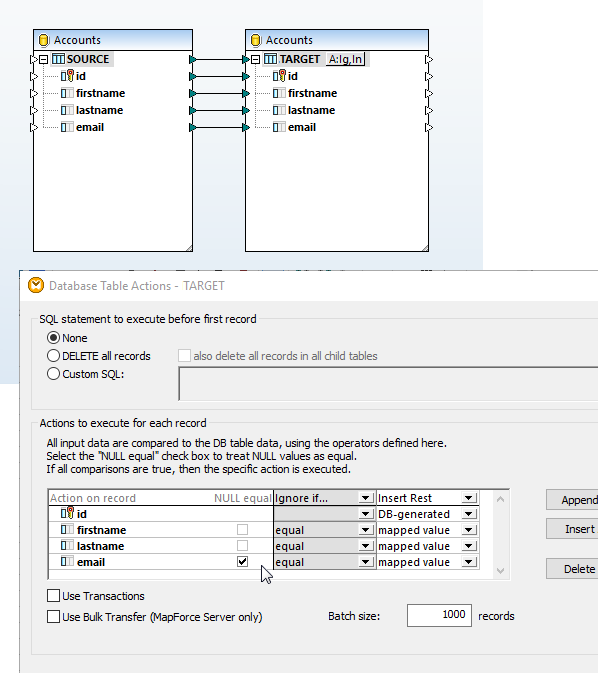
Une application commune pour MapForce sont des données migrantes entre les bases de données MySQL et PostgreSQL. MapForce rend le tout facile avec les outils de mappage de données drag-and-drop graphiques, y compris une bibliothèque de filtres enrichie et des fonctions de traitement des données pour transformer les données source.
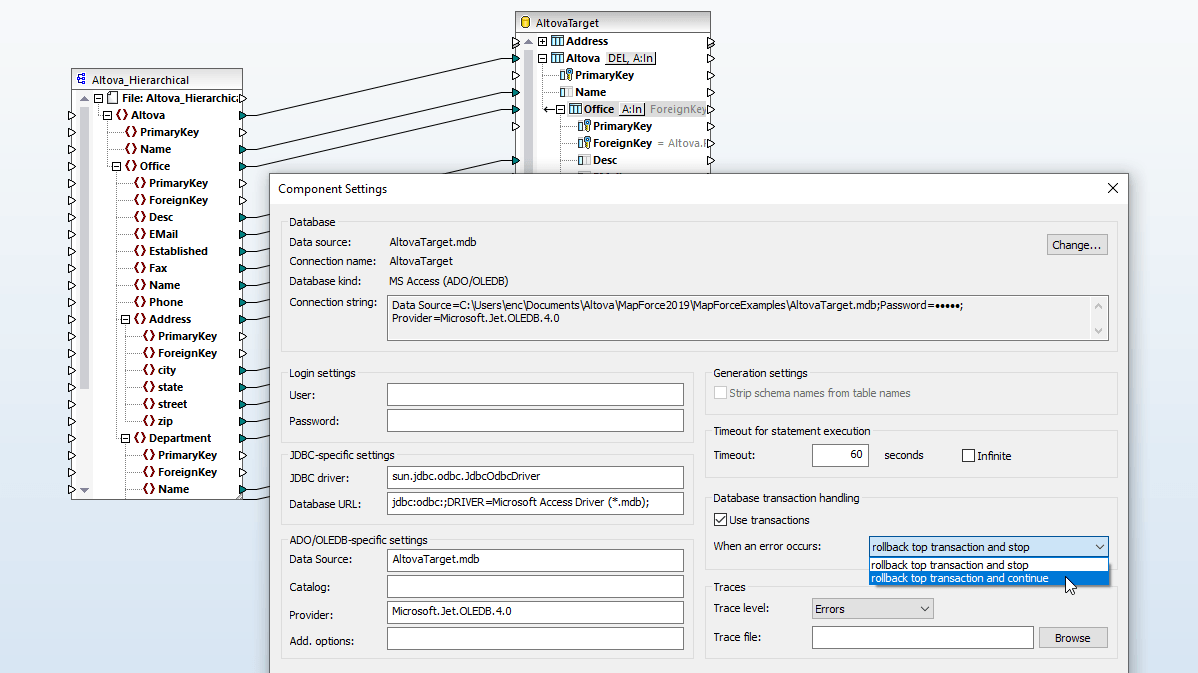
L’assistant de connexion de la base de données dans MapForce facilite la connexion. Les connexions SQLite sont prises en charge comme des connexions natives, directes dans le fichier de base de données SQLite. Aucun pilote séparé n’est requis. Les connexions PostgreSQL sont prises en charge comme connexions natives et comme connexions basées sur pilote à travers les interfaces (pilotes) telles que ODBC ou JDBC. Les connexions natives ne requièrent aucun pilote.
