Altova MapForce는 일반 텍스트 파일과 XML, 데이터베이스, EDI, 엑셀, PDF, XBRL, Shopify/GraphQL 및 기타 데이터 형식을 통합하는 데 유연한 기능을 제공합니다.
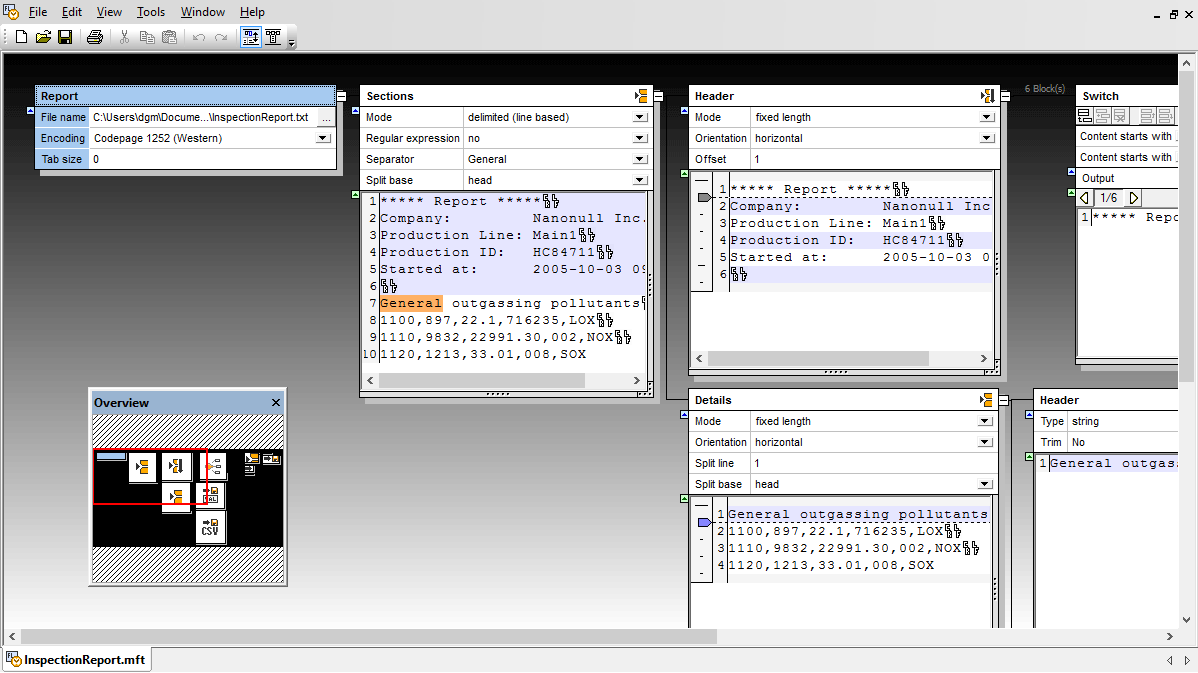
CSV 파일이나 텍스트 문서와 같은 단순 텍스트 파일은 다양한 응용 프로그램에서 사용되며, 종종 서로 다른 프로그램 간의 데이터 교환 형식으로 활용됩니다. 많은 조직에서는 여전히 텍스트 파일 형태로 결과를 출력하는 기존 소프트웨어를 사용하고 있습니다. 이러한 단순 텍스트 파일과 텍스트 문서를 현대적인 컴퓨팅 환경에서 다른 데이터 형식과 통합하는 것은 점점 더 어려워지고 있습니다.
