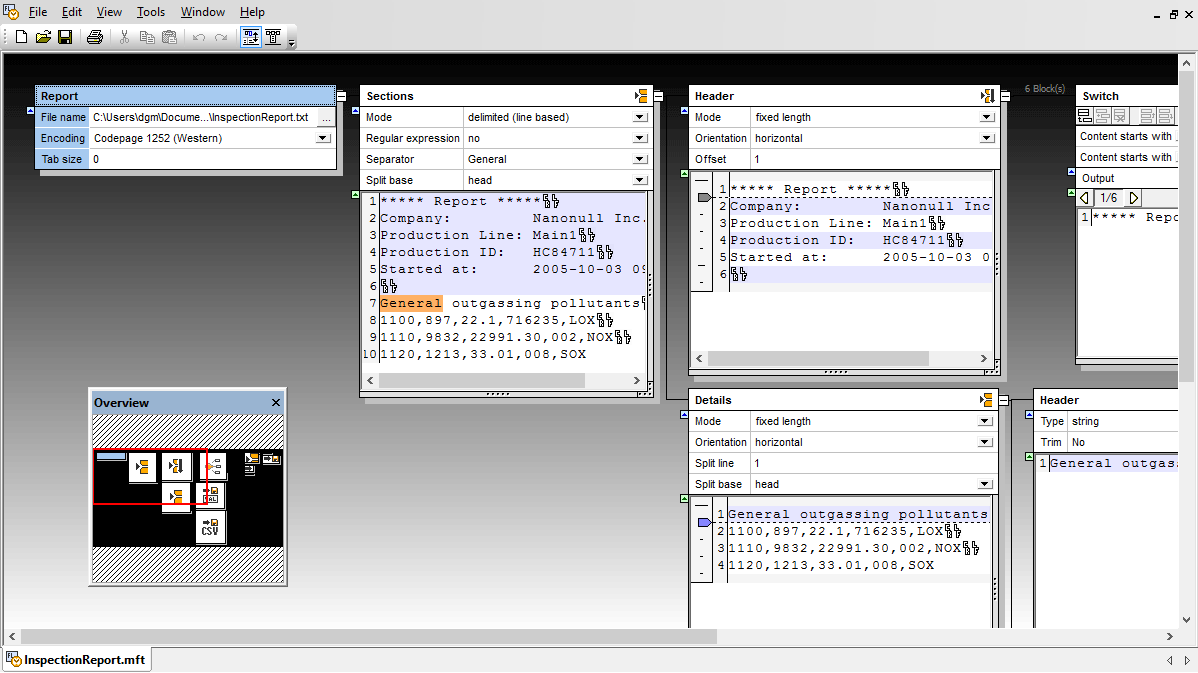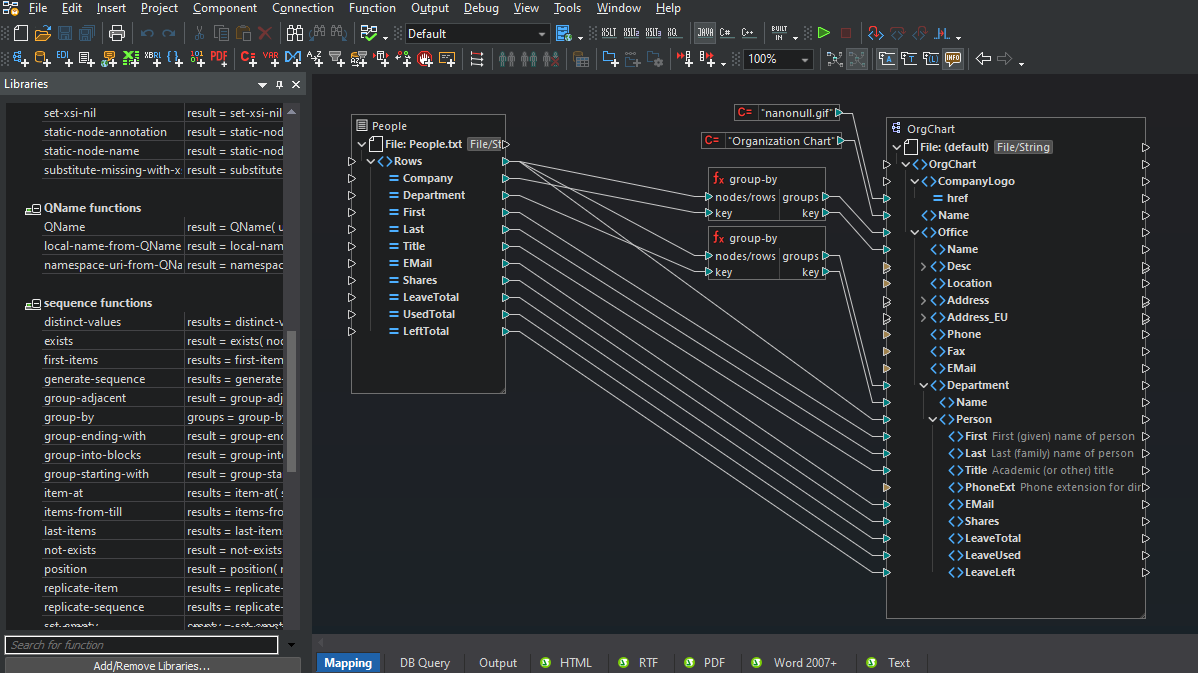
Altova MapForce includes flexible support for integrating flat files with XML, databases, EDI, Excel, PDF, XBRL, Shopify/GraphQL, and other data.
Flat files such as CSV and text documents are used by many different applications and are often employed as an exchange format between dissimilar programs. Many organizations continue to utilize legacy software that produces output in the form of text files. Integrating these flat files and text documents with other data formats in a modern computing environment is increasingly difficult.
MapForce supports flat files as both a source and target of any mapping. MapForce does not limit you to one-to-one mappings: you can mix multiple sources and multiple targets to map any combination of data formats.
When you load a CSV or FLF text file into a MapForce data mapping design, you can append, insert, and remove fields as well as change field header names and values as required before importing the file.
You can also choose to handle empty text file fields as empty elements in the data target, or you can treat empty fields as absent so they are not rendered in the target data structure.
Once you have loaded all of the content models required for your mapping, simply drag connecting lines between the source and target structures to connect matching elements.
MapForce includes a comprehensive library of data processing functions for filtering data based on Boolean conditions or manipulating numeric or string data in flat files as they are converted.