultados que Texto disperso. Para documentos generales, Texto disperso es la mejor opción.
Los modos de segmentación de páginas también están disponibles a través del menú contextual que se abre al hacer clic en un espacio en blanco del área de escaneo del documento PDF (imagen siguiente).
Parámetros
Opciones que puede pasar directamente a Tesseract. Le permiten ajustar el comportamiento del OCR: Por ejemplo, puede restringir el reconocimiento a determinados caracteres (por ejemplo, tessedit_char_whitelist=0123456789 solo para dígitos). Puede agregar varios parámetros, cada uno como un par clave-valor.
Tesseract admite muchos parámetros, pero es posible que no todos ellos sean útiles para las tareas cotidianas de extracción de PDF. Estos son algunos parámetros:
•tessedit_zero_rejection – deshabilita el rechazo de caracteres inciertos.
•tessedit_no_rejects – evita que se rechacen palabras, incluso con un nivel de confianza bajo.
•tessedit_char_blacklist – excluye caracteres específicos del reconocimiento.
•tessedit_char_whitelist – restringe el reconocimiento a un conjunto determinado de caracteres.
•tessedit_char_unblacklist – vuelve a habilitar los caracteres que estaban en la lista de caracteres excluidos.
•chs_leading_punct – define los caracteres de puntuación permitidos al principio de una palabra.
•chs_trailing_punct1 – define los caracteres de puntuación permitidos al final de una palabra.
•chs_trailing_punct2 – define los caracteres de puntuación que pueden aparecer después de chs_trailing_punct1.
•numeric_punctuation – especifica los símbolos de puntuación que se tratan como parte de los números.
Después de modificar una configuración en el panel Propiedades, haga clic en Aplicar para aplicar los cambios.
Enlaces prácticos
Para obtener más información sobre las distintas opciones de Tesseract, consulte la Referencia de clases de Tesseract y Todas las opciones OCR de Tesseract. Para obtener información general sobre Tesseract, consulte el Manual del usuario de Tesseract.
Nueva área de escaneo
Para añadir una nueva área de escaneo:
1.Dibuje un rectángulo sobre el área de interés.
2.Haga clic con el botón derecho del ratón en la selección y elija el modo de segmentación de páginas (descrito anteriormente).
3.Configure las propiedades de la nueva área de escaneo según sea necesario.
Flujo de trabajo OCR
Para leer una descripción general de los procedimientos de OCR en PDF Extractor, consulte Flujo de trabajo OCR. Para ver un ejemplo paso a paso, consulte el tutorial