Leer y escribir documentos XML (C++)
Tras generarse el código a partir del esquema de ejemplo se crea una aplicación de prueba C++ junto con varias bibliotecas Altova secundarias.
Información sobre las bibliotecas C++ generadas
La clase central del código generado es la clase CDoc, que representa el documento XML. Dicha clase se genera por cada esquema y su nombre depende del nombre del archivo de esquema. Como puede verse en el diagrama, esta clase aporta métodos para cargar documentos desde archivos, secuencias binarias o cadenas de texto (o para guardar documentos en archivos, secuencias y cadenas). Para ver una descripción de los miembros que expone esta clase consulte la referencia de la clase ([SuEsquema]::[CDoc]).
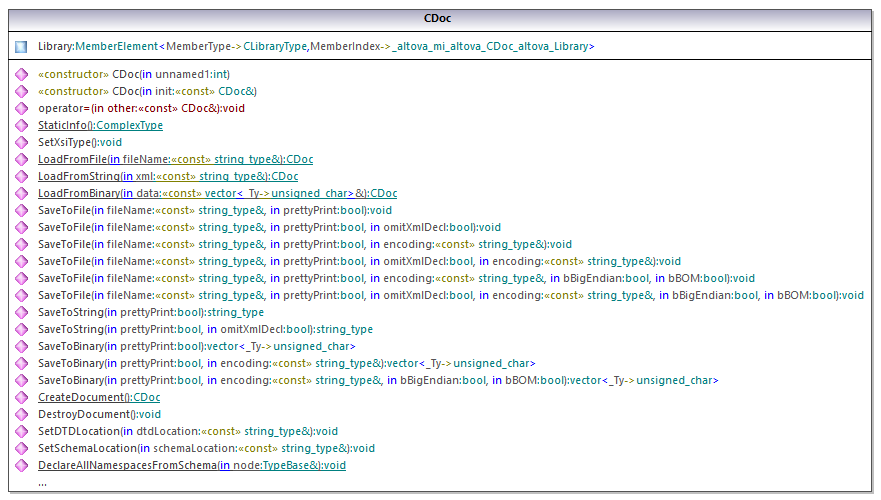
El campo Library de la clase CDoc representa la raíz real del documento. Library es un elemento del archivo XML, de modo que en el código C++ tiene una clase plantilla como tipo (MemberElement). La clase plantilla expone métodos y propiedades para interactuar con el elemento Library. En general, cada atributo y cada elemento de un tipo del esquema recibe un tipo en el código generado con las clases plantilla MemberAttribute y MemberElement respectivamente. Para más información consulte la referencia de las clases [SuEsquema]::AtributoMiembro y [SuEsquema]::ElementoMiembro.
La clase CLibraryType se genera a partir del tipo complejo LibraryType del esquema. Observe que la clase CLibraryType contiene los campos Book y LastUpdated. Según la lógica mencionada previamente, estos campos corresponden al elemento Book y al atributo LastUpdated del esquema y permiten manipular elementos y atributos del documento XML de instancia mediante programación (operaciones anexar, eliminar, etc.).
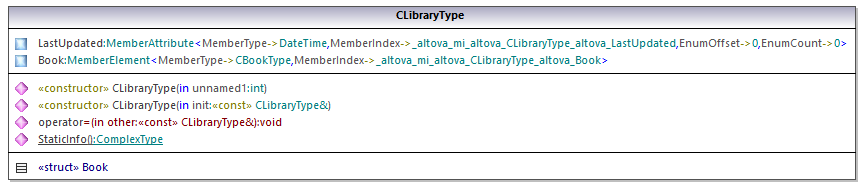
Como DictionaryType es un tipo complejo derivado de BookType esta relación también se refleja en las clases generadas. Como puede verse en el diagrama, la clase CDictionaryType hereda la clase CBookType.
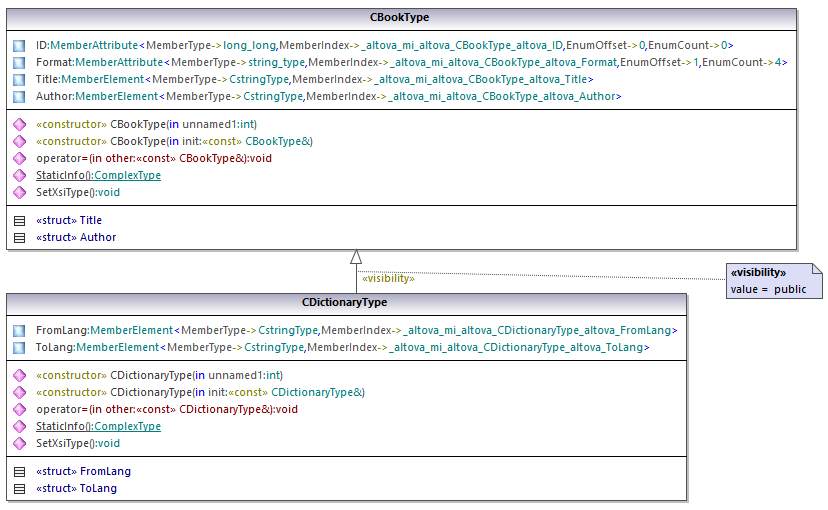
Si su esquema XML define tipos simples como enumeraciones, los valores enumerados están disponibles como valores enum en el código generado. En el esquema utilizado en este ejemplo, el formato de los libros puede ser tapa dura, bolsillo, libro electrónico y audiolibro. Por tanto, en el código generado estos valores estarán disponibles a través de un enum que es miembro de la clase CBookFormatType.
Escribir un documento XML
1.En Visual Studio abra la solución LibraryTest.sln que se generó a partir del esquema Library mencionado anteriormente.
Cuando cree prototipos de aplicaciones a partir de esquemas XML que cambien con frecuencia, a veces será necesario generar código una y otra vez en el mismo directorio para que los cambios en el esquema se reflejen inmediatamente en el código. Recuerde que la aplicación de prueba que se genera y las bibliotecas de Altova se sobrescribirán cada vez que genere código en el mismo directorio de destino. Por tanto, recuerde que no debe añadir código a la aplicación de prueba que se genera, sino que debe integrar las bibliotecas de Altova en el proyecto (ver Integrar bibliotecas contenedoras de esquemas). |
2.En el explorador de soluciones abra el archivo LibraryTest.cpp y edite el método Example() como se indica a continuación:
#include <ctime> // obligatorio para obtener hora actual |
3.Pulse F5 para iniciar la depuración. Si el código se ejecuta correctamente, el archivo GeneratedLibrary.xml se crea en el directorio de salida de la solución.
Leer un documento XML
1.Abra la solución LibraryTest.sln en Visual Studio.
2.Guarde el código que aparece a continuación como Library1.xml en un directorio que el código de programa pueda leer (p. ej. en el mismo directorio que LibraryTest.sln).
<?xml version="1.0" encoding="utf-8"?> |
3.En el explorador de soluciones abra el archivo LibraryTest.cpp y edite el método Example() como se indica a continuación.
using namespace Doc; |
4.Pulse F5 para iniciar la depuración.