Lorsque vous chargez les structures de base de données MySQL et PostgreSQL dans le volet de mappage, MapForce interprète automatiquement le schéma de base de données, vous permet de choisir des tables et modes de base de données disponibles et reconnait des relations de table.
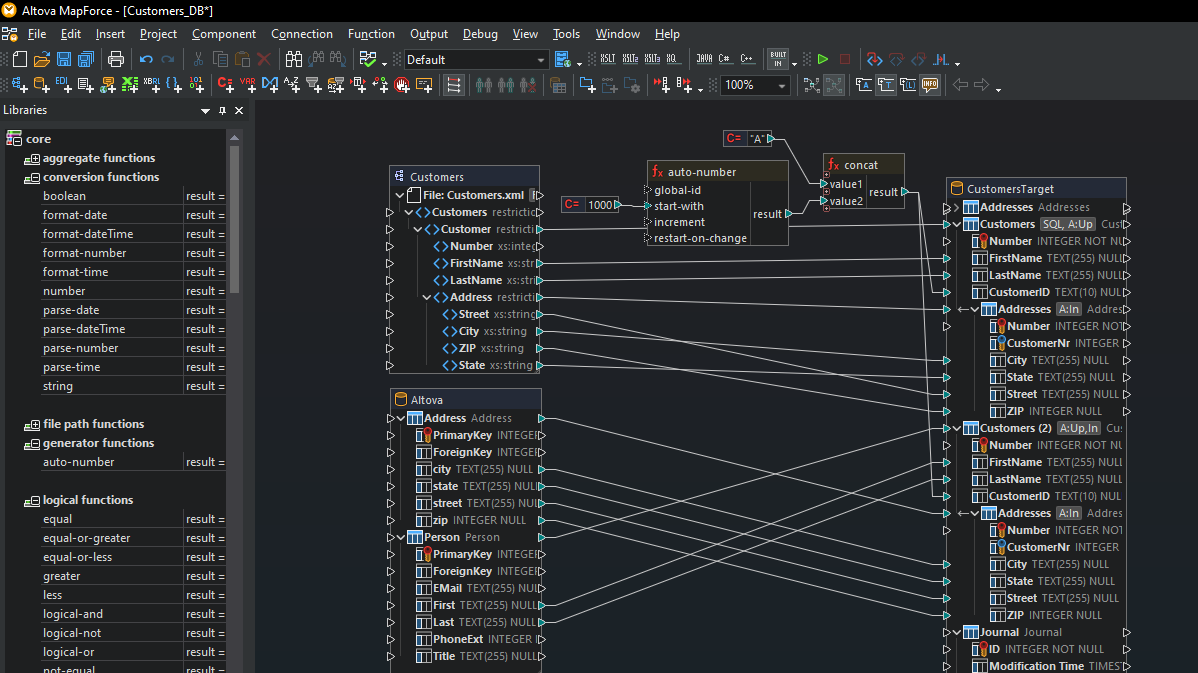
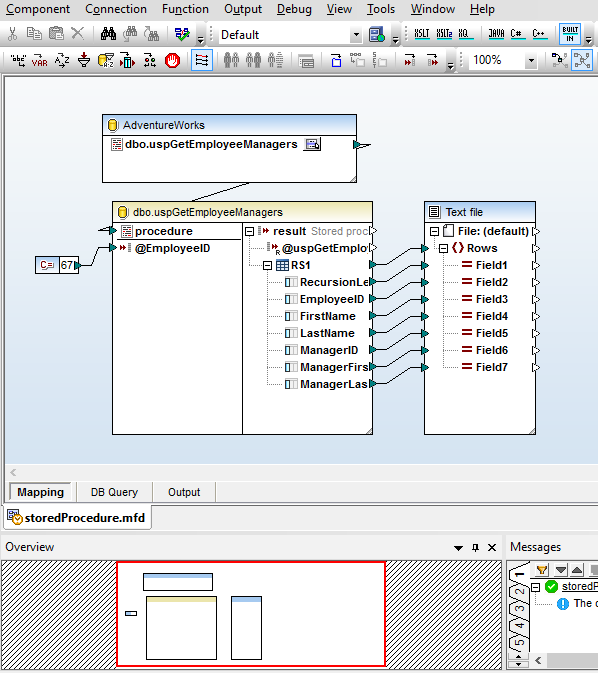
Une fois que vous avez chargé tous les modèles de contenu nécessaires pour votre mappage de base de données, terminez le mappage en glissant les lignes de connexion entre les structures de source et de cible.
En utilisant une approche MapForce no-code, il est facile de répondre aux exigences de transformation des données communes, par exemple :
- Convertir PostgreSQL en MySQL
