Definieren der Struktur und Extrahieren von Daten
In diesem Kapitel werden folgende Schritte beschrieben:
•Automatische Extraktion von Tabellenstruktur und -daten anhand von Vorschlägen
•Definieren anderer Extraktionsregeln auf manuelle Art
•Speichern der Vorlage
Die Reihenfolge, in der Sie Ihre Vorlage erstellen, kann variieren und muss nicht mit der oben beschriebenen übereinstimmen.
Automatische Extraktion von Tabellenstruktur und -daten
Im ersten Schritt extrahieren wir die Daten aus der Tabelle. Am einfachsten geschieht dies mit Hilfe der Vorschläge des PDF Extrators für die Tabelle (in der Abbildung unten grün markiert). Um den Vorschlag zu verwenden, doppelklicken Sie im linken oberen Eck des grünen Rahmens auf die Schaltfläche Table?. Die Zellen mit Informationen über Preis und Steuer werden separat verarbeitet.
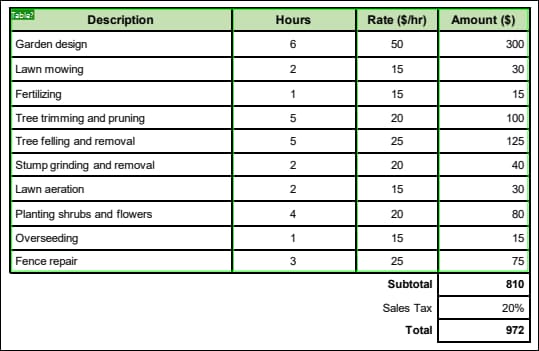
Sobald Sie auf die Schaltfläche Tabelle? doppelklicken, wird im Schema-Fenster die folgende Struktur angezeigt:
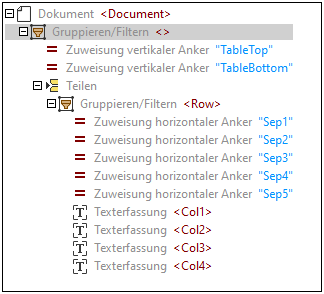
Das Schema-Fenster ist eine Toolbox bestehend aus Objekten, die definieren, wie Daten extrahiert werden sollen. Die Vorlage hat zu diesem Zeitpunkt die folgende Struktur:
•den obersten Node, der das Root-Element darstellt (Invoice)
•das Objekt "Gruppierung/Filter", das Seiten eines PDF-Dokuments gruppiert und filtert
•zwei vertikale Zuweisungen (Oberer Rand und Unterer Rand), die die Position angeben, an der die Tabelle jeweils beginnt bzw. endet.
•das Teilen-Objekt, das die Tabelle in Zeilen unterteilt
•das Objekt "Gruppierung/Filter", das die Zeilen der Tabelle zusammengruppiert
•fünf horizontale Zuweisungen, die die Positionen von Ankern, die die Spalten trennen, markieren
•vier Texterfassungen, die die Namen der Tabellenspalten enthalten
Nähere Informationen zu den einzelnen Objekten finden Sie unter Vorlagenobjekte.
Anmerkung zu Dokumenten mit mehreren Seiten
Wenn Ihr PDF-Dokument mehrere Seiten hat und Sie auf einer bestimmten Seite einen automatischen Tabellenvorschlag übernehmen, erhalten Sie ein Gruppieren/Filtern-Objekt nur für diese Seite. Wenn auch andere Seiten des Dokuments inkludiert werden sollen, können Sie das Gruppieren/Filtern-Objekt entsprechend konfigurieren.
Baumstruktur und Daten im Ausgabefenster
Gleichzeitig mit der Baumstruktur der Extraktionsregeln im Schemafenster erscheint im Ausgabefenster die Baumstruktur mit den aus der Tabelle extrahierten Daten (siehe Auszug aus dem Codefragment unten).
<Invoice>
<Row>
<Col1>Description</Col1>
<Col2>Hours</Col2>
<Col3>Rate ($/hr)</Col3>
<Col4>Amount ($)</Col4>
</Row>
<Row>
<Col1>Garden design</Col1>
<Col2>6</Col2>
<Col3>50</Col3>
<Col4>300</Col4>
</Row>
<...>
</Invoice>
Um zu überprüfen, ob die Struktur des Ausgabefensters den Objekten entspricht, klicken Sie im Ausgabefenster auf ein Element oder seinen Wert. Daraufhin werden die entsprechende Instanz des Objekts gelb und die Ränder der einzelnen Instanzen des Objekts im PDF-Ansichtsfenster pink markiert und das entsprechende Objekt wird in der Modellstruktur des Schema-Fensters markiert (Abbildungen unten).
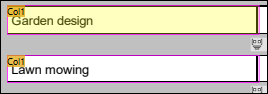
Markierte Zelle im PDF-Ansichtsfenster
Markiertes Objekt im Schema-Fenster
Anpassen der Tabellendaten
Die Tabelle in diesem Tutorial hat Spaltenüberschriften, die nicht in unsere Vorlage inkludiert werden sollen. Um die Kopfzeile auszunehmen, gehen Sie vor, wie unten beschrieben:
1.Klicken Sie im Schemafenster auf die vertikale Zuweisung TableTop.
2.Klicken Sie im PDF-Ansichtsfenster in der Tabelle auf die Beschriftung TableTop. Daraufhin erscheint ein Doppelpfeil (Abbildung unten), über den Sie die Position der TableTop-Linie der Tabelle anpassen können. Die TableTop-Linie in unserem Beispiel wurde nach unten gezogen, um die Kopfzeile der Tabelle zu exkludieren, wodurch auch die Namen der Spaltenüberschriften aus der Ausgabe ausgeschlossen wurden.

