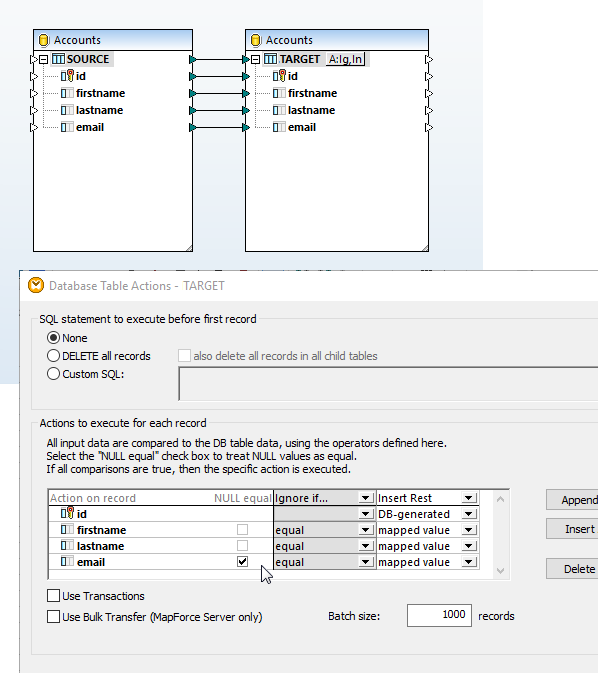
A common application for MapForce is migrating data between MySQL and PostgreSQL databases. MapForce makes this easy with graphical, drag-and-drop data mapping tools including a rich library of filters and data processing functions to transform source data.
The Database Connection Wizard in MapForce makes it easy to connect. SQLite connections are supported as native, direct connections to the SQLite database file. No separate drivers are required. PostgreSQL connections are supported both as native connections and driver-based connections through interfaces (drivers) such as ODBC or JDBC. Native connections do not require any drivers.
When you load the MySQL and PostgreSQL database structures in the mapping pane, MapForce automatically interprets the database schemas, lets you pick available database tables and views, and recognizes table relationships.
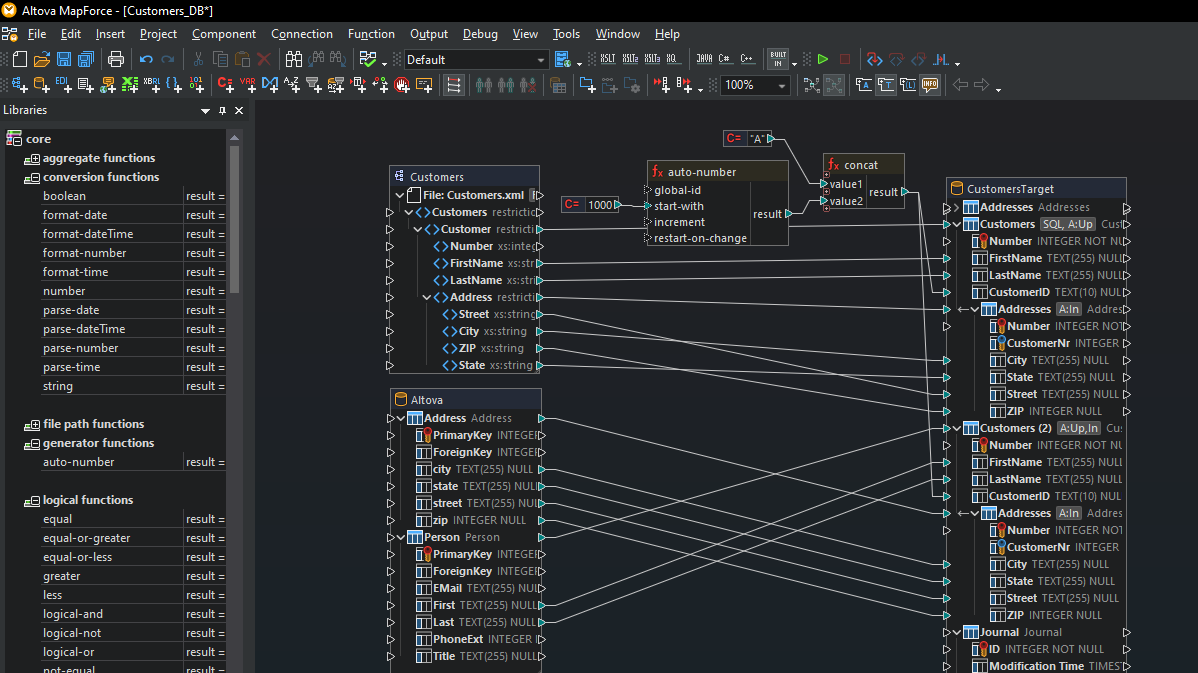
Once you have loaded all of the content models required for your database mapping, complete the mapping by simply dragging connecting lines between the source and target structures.
