Hinzufügen einer NoSQL-Datenbank
Um in MapForce mit NoSQL-Datenbanken arbeiten zu können, müssen Sie eine NoSQL-Datenbank als Mapping-Komponente hinzufügen und ihr ein Schema zuweisen. Gehen Sie folgendermaßen vor:
Hinzufügen einer NoSQL Datenbank zum Mapping
Für NoSQL-Datenbanken unterstützt MapForce nur Built-in als Transformationssprache. Unten wird beschrieben, wie Sie Collections aus einer MongoDB-Datenbank zu einem Mapping hinzufügen. Unsere Beispieldatenbank hat den Namen doc.
1.Im ersten Schritt muss eine Quelldatenbank ausgewählt werden (in unserem Fall MongoDB). Gehen Sie zum Menü Einfügen und klicken Sie auf Datenbank. Klicken Sie alternativ dazu auf die Symbolleisten-Schaltfläche  (Datenbank einfügen).
(Datenbank einfügen).
2.Wählen Sie im Verbindungsassistenten MongoDB aus und klicken Sie auf Weiter.
3.Im Dialogfeld Datenbank auswählen müssen Sie die folgenden Parameter angeben: Host, Port, Datenbank, Benutzername und Passwort. Geben Sie die erforderlichen Parameter ein und klicken Sie auf Verbinden. Die Verbindungsinformationen variieren je nach Datenbanktyp. Nähere Informationen dazu finden Sie unter MongoDB-Verbindung, CouchDB-Verbindung und CosmosDB-Verbindung.
4.Das Dialogfeld Datenbankobjekte einfügen wird geöffnet und Sie werden aufgefordert, Collections, die Sie in Ihrem Mapping verwenden möchten, auszuwählen (siehe Abbildung unten). Aktivieren Sie die entsprechenden Kästchen und klicken Sie auf OK.
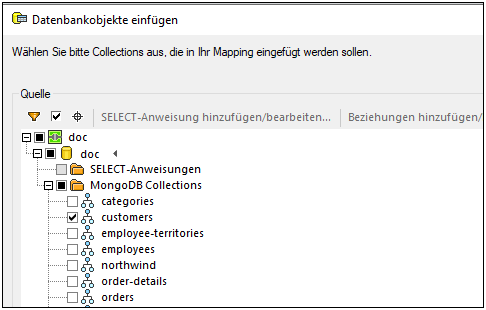
5.Ihre NoSQL-Datenbankkomponente enthält nun eine Collection namens customers (siehe Abbildung unten).

Im nächsten Schritt wird der Collection nun ein JSON-Schema zugewiesen, das ihre Struktur definiert.
Anmerkung: Wenn Sie eine Verbindung zu einem MongoDB Cluster herstellen, müssen Sie eventuell Ihre IT-Abteilung kontaktieren, um Firewall-Zugriff auf die IP-Adressen Ihres Clusters und Port zu erhalten.
Zuweisen eines JSON-Schemas
Nachdem wir nun die entsprechenden Dokumente aus unserer doc-Collection ausgewählt haben, müssen wir der NoSQL-Komponente ein JSON-Schema zuweisen. Gehen Sie folgendermaßen vor:
1.Klicken Sie auf die Schaltfläche ![]() (JSON-Schema zuweisen) rechts vom Namen der Collection (customers). Daraufhin wird das Dialogfeld JSON-Schema einer Collection zuweisen (siehe Abbildung unten) aufgerufen.
(JSON-Schema zuweisen) rechts vom Namen der Collection (customers). Daraufhin wird das Dialogfeld JSON-Schema einer Collection zuweisen (siehe Abbildung unten) aufgerufen.
