ETL (Extract-Transform-Load) tools provide a mechanism for extracting data from external sources, transforming it to a normalized data format, and then loading it into an end target or repository.
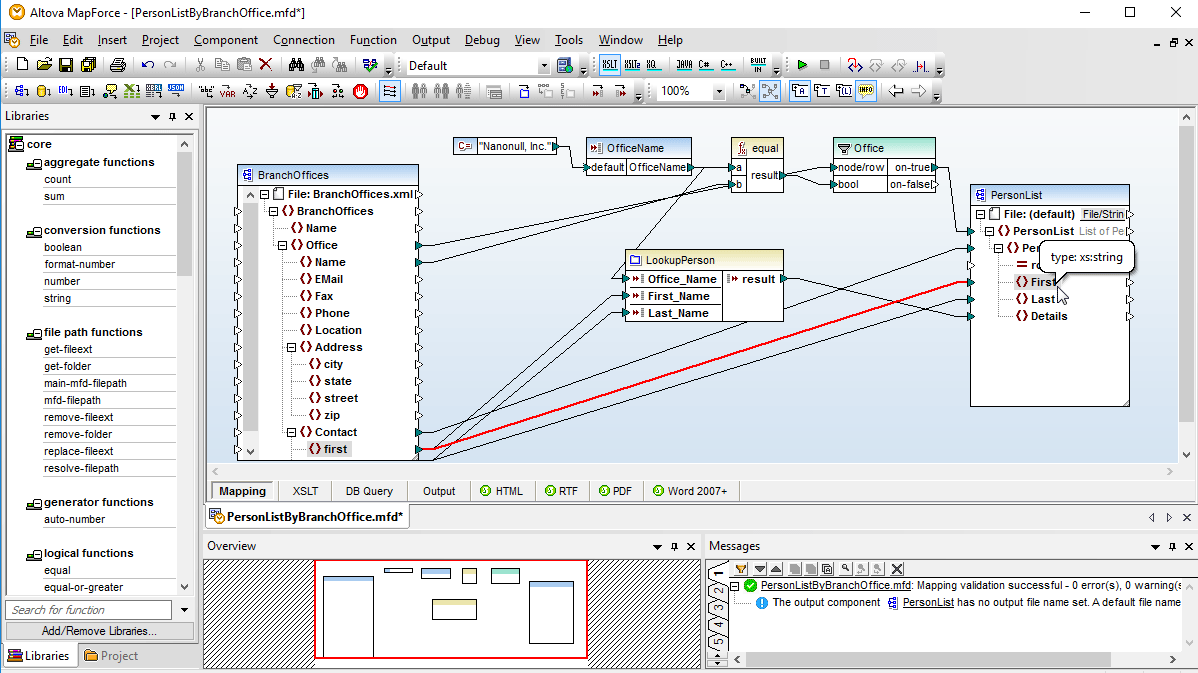
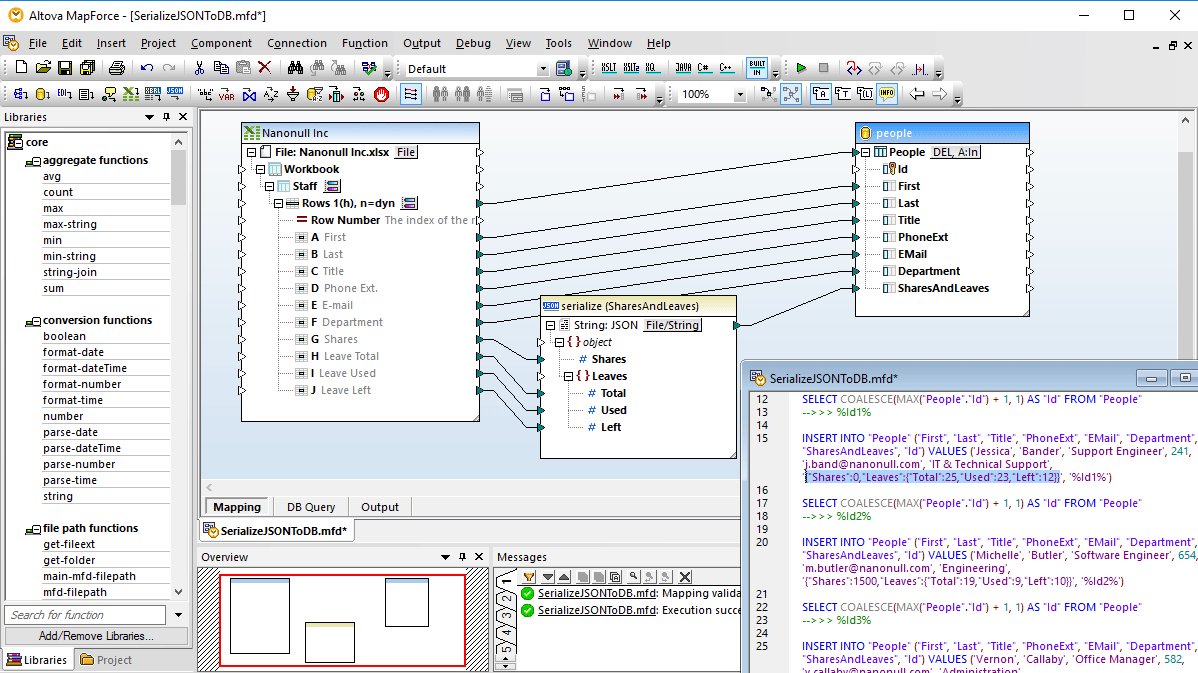