Using the no-code MapForce approach, it's easy to meet common data transformation requirements, for example:
- Convert PostgreSQL to MySQL
- Migrate from PostgreSQL to MySQL
- Export PostgreSQL to MySQL
- Convert MySQL to PostgreSQL
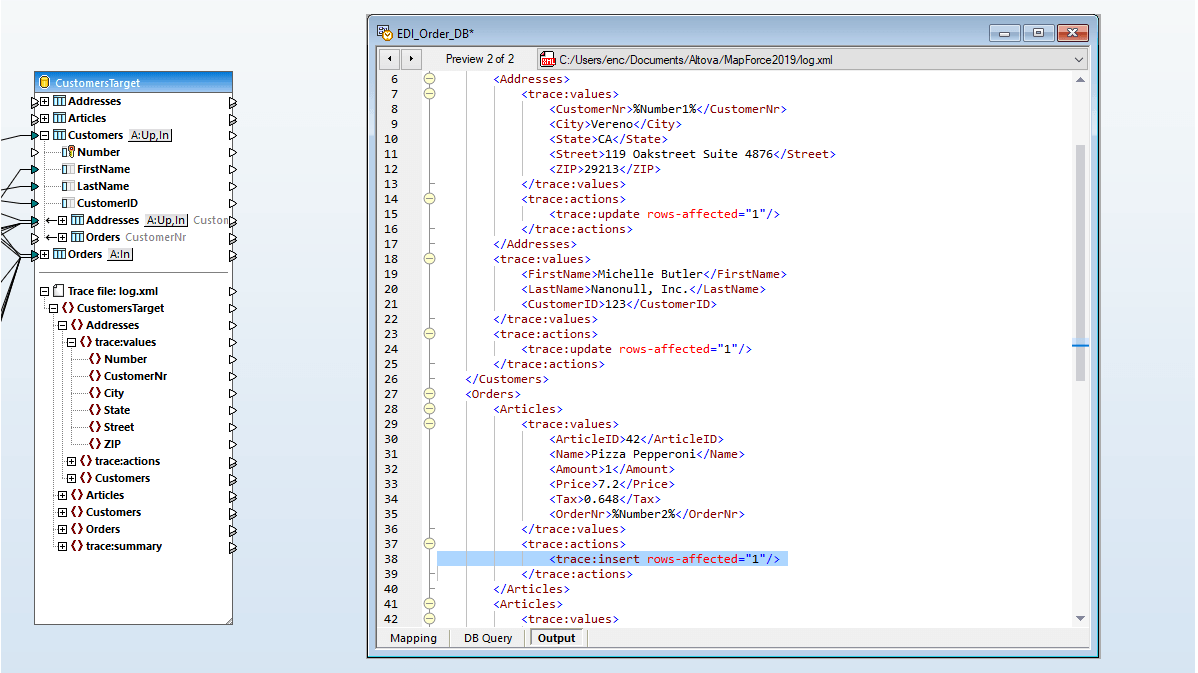
Many database mappings require tran sformation of data between the source and target based on Boolean conditions or SQL and SQL/XML statements. You may need to perform logical comparisons, mathematical computations, or string operations, check for database data of a particular value, and make other modifications to the data. In screenshot above, data processing functions appear as the boxes between the lines joining the source and the target data model.
Data processing functions enable you perform advanced database mappings on-the-fly for a multitude of real-world transformation requirements.
Once your mapping is defined, the built-in MapForce Engine allows you to view and save the results with one click.
Your MySQL to PostgreSQL mapping will produce output in the form of SQL scripts (e.g., SELECT, INSERT, UPDATE, and DELETE statements) that are run against your target database directly from within MapForce.
After previewing the output, you'll have the option to automate the data transformation process via MapForce Server.