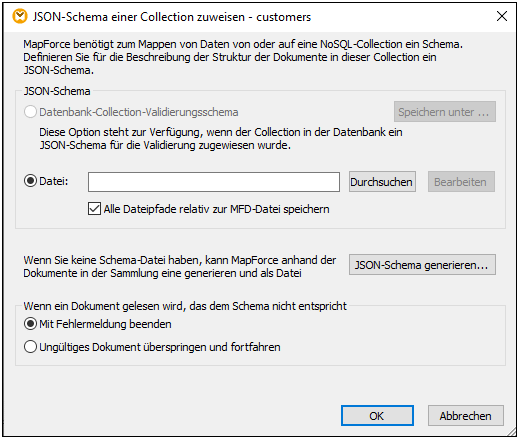
2.Sie haben die Wahl zwischen drei Optionen, um ein JSON-Schema zuzuweisen: (i) Auswahl eines in Ihrer Datenbank zugewiesenen Schemas, (ii) Suche nach dem vorhandenen JSON-Schema auf Ihrem lokalen Rechner, (iii) Generierung eines neuen Schemas durch MapForce.
i.Wenn Sie die erste Option wählen, können Sie das JSON-Schema auch aus der Datenbank exportieren (Klicken Sie auf Speichern unter).
ii.Wenn Sie für Ihre Quelldatei bereits ein JSON-Schema haben, klicken Sie auf Durchsuchen und navigieren Sie zum gewünschten Schema. Wenn Sie sich für das Hochladen Ihrer Schema-Datei entscheiden, ist die Schaltfläche Bearbeiten aktiv. Wenn Sie darauf klicken, wird Ihre Schema-Datei in Altova XMLSpy geöffnet, falls das Programm auf Ihrem Rechner installiert ist.
iii.Falls Sie kein Schema zur Verfügung haben, kann MapForce eines für Sie generieren. Klicken Sie in diesem Fall auf JSON-Schema generieren.
Außerdem müssen Sie angeben, ob die Dokumentverarbeitung beendet oder fortgesetzt werden soll, wenn Dokumente vorhanden sind, die nicht dem Schema entsprechen (siehe letzter Abschnitt des Dialogfelds oben). Beachten Sie, dass diese beiden Optionen zur Mapping-Laufzeit angewendet werden.
3.Wenn Sie auf JSON-Schema generieren klicken, wird das Dialogfeld JSON-Schema generieren geöffnet. Lassen Sie die Textfelder FILTER und SORT leer, wenn Sie keine Filter- und Sortierkriterien definierten möchten. Klicken Sie anschließend auf OK. Beachten Sie, dass Sie auch angeben können, wie viele Dokumente der Parser analysieren soll. Mit der Option ÜBERSPRINGEN weisen Sie den Parser an, die ersten N Dokumente in der Collection zu überspringen. Mit der Option LIMIT weisen Sie den Parser an, nur die ersten N Dokumente in der Collection zu analysieren. Dem Schema der Datenbankkomponente wird dann die Struktur der durch die Kombination dieser Kriterien definierten Dokumente zugrunde gelegt. Nähere Informationen zu FILTER und SORT finden Sie im Unterabschnitt weiter unten.
4.Wenn Sie auf OK klicken, müssen Sie Ihrer Schema-Datei einen Namen geben und einen Ordner für das Schema auswählen. Klicken Sie anschließend wieder auf OK.
Ihrer Datenbankkomponente hat nun eine Baumstruktur und ist bereit für das Mapping.
FILTER und SORT
Ohne Abfrageoptionen in den Textfeldern FILTER und SORT (des Dialogfelds JSON-Schema generieren) liest MapForce alle Dokumente in der Collection, um ein Schema zu generieren. Collections können allerdings Tausende von Dokumenten enthalten, was lange Verarbeitungszeiten verursachen kann. In diesem Fall empfiehlt es sich, eine Untergruppe von Dokumenten auszuwählen, die alle Strukturvarianten, die in Ihrem Mapping verarbeitet werden sollen, abdecken. Mit dem Begriff Strukturvarianten wird in diesem Kontext festgelegt, welche Eigenschaften im Dokument vorkommen und welche Typen diese Eigenschaften haben können.