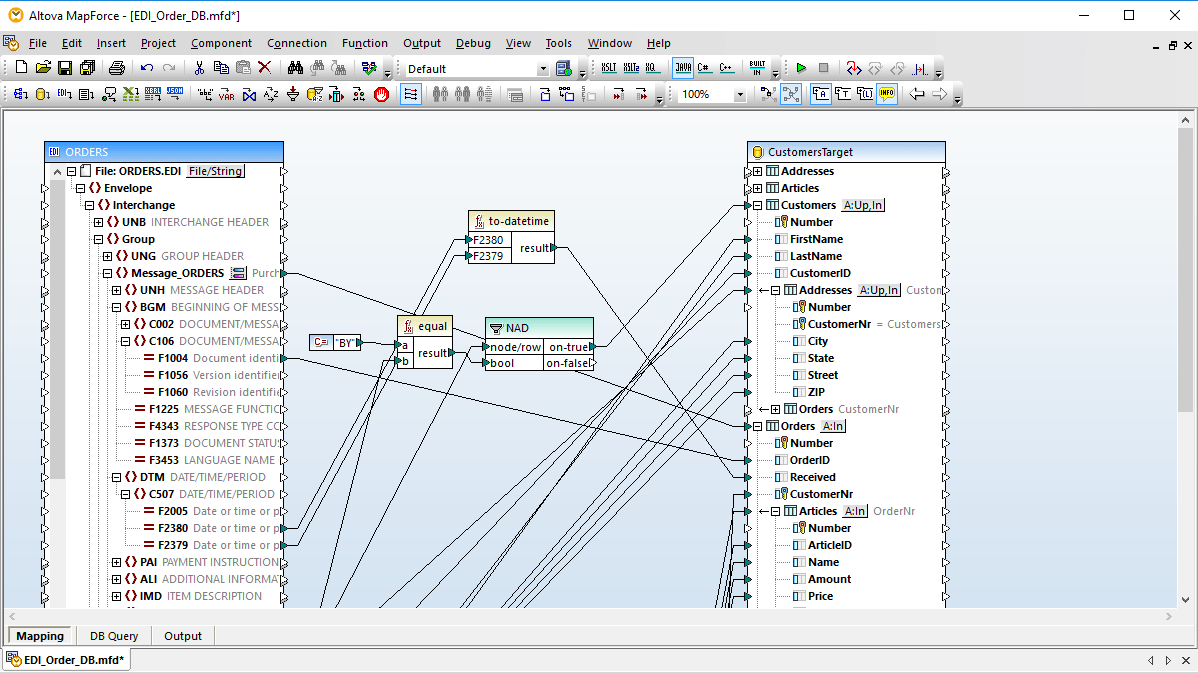
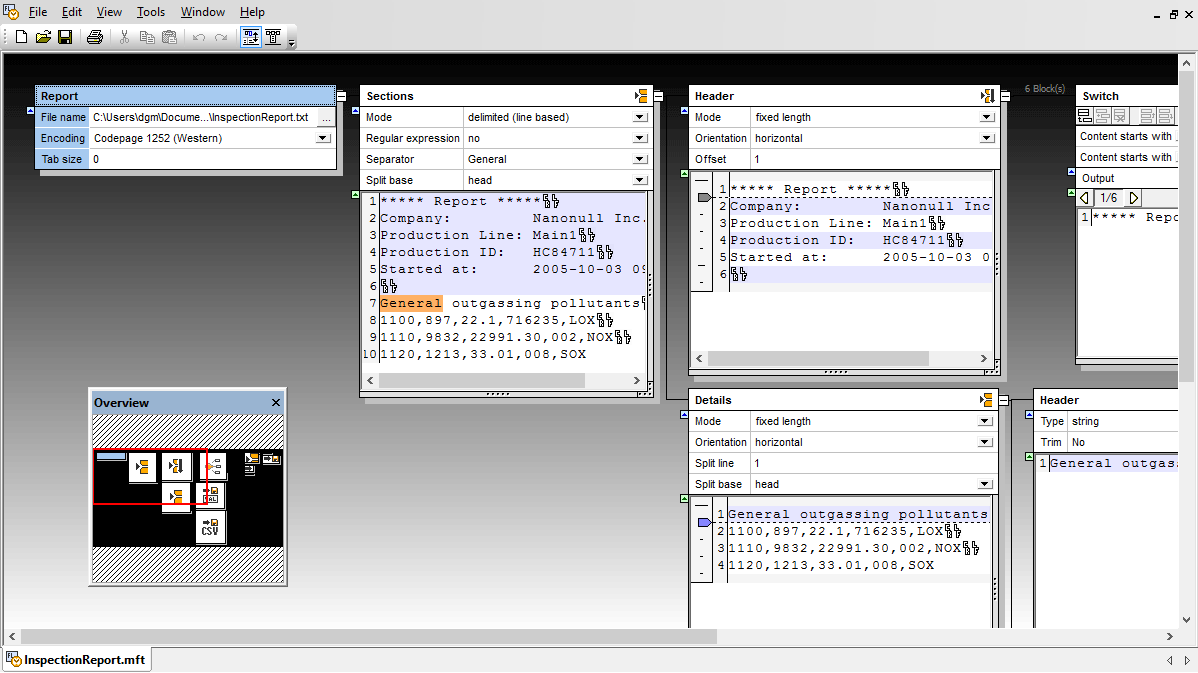
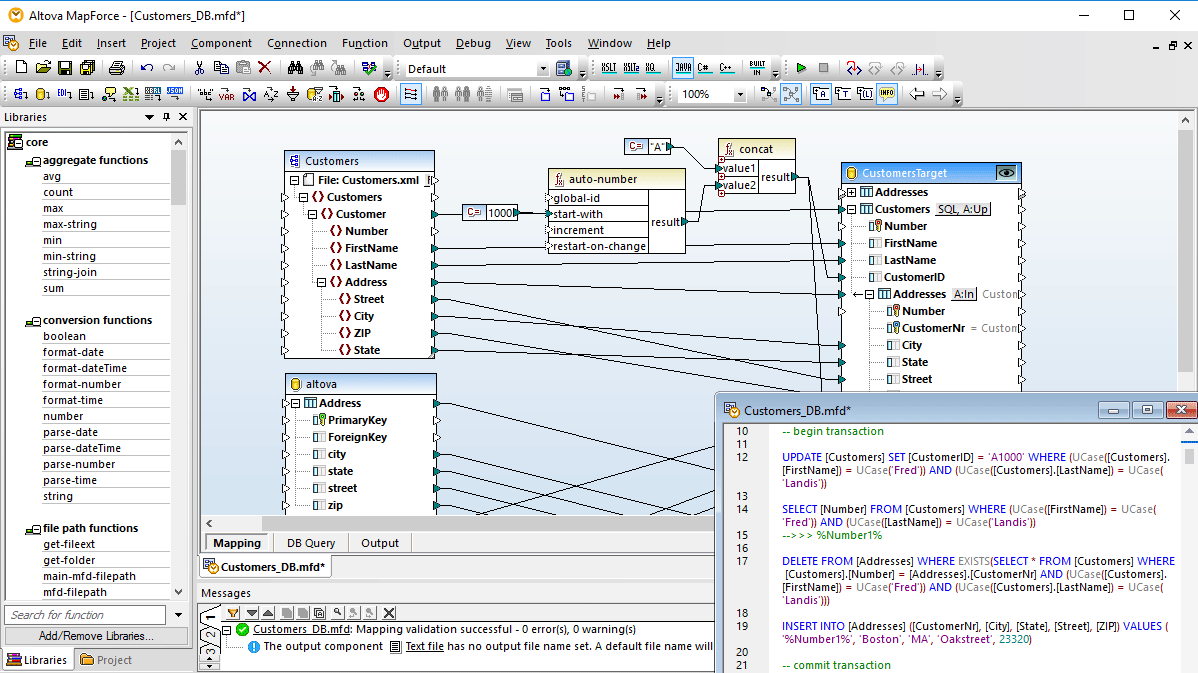
With support for prevalent enterprise data formats (XML, JSON, PDF, databases, flat files, EDI, Protobuf, Shopify/GraphQL, etc.), MapForce is an extremely effective, lightweight, and scalable ETL tool. MapForce offers a straightforward, visual ETL mapping interface that lets you easily load any supported structures and then use drag and drop functionality to connect nodes and add data transformation functions and filters, or use the visual function builder for more complex ETL projects.
