Defaults and Node Functions
Defaults and node functions are particularly useful when you want to apply the same processing logic to multiple descendant items in a structure. Usually you would need to copy-paste the same function multiple times in the mapping. This could clutter the mapping and make it more difficult to understand. Defaults and node functions can apply to a single item or to multiple items at once. Defaults replace empty sequences. If the connection transports a value, the default will be ignored.
Defaults and node functions are suitable for most components that have a tree with nodes (e.g., XML, EDI, Join components, variables).
Defaults and node functions are compatible only with the Built-In transformation language. Running such mappings from generated C#, C++, Java program code or with generated XSLT/XQuery transformations is not supported. On the server side, you can execute such mappings with MapForce Server Advanced Edition.
Advantages of node functions and defaults
Creating node functions and defaults means defining a rule. Rules have the following important characteristics that make them flexible and easy to use:
•Inheritance. When you define a rule on an item that has descendants, the rule will be inherited by descendants by default unless you choose to disable this option. If the item for which you define the function has multiple levels of child items nested under it, you can choose to apply the rule only to direct child items or to all descendant items.
•Filtering. MapForce applies rules conditionally, based on the data type of each item. This makes it possible, for example, to apply a certain default value or function to all items of type string and a different default or function to all items of type decimal. For details, see Scenario 2 in Use-Case Scenarios. You can also define more advanced filtering options: For example, you can specify a data type that your function must match (this could be a category of data types such as numeric) and then filter the nodes of this data type based on the node name or node type (e.g., integer). For details, see Scenario 5.
For example, you can instruct MapForce to do the following:
•Every time an empty or null value is encountered, replace it with some other value and do this recursively for all descendant items.
•Every time a specific value is encountered, replace it with some other value (or with an empty string) and do this recursively for all descendant items.
•Replace all database null values with empty strings or custom text.
•Append a custom prefix or suffix to all values that are written to a target file or database.
Output vs. input side
You can define node functions and defaults on the input side, output side, or on both sides of a component, depending on your needs. In MapForce, a mapping works in the following way: (i) it first reads data from a source component (e.g., an XML file), (ii) then optionally processes the data in some way (e.g., using a function), and (iii) finally writes data to some target component (e.g., a database). Considering this basic principle, you can set node functions and defaults at various stages:
•Immediately after data is read from the source, but before it is further processed by your mapping, which means the function/default is defined on the output side of the source component (see example below).
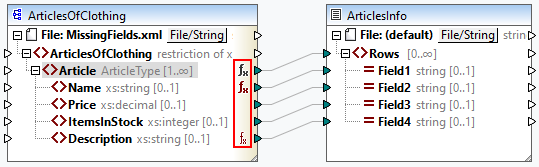
•Immediately before data is written to the target component (and after it has finished all intermediary processing), which means the function/default is defined on the input side of the target component (see example below).
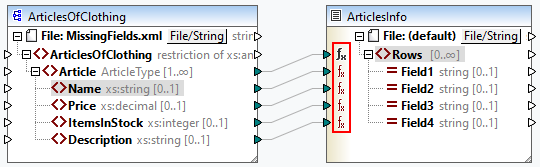
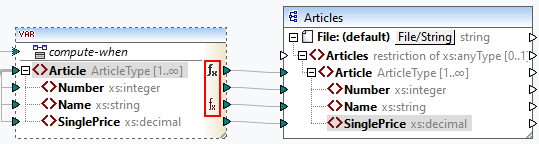
•At an intermediary stage in the mapping process. For example, if the mapping contains an intermediary variable of complex type (e.g., an XML structure), you can trim all values before they are supplied to the XML structure or immediately after they are returned by the XML structure (see example below).
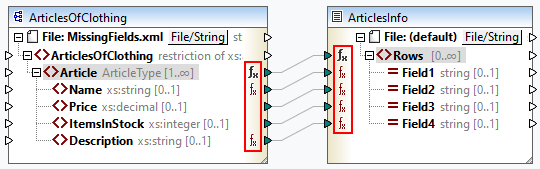
•On the output side of a source component and on the input side of a target component. In the example below, a default has been defined for all the nodes of type string in the ArticlesOfClothing component. In the ArticlesInfo component, we have defined a node function that will transform all values of string nodes into uppercase characters.
In this section
This section explains how to configure a rule, describes real-life scenarios in which defaults and node functions can be useful, and shows how to add node metadata to node functions. The section is organized into the following topics:
•Node Metadata in Node Functions