Es ist unwahrscheinlich, dass in derselben Collection Dokumente vollkommen unterschiedlicher Struktur gespeichert sind, unter Umständen gibt es jedoch viele zusätzliche Felder, die in nur einigen Dokumenten vorkommen. Folgende Szenarien sind möglich:
•Wenn mit dem Filter nur Dokumente ausgewählt werden, die ein Feld, das in einigen anderen Dokumenten vorkommt, nicht haben, so wird das Schema dieses Feld nicht enthalten. Wenn später zur Laufzeit ein solches Feld gefunden wird, kommt es zu einem Validierungsfehler oder es gibt in der Zielkomponente keinen Node, auf den dieses Feld gemappt werden kann.
•Wenn alle Beispieldokumente eine bestimmte Eigenschaft enthalten, wird diese Eigenschaft im Schema als "obligatorisch" gekennzeichnet, wodurch ein Dokument (das eventuell später zu dieser Collection hinzugefügt wurde), das diese Eigenschaft nicht hat, anhand des Schemas als ungültig validiert wird.
In der Praxis ist ein anhand einer eingeschränkten Auswahl an Dokumenten generiertes Schema eventuell unvollständig und muss manuell bearbeitet werden, z.B. um zusätzliche Eigenschaften hinzuzufügen, einige Eigenschaften zu optionalen zu machen oder für einige Eigenschaften zusätzliche Datentypen zur Verfügung zu stellen.
FILTER-Beispiel
Im Unterabschnitt Hinzufügen einer NoSQL-Datenbank haben wir eine NoSQL-Datenbankkomponente erstellt, die ein Dokument namens customers enthält. MapForce soll nun bei der Generierung eines neuen Schemas die Filterkriterien berücksichtigen. Es gibt in unserer customers Collection Dokumente zweier Arten (siehe unten).
doc.customers1
"CustomerID": "ALFKI",
"CompanyName": "Alfreds Futterkiste",
"ContactName": "Maria Anders",
"ContactTitle": "Sales Representative",
"Address": "Obere Str. 57",
"City": "Berlin",
"Region": "NULL",
"PostalCode": "12209",
"Country": "Germany",
"Phone": "030-0074321",
"Fax": "030-0076545"
doc.customers2
"0": "BOTTM",
"1": "Bottom-Dollar Markets",
"2": "Elizabeth Lincoln",
"3": "Accounting Manager",
"4": "23 Tsawassen Blvd.",
"5": "Tsawassen",
"6": "BC",
"7": "T2F 8M4",
"8": "Canada",
"9": "(604) 555-4729",
"10": "(604) 555-3745"
Unserer Schema-Datei soll nun die Struktur mit den Namensfeldern (doc.customers1) zugrunde gelegt werden. In der Abbildung unten sehen Sie unser Filterkriterium, das folgendermaßen lautet: Wähle nur diejenigen Dokumente aus, in denen das Feld CustomerID vorhanden ist (siehe Abbildung unten). Der Parser geht die Liste aller Dokumente in der Collection durch und wählt nur diejenigen aus, die dieses Kriterium erfüllen. Nähere Informationen über die Syntax zum Abfragen von Dokumenten in einer Collection finden Sie in der Dokumentation zu MongoDB.
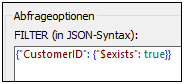
Nachdem Sie Ihre Daten gefiltert haben, können Sie diese auch sortieren, z.B. nach dem Feld City. Anschließend könnten Sie angeben, wie viele Dokumente aus der sortierten Auswahl bei der Schemagenerierung übersprungen (ÜBERSPRINGEN) und/oder berücksichtigt (LIMIT) werden sollen.
Achtung
Wenn Sie Ihre Daten filtern und/oder sortieren, wird eine Untergruppe Ihrer Dokumente wie z.B. diejenigen in doc.customers2 dem generierten Schema nicht entsprechen und Validierungsfehler verursachen. Um solche Fehler zu vermeiden, aktivieren Sie im Dialogfeld JSON-Schema eine Collection zuweisen (siehe Abbildung oben) die Option Ungültige Dokumente überspringen und fortfahren. |