Geben Sie den Zeilen und Tabellenspalten beschreibende Namen
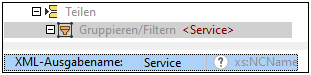
Das Teilen-Objekt im Schemafenster enthält ein Gruppieren/Filtern-Objekt mit dem Standardnamen Row. Um den Namen der Zeile zu ändern, klicken Sie in der Struktur auf den Node "Gruppieren/Filtern", geben Sie im Eigenschaftsfenster in das Feld XML-Ausgabename den Text Service ein und drücken Sie die Eingabetaste. Der Node "Gruppieren/Filtern" sieht nun folgendermaßen aus:
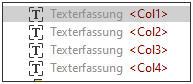
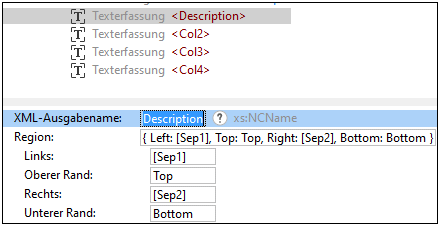
Die Standardnamen von Tabellenspalten sind Col1, Col2, usw. Um die Standardnamen von Spalten zu ändern, klicken Sie im Schema-Fenster auf das gewünschte Texterfassungselement und geben Sie im Eigenschaftsfenster in das Feld XML-Ausgabename einen neuen Namen ein. Der Name der ersten Spalte in diesem Tutorial is Description (Abbildung unten). Neben dem neuen Namen der Spalte sehen Sie auch die Position der Region im PDF-Dokument.
Wenn im Eigenschaftsfenster ein Objektname geändert wird, ändert sich auch die Textbeschriftung im PDF-Ansichtsfenster (Abbildung unten). Wenn Sie im Schemafenster auf ein Objekt klicken, wird seine Position in PDF-Ansichtsfenster markiert. So wurden etwa in der Abbildung unten die Zellen mit den Description-Beschriftungen pink markiert.

Im nächsten Schritt werden wir nun die Texterfassungen Col2, Col3 und Col4 in Hours, Rate bzw. Amount ändern.
Definieren anderer Extraktionsregeln auf manuelle Art
Neben den extrahierten Tabellendaten möchten wir auch Informationen über den Rechnungsnamen, den Kunden, Rechnungsnummer und -datum, Preis und Steuer sowie die Zahlungsbedingungen inkludieren. Diese Informationen werden wir nun manuell extrahieren. Es wird davon ausgegangen, dass die Informationen über den Auftragnehmer auf allen von dieser Firma ausgestellten Rechnungen die gleichen sind und für die Vorlage und das zukünftige Mapping nicht relevant sind. Daher werden die Informationen über den Auftragnehmer nicht in die Vorlage inkludiert.
Um PDF-Daten manuell zu extrahieren, gehen Sie folgendermaßen vor:
1.Klicken Sie auf das Root-Element oder das Objekt "Gruppieren/Filtern" unter dem Root-Node, um das gesamte PDF-Dokument zu sehen.
2.Die erste Information, die extrahiert wird, ist die Überschrift: Ziehen Sie ein Rechteck auf, das die gesamte Überschrift enthält (Abbildung unten).
3.Klicken Sie mit der rechten Maustaste auf das Rechteck und wählen Sie im Kontextmenü den Befehl Texterfassung (Abbildung unten).

4.Daraufhin wird im Schemafenster in der Struktur ein neuer erfasster Text mit dem Standardnamen Capture angezeigt. Standardmäßig wird ein neu erfasster Text im Schemafenster am unteren Rand der Struktur eingefügt. Da dieser erfasste Text der Rechnungsüberschrift entspricht, ist die logische Position des Texts im oberen Bereich der Struktur. Drücken Sie daher auf den neu erfassten Text, ziehen Sie ihn an den oberen Rand der Struktur und fügen Sie ihn vor dem Teilen-Objekt ein, wie in der Abbildung unten gezeigt.
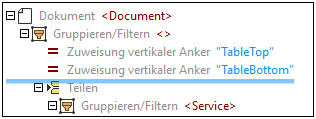
5.Ändern Sie den Namen des erfassten Texts: Klicken Sie im Schemafenster auf den erfassten Text, geben Sie in das Feld XML-Ausgabename Header ein und drücken Sie die Eingabetaste.
6.Als nächstes werden wir nun die Kundendaten extrahieren: Ziehen Sie ein Rechteck auf, das alle Kundendaten enthält (Abbildung unten), klicken Sie mit der rechten Maustaste auf das Rechteck und wählen Sie im Kontextmenü den Befehl Texterfassung erstellen. Alternativ dazu könnten Sie auch separate Texterfassungen für jede Information (z.B. ClientName, Address, usw.) erstellen. Wir haben aus Gründen der Einfachheit alle Kundendaten als eine einzige Informationseinheit behandelt.

7.Geben Sie dem neu erfassten Text einen Namen BillTo und ziehen Sie das Element unter die Texterfassung Header.
8.Wiederholen Sie die obigen Schritte, um weitere neue Texterfassungen für die Rechnungsnummer und das Datum zu erstellen, geben Sie ihnen den Namen InvoiceNo bzw. Date, und platzieren Sie diese unter die Texterfassung BillTo.
9.Erstellen Sie anschließend Erfassungen für die Werte der Zellen Subtotal, Sales Tax und Total und den Text unter Terms and Conditions, geben Sie diesen erfassten Texten Namen (in unserem Beispiel Subtotal, Tax, Total und Terms) und belassen Sie sie am unteren Rand der Struktur.
10.Überprüfen Sie, ob die Struktur im Ausgabefenster dem gewