Tutorial
In diesem Tutorial finden Sie ein Schritt-für-Schritt-Beispiel für die Anwendung von OCR auf ein gescanntes PDF-Dokument. Die Beispieldateien befinden sich unter dem folgenden Pfad:
C:\Benutzer\<Benutzername>\Dokuments\Altova\MapForce<YEAR>\MapForceExamples\Tutorial\OCR
Quelldatei: gescanntes PDF-Dokument
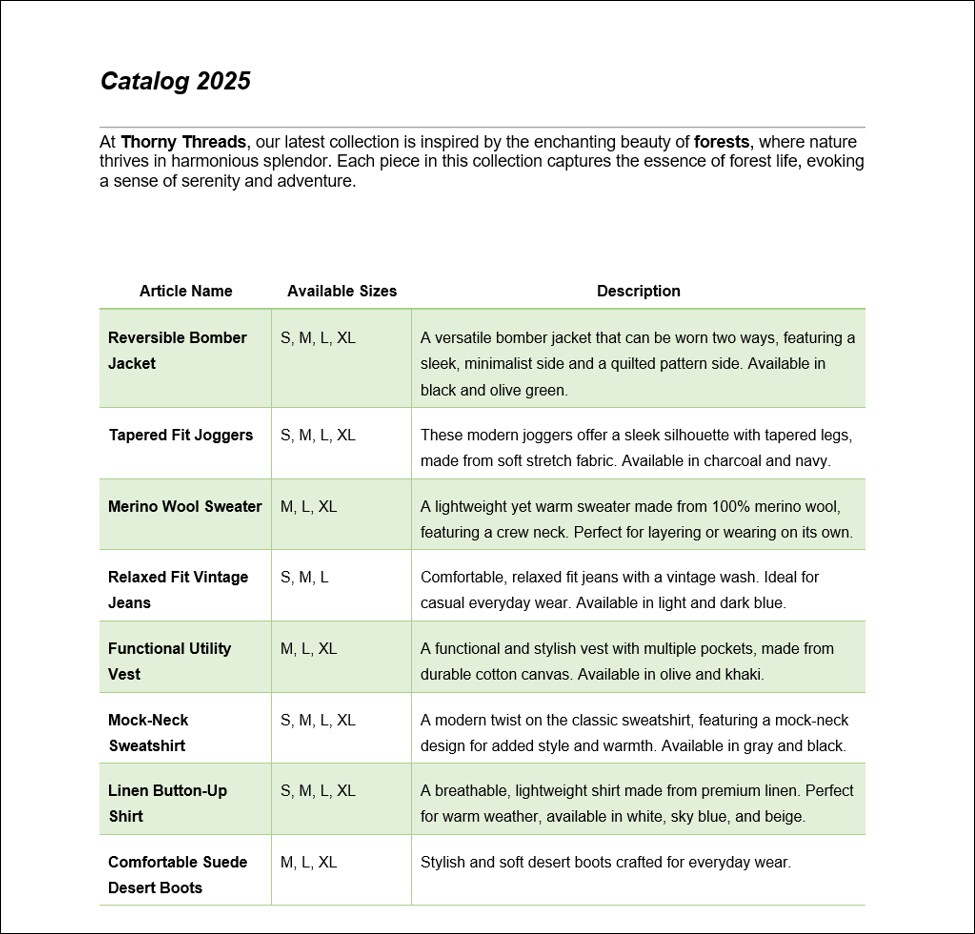
Unsere Quelldatei ist ein aus einer Seite bestehendes PDF-Dokument namens Catalog2025.pdf (Abbildung unten).
Schritt 1: Erstellen einer PXT-Vorlage und Laden des PDF-Dokuments
Wir haben zu diesem Zeitpunkt eine PXT-Datei erstellt und unser gescanntes PDF-Dokument importiert (siehe auch OCR-Arbeitsablauf).
Schritt 2: Überprüfen der erkannten Wörter
Wenn das neu erstellte ocr.pdf-Dokument in einem separaten Fenster geöffnet wird, wird automatisch OCR (optische Zeichenerkennung) auf das Dokument angewendet. Die OCR-Ergebnisse werden in der Objektstruktur (Abbildung unten) angezeigt. Sie können auch im Scan-Bereich des Dokuments angezeigt werden, wenn der Symbolleisten-Befehl Overlays anzeigen aktiv ist.
In unserem Beispiel haben wir die Befehle Overlays anzeigen und Alle Overlays anzeigen aktiviert. Grün markierte Wörter werden in die Struktur der erkannten Wörter aufgenommen. Rot angezeigte Wörter wurden ausgenommen, da die OCR-Vertrauenswürdigkeit eventuell unterhalb des Schwellenwerts lag.
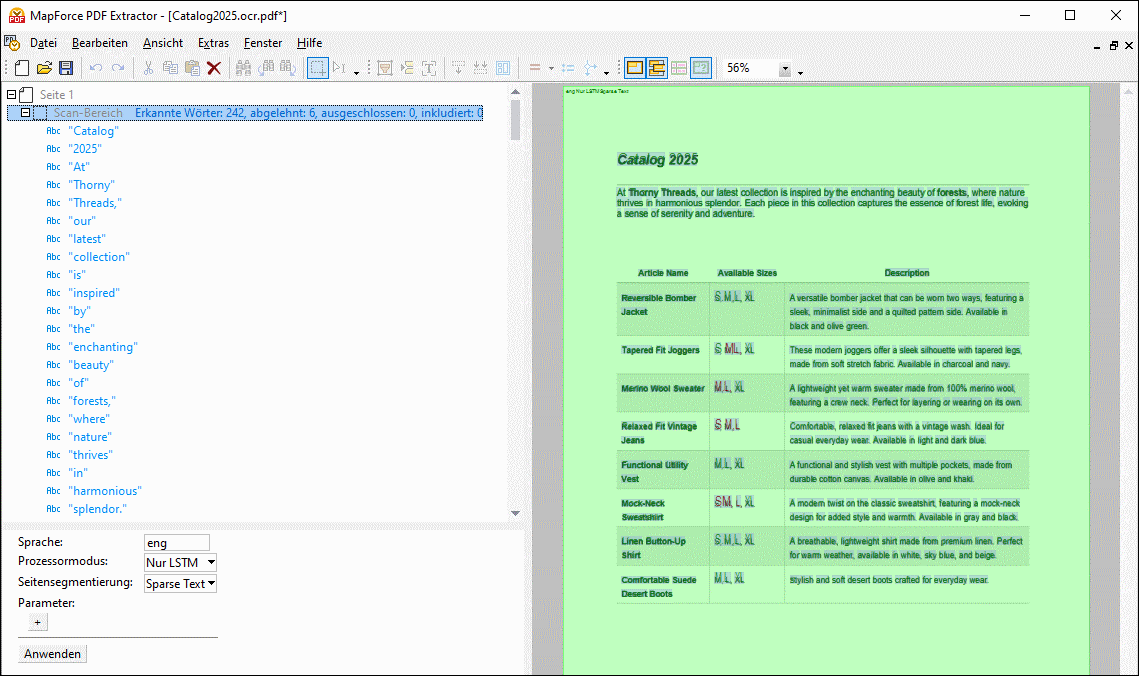
Im Großen und Ganzen hat der OCR-Prozessor den größten Teil des Texts mit Ausnahme einiger Größenbezeichnungen korrekt erkannt. In diesem Tutorial zeigen wir eine der möglichen Methoden, wie Sie die Ergebnisse korrigieren können. So wurden etwa in der Zelle mit den Informationen über die Größen des Artikels Tapered Fit Joggers zwei Wörter erkannt (S und XL) und ein erkanntes Wort wurde exkludiert (ML). Um diese Ergebnisse zu korrigieren, gehen Sie folgendermaßen vor:
1.Klicken Sie im PDF-Ansichtsfenster auf ML und löschen Sie dieses Wort. Machen Sie dasselbe mit XL.
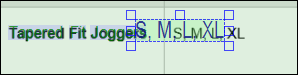
2.Doppelklicken Sie auf S und bearbeiten Sie den Text um andere Größe zu inkludieren: S, M, L, XL. Wenn Sie mit der Bearbeitung fertig sind, drücken Sie die Eingabetaste. Die bearbeiteten Wörter erscheinen nun am unteren Rand der Objektstruktur als Benutzerwörter. Beachten Sie, dass das bearbeitete Textfeld möglicherweise mit einigen anderen Wörtern überlappt (Abbildung unten). Wenn das der Fall ist, funktioniert die Textextraktion eventuell nicht korrekt.
3.Positionieren Sie das Textfeld so, dass es möglichst genau dem Originaltext entspricht, wie unten gezeigt. Dadurch stellen Sie sicher, dass der Text korrekt extrahiert wird.

4.Wiederholen Sie dieselben Schritte für andere nicht korrekt erkannte Größen.