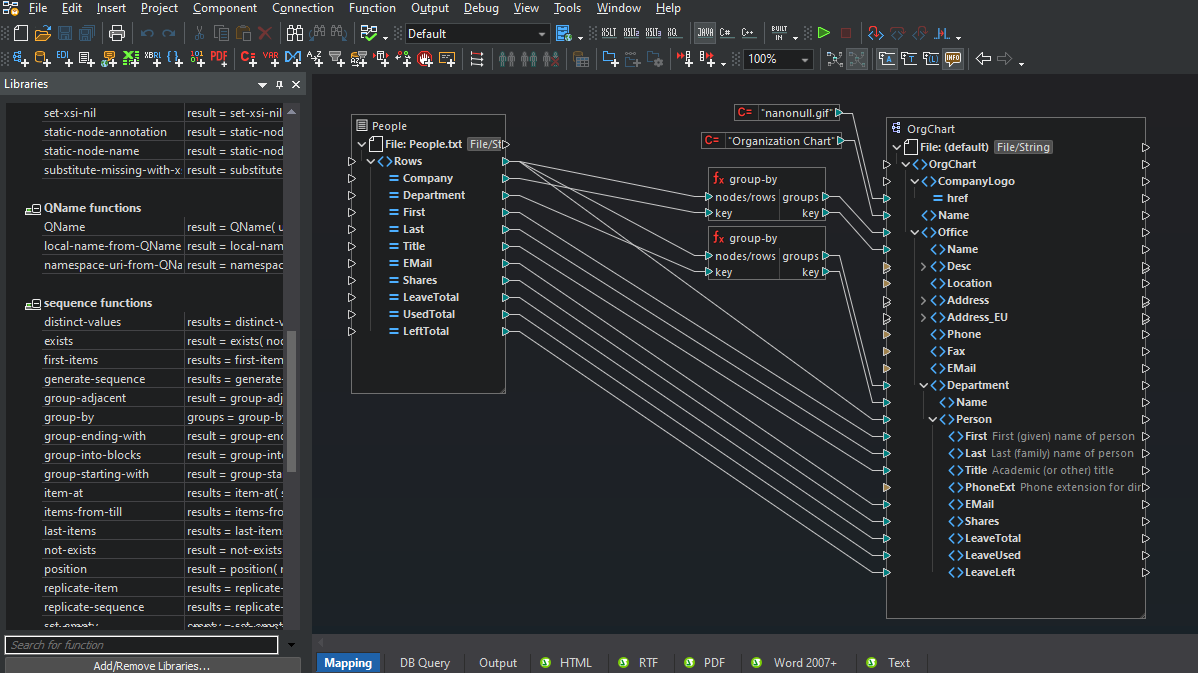
MapForce는 모든 매핑 작업에서 일반 텍스트 파일을 소스 및 대상 데이터로 지원합니다. MapForce는 일대일 매핑에만 국한되지 않으며, 여러 소스와 여러 대상을 혼합하여 다양한 데이터 형식의 조합을 매핑할 수 있습니다.
MapForce 데이터 매핑 디자인에 CSV 또는 FLF 텍스트 파일을 불러올 때, 파일을 가져오기 전에 필요한 경우 필드를 추가, 삽입, 삭제하고, 필드 헤더 이름과 값을 변경할 수 있습니다.
또한, 빈 텍스트 파일 필드를 데이터 대상에서 빈 요소로 처리하도록 선택할 수도 있습니다. 또는, 빈 필드를 "존재하지 않음"으로 간주하여 대상 데이터 구조에 해당 필드가 표시되지 않도록 설정할 수도 있습니다.
매핑에 필요한 모든 콘텐츠 모델을 불러온 후, 소스(출력)와 타겟(입력) 구조 간에 연결선을 드래그하여 일치하는 요소를 연결하면 됩니다.
MapForce는 데이터를 필터링하거나, 평면 파일에서 숫자 또는 문자 데이터를 변환하는 등 다양한 데이터 처리 기능을 위한 포괄적인 라이브러리를 제공합니다. 이러한 기능은 불리언 조건을 기반으로 데이터를 필터링하거나, 데이터 변환 과정에서 숫자 또는 문자 데이터를 조작하는 데 사용될 수 있습니다.