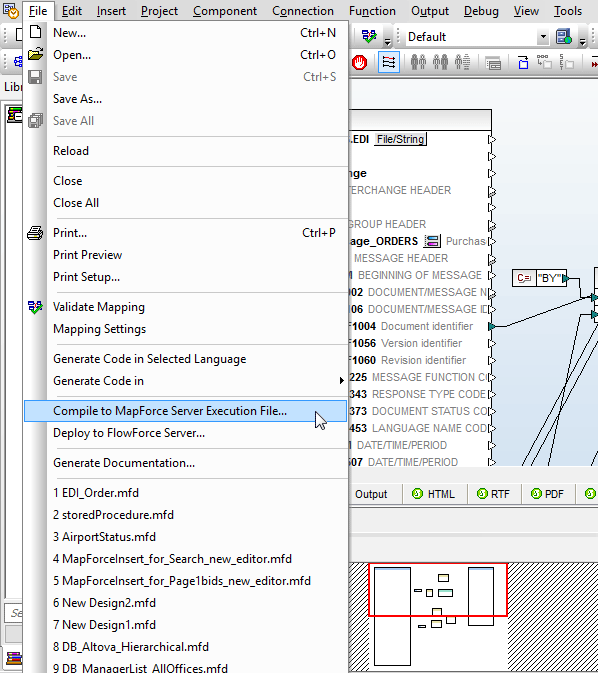
To complement its visual interface, MapForce ETL tools can be seamlessly automated via the high-performance MapForce Server.
MapForce allows you to easily associate data structures using drag and drop ETL data mapping functionality.
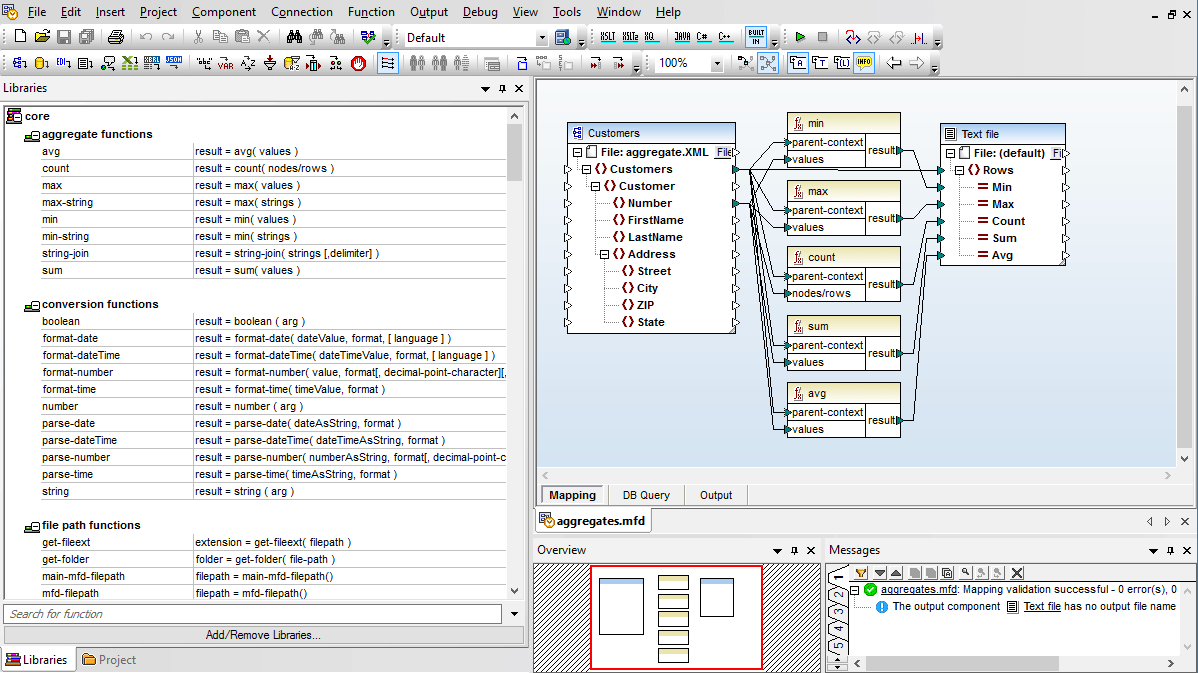
Advanced data processing filters and functions can be added via a built-in function library, and you can use the visual function builder to combine multiple inline and/or recursive operations in more complex ETL or data integration projects, and even save functions for use in other mapping projects.