- Migrer de PostgreSQL à MySQL
- Exporter PostgreSQL en MySQL
- Convertir MySQL en PostgreSQL
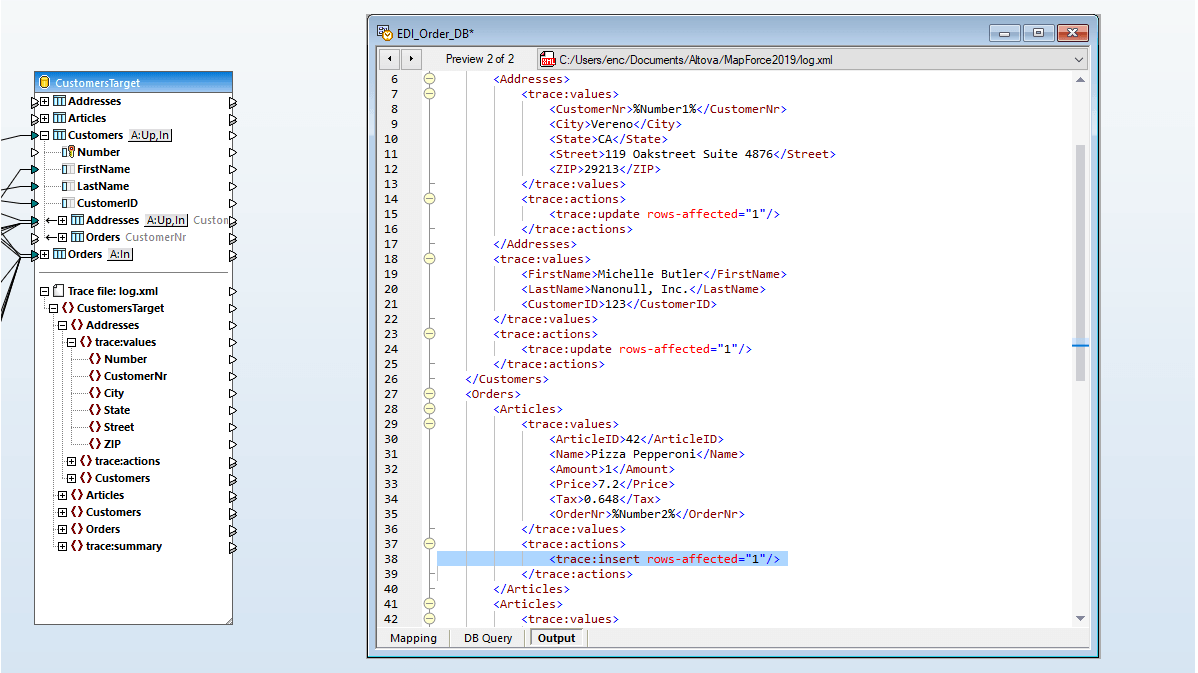
De nombreux mappages de base de données nécessitent la transformation de données entre la source et la cible sur la base de conditions booléennes ou d'instructions SQL et SQL/XML. Vous devrez éventuellement effectuer des comparaisons logiques, des calculs mathématiques ou des opérations de strings, contrôler les données de base de données d'une valeur particulière et procéder à d'autres modifications des données. Dans la capture d'écran ci-dessus, les fonctions de traitement des données apparaissent comme des cadres entre les lignes reliant le modèle de données source et cible.
