Tutorial
Este tutorial ofrece un ejemplo paso a paso de cómo aplicar el OCR a un documento PDF escaneado. Los archivos de muestra están disponibles en la siguiente ruta:
C:\Users\<Usuario>\Documentos\Altova\MapForce<YEAR>\MapForceExamples\Tutorial\OCR
Archivo de origen: documento PDF escaneado
Nuestro archivo de origen es un documento PDF escaneado de una página, que se llama Catalog2025.pdf (imagen siguiente).
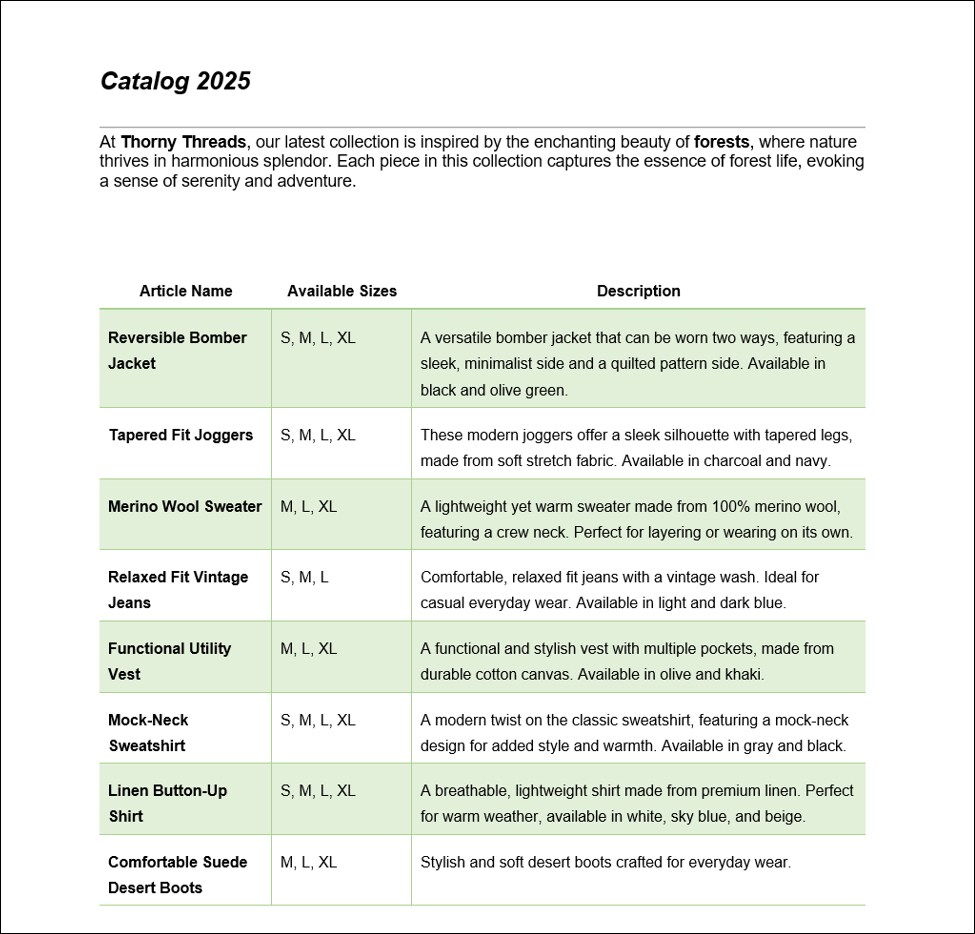
Paso 1: Crear una plantilla PXT y cargar el documento PDF
Llegados a este punto, hemos creado un archivo PXT e importado nuestro documento PDF escaneado (ver también Flujo de trabajo OCR).
Paso 2: Revisar palabras detectadas
Cuando el documento ocr.pdf recién creado se abre en una ventana nueva, el OCR se aplica al documento automáticamente. Los resultados del OCR aparecen en la estructura de objetos (imagen siguiente). También pueden aparecer en el área de escaneo del documento si se activa el comando Mostrar superposiciones de la barra de herramientas.