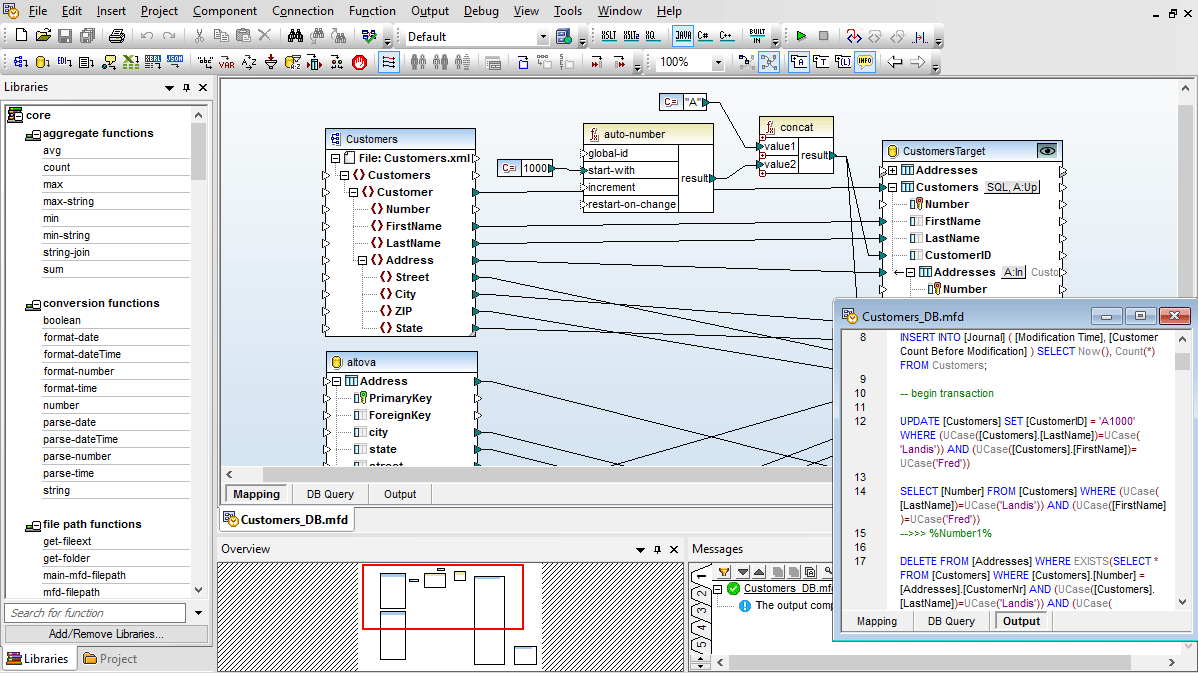
MapForce also supports advanced ETL scenarios involving multiple input and output schemas, multiple source and/or target files, or advanced multi-pass data transformations.
Support for data streaming gives your ETL projects a huge performance boost with the ability to stream input from arbitrarily large XML, CSV, and FLF files and relational databases, and stream output to equally large XML, CSV, and FLF files or insert it into a database.
This built-in functionality means that MapForce can easily process massive data sets and ETL projects, limited only by the amount of disk space available on your local machine or accessible on a network.
In order to activate this feature, simply select the BUILTIN icon from the toolbar in the MapForce design pane.
With support for bulk database insert as well as direct data streaming, MapForce Server is also ideally suited for execution of ETL data mappings.