Les fonctions de traitement des données vous permettent d'effectuer des mappages de base de données avancés très rapidement pour une multitude d'exigences de transformations concrètes
Une fois que votre mappage a été défini, le moteur intégré de MapForce vous permet de consulter et d'enregistrer les résultats en un clic.
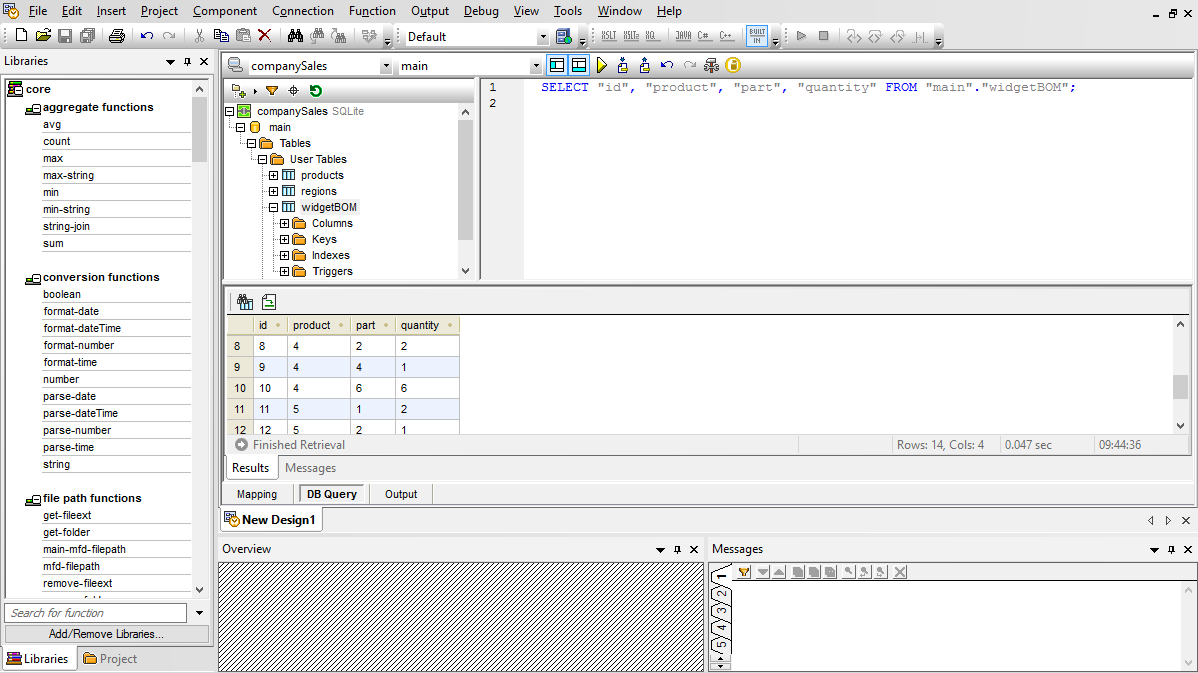
Votre mappage MySQL en PostgreSQL produira la sortie sous forme de scripts SQL (par ex., instructions SELECT, INSERT, UPDATE et DELETE) qui sont exécutés par rapport à la base de données cible directement depuis l’intérieur de MapForce.
Après avoir consulté la sortie, vous aurez l’option d’automatiser le processus de transformation des données via MapForce Server.