Schritt 3: Speichern der OCR-Vorlage und Definieren der PXT-Vorlage
Nachdem Sie die ErkanntenWörter fertig bearbeitet haben, speichern Sie die OCR-Vorlage und kehren Sie zum PXT-Fenster zurück. Die wichtigste Aufgabe ist zu diesem Zeitpunkt, eine Vorlage zu erstellen, mit Hilfe derer Sie den vom OCR-Prozessor erkannten Text extrahieren können. Gehen Sie folgendermaßen vor:
1.Stellen Sie sicher, dass der Symbolleisten-Befehl Vorschläge anzeigen aktiv ist.
2.Erstellen Sie im Schema-Fenster anhand des ersten automatischen Tabellenvorschlags eine Tabellenstruktur.
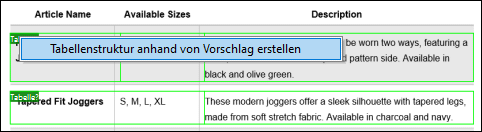
Auf Basis dessen wurde die folgende Objektstruktur erstellt:
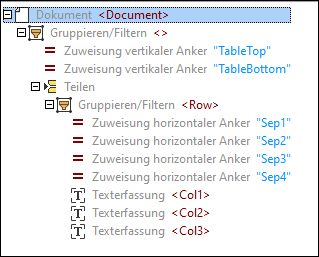
3.Da wir den Tabellenvorschlag verwendet haben, der nur eine Tabellenzeile enthielt, müssen wir zum unteren Rand der Tabelle (TableBottom) gehen, um alle Zeilen in die Tabelle zu inkludieren. Klicken Sie dazu in der Struktur auf Zuweisung vertikaler Anker "TableBottom", klicken Sie im PDF-Ansichtsfenster auf die Beschriftung TableBottom und ziehen Sie die Linie nach unten.
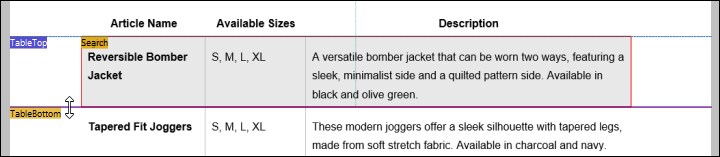
Wenn Sie den unteren Rand der Tabelle (TableBottom) ändern, werden die Ergebnisse im Ausgabefenster aktualisiert, sodass alle Tabellendaten inkludiert werden.
4.Geben Sie den Strukturobjekten sinnvolle Namen, wie unten gezeigt. Wenn Sie die Objektnamen ändern, werden auch die XML-Elemente im Ausgabefenster aktualisiert.

5.Erstellen Sie Texterfassungen für das Katalogjahr und die Beschreibung, wie unten gezeigt.

Ausgabe
Mit Hilfe der Vorlage wurden erfolgreich OCR-Daten aus unserem gescannten PDF-Dokument extrahiert. Das Ergebnis wird im Ausgabefenster angezeigt:
Katalog <Year>2025</Year> <Info>At Thorny Threads, our latest collection is inspired by the enchanting beauty of forests, where nature thrives in harmonious splendor. Each piece in this collection captures the essence of forest life, evoking a sense of serenity and adventure.</Info> <Article> <Name>Reversible Bomber Jacket</Name> <Sizes>S, M, L, XL</Sizes> <Description>A versatile bomber jacket that can be worn two ways, featuring a sleek, minimalist side and a quilted pattern side. Available in black and olive green.</Description> </Article> <Article> <Name>Tapered Fit Joggers</Name> <Sizes>S, M, L, XL</Sizes> <Description>These modern joggers offer a sleek silhouette with tapered legs, made from soft stretch fabric. Available in charcoal and navy.</Description> </Article> <Article> <Name>Merino Wool Sweater</Name> <Sizes>M, L, XL</Sizes> <Description>A lightweight yet warm sweater made from 100% merino wool, featuring a crew neck. Perfect for layering or wearing on its own.</Description> </Article> <Article> <Name>Relaxed Fit Vintage Jeans</Name> <Sizes>S, M, L</Sizes> <Description>Comfortable, relaxed fit jeans with a vintage wash. Ideal for casual everyday wear. Available in light and dark blue.</Description> </Article> <...> </Catalog> |
Wenn Sie Probleme bei den extrahierten Daten im Ausgabefenster bemerken, können Sie die OCR-Vorlage anpassen, speichern und die Ergebnisse im PXT-Fenster noch einmal überprüfen.
Nächste Schritte
Wir sind nun mit der Definition der PDF-Extraktionvorlage fertig. Im nächsten Schritt würde die Vorlage nun in MapForce importiert und ein Mapping erstellt, um die extrahierten PDF-Daten zu verarbeiten.