En nuestro ejemplo, hemos habilitado los comandos Mostrar superposiciones y Mostrar todas las superposiciones. Las palabras resaltadas en verde se incluyen en la estructura de palabras detectadas. Las palabras que aparecen en rojo se han excluido porque es posible que el nivel de confianza del OCR estuviera por debajo del umbral.
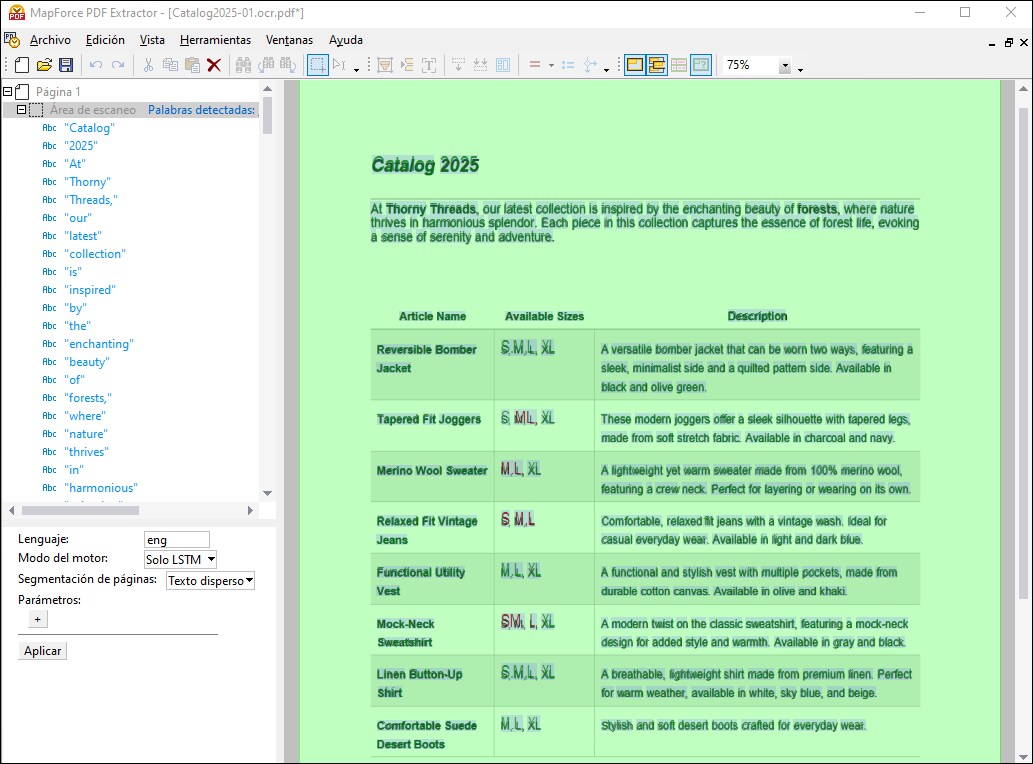
En general, el procesador OCR ha detectado correctamente la mayor parte del texto, salvo algunas tallas. En este tutorial, mostramos uno de los posibles métodos para corregir los resultados. Por ejemplo, en la celda que contiene información sobre las tallas del artículo Tapered Fit Joggers, se han identificado dos palabras (S y XL) y se ha excluido una palabra detectada (ML). Para corregir estos resultados, proceda de la siguiente manera:
1.Haga clic en ML en el panel Vista PDF y elimine esta palabra. Haga lo mismo con XL.
2.Haga doble clic en S y edite el texto para incluir otras tallas: S, M, L, XL. Cuando haya terminado de editar, haga clic en Intro. Las palabras editadas aparecen ahora como palabras del usuario en la parte inferior de la estructura de objetos. Tenga en cuenta que el cuadro de texto editado puede solaparse con otras palabras detectadas (imagen siguiente). Si esto ocurre, es posible que la extracción de texto no funcione correctamente.
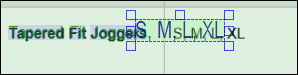
3.Coloque el cuadro de texto de manera que se corresponda lo más posible con el texto original, tal y como se muestra a continuación. Esto garantiza que el texto se extraiga correctamente.

4.Repita los mismos pasos para otras tallas que no se hayan detectado correctamente.
Paso 3: Guarde la plantilla OCR y defina la plantilla PXT.
Una vez que haya terminado de editar las palabras detectadas, guarde la plantilla OCR y vuelva a la ventana PXT. Ahora, el objetivo principal es crear una plantilla que le permita extraer el texto detectado por el procesador OCR. Siga las instrucciones a continuación.
1.Asegúrese de que el comando Mostrar sugerencias de la barra de herramientas esté activado.
2.Utilice la primera sugerencia de tabla automática para crear una estructura de tabla en el panel Esquema.

Como resultado, se ha creado la siguiente estructura de objetos:
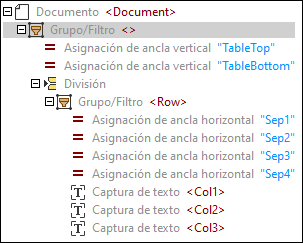
3.Dado que hemos utilizado la sugerencia de tabla que solo contenía una fila, debemos desplazar hacia abajo TableBottom para incluir todas las filas de la tabla. Para ello, haga clic en la asignación de ancla vertical TableBottom en la estructura, haga clic en la etiqueta TableBottom en el panel Vista PDF y arrastre la línea hacia abajo.
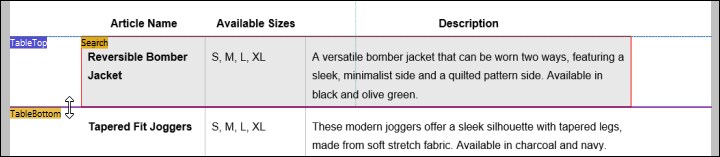
Al cambiar TableBottom, se actualizan los resultados en el panel Resultados y se incluyen todos los datos de la tabla.
4.Asigne nombres con sentido a los objetos de la estructura, tal y como se muestra a continuación. Al cambiar los nombres de los objetos también se actualizan los elementos XML en el panel Resultados.
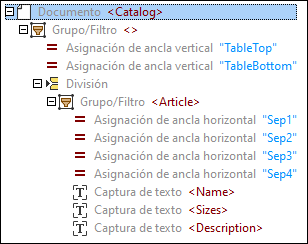
5.Cree capturas de texto para el año del catálogo y la descripción como se muestra a continuación.

Resultados
La plantilla ha extraído correctamente los datos OCR de nuestro documento PDF escaneado. El resultado aparece en el panel Resultados:
<Catalog> <Year>2025</Year> <Info>At Thorny Threads, our latest collection is inspired by the enchanting beauty of forests, where nature thrives in harmonious splendor. Each piece in this collection captures the essence of forest life, evoking a sense of serenity and adventure.</Info> <Article> <Name>Reversible Bomber Jacket</Name> <Sizes>S, M, L, XL</Sizes> <Description>A versatile bomber jacket that can be worn two ways, featuring a sleek, minimalist side and a quilted pattern side. Available in black and olive green.</Description> </Article> <Article> <Name>Tapered Fit Joggers</Name> <Sizes>S, M, L, XL</Sizes> <Description>These modern joggers offer a sleek silhouette with tapered legs, made from soft stretch fabric. Available in charcoal and navy.</Description> </Article> <Article> <Name>Merino Wool Sweater</Name> <Sizes>M, L, XL</Sizes> <Description>A lightweight yet warm sweater made from 100% merino wool, featuring a crew neck. Perfect for layering or wearing on its own.</Description> </Article> <Article> <Name>Relaxed Fit Vintage Jeans</Name> <Sizes>S, M, L</Sizes> <Description>Comfortable, relaxed fit jeans with a vintage wash. Ideal for casual everyday wear. Available in light and dark blue.</Description> </Article> <...> </Catalog> |
Si observa algún problema con los datos extraídos en el panel Resultados, puede ajustar la plantilla OCR, guardarla y volver a comprobar los resultados en la ventana PXT.
Siguientes pasos
La definición de la plantilla de extracción de PDF está terminada. El siguiente paso sería importar la plantilla a MapForce y crear una asignación para procesar los datos extraídos del PDF.