Altova MapForceは、フラットファイルとXML、データベース、EDI、Excel、PDF、XBRL、Shopify/GraphQL、およびその他のデータ形式との統合を柔軟にサポートしています。
CSVファイルやテキストファイルといったフラットファイルは、多くの異なるアプリケーションで使用されており、しばしば、互換性のないプログラム間でのデータ交換形式として利用されています。多くの組織では、依然としてテキストファイル形式で出力を行うレガシーソフトウェアを利用し続けています。このようなフラットファイルやテキストファイルを、現代的なコンピューティング環境における他のデータ形式と統合することは、ますます困難になっています。
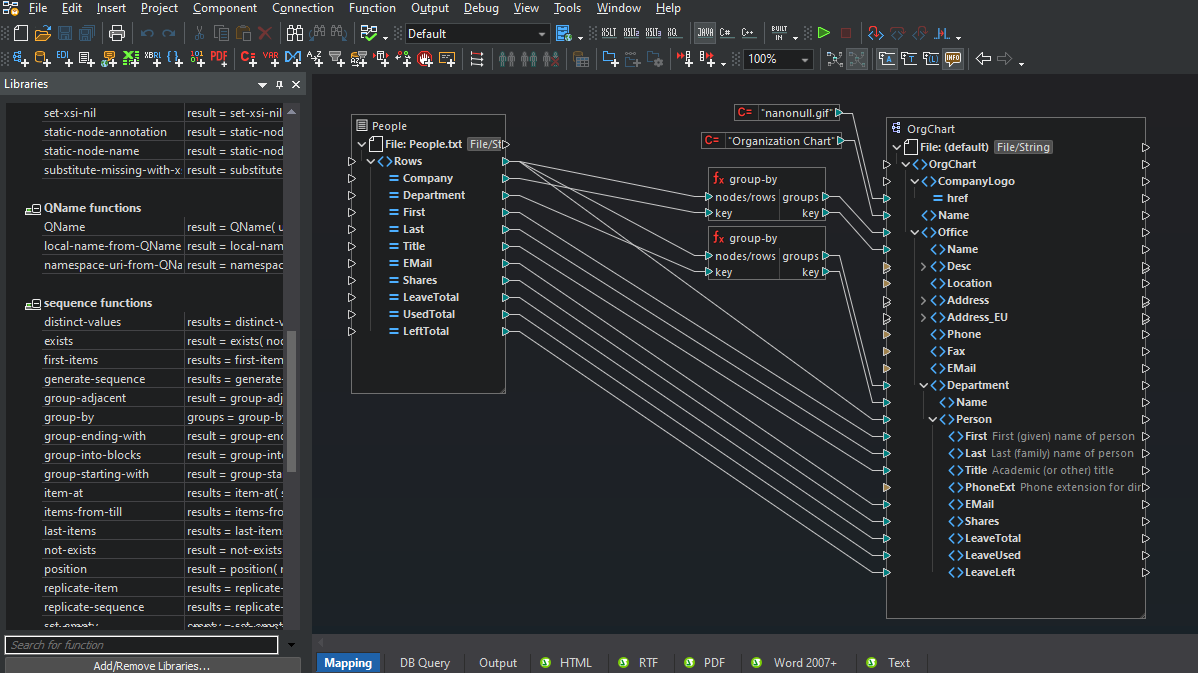
MapForceは、あらゆるデータ変換において、フラットファイルをソースとターゲットの両方としてサポートします。MapForceは、単純な1対1のマッピングに限定されるものではなく、複数のソースと複数のターゲットを組み合わせて、あらゆるデータ形式の組み合わせをマッピングすることができます。
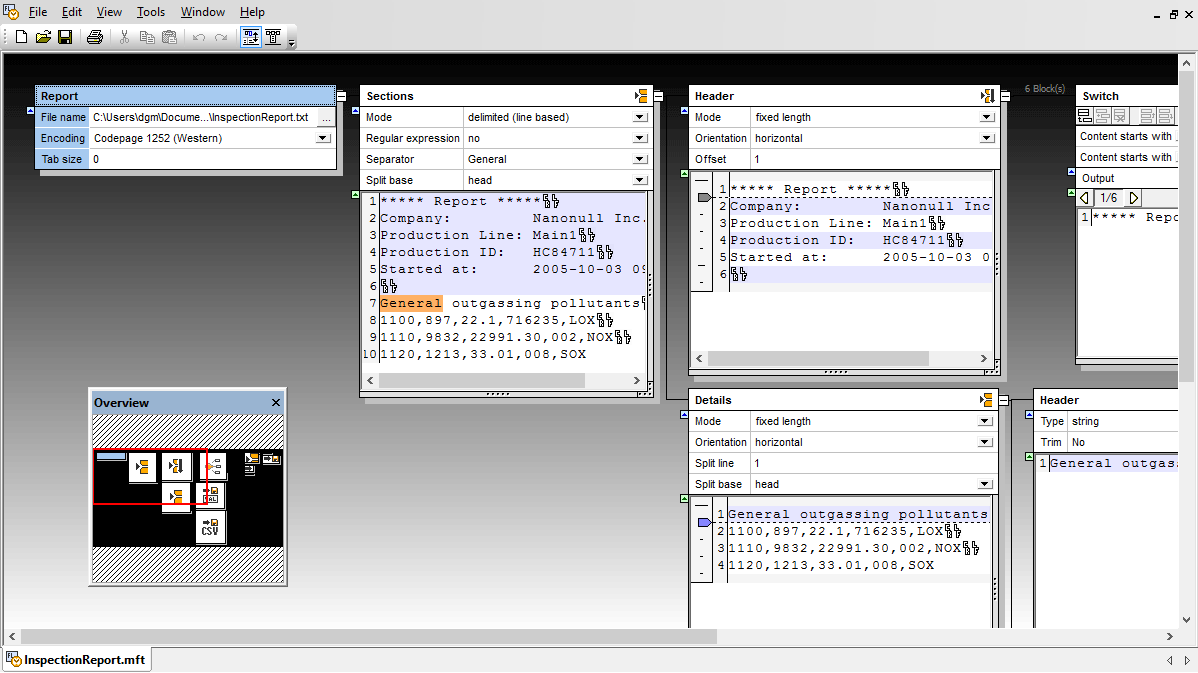
MapForceのデータマッピング設計にCSVまたはFLF形式のテキストファイルを読み込む際、ファイルをインポートする前に、必要に応じてフィールドの追加、挿入、削除を行うことができます。また、フィールドのヘッダー名や値を変更することも可能です。
また、空のテキストファイル内のフィールドを、データ出力先において空の要素として扱うことも可能です。あるいは、空のフィールドを「存在しない」ものとして扱い、データ構造の出力先には表示しないようにすることもできます。
マッピングに必要なコンテンツモデルをすべて読み込んだら、ソースとターゲットの構造間で接続線をドラッグして、対応する要素同士を繋げてください。
MapForceには、データのフィルタリング(ブール条件に基づく)、およびフラットファイル内の数値データや文字列データの操作など、データ処理のための豊富な機能ライブラリが搭載されており、データ変換時にこれらの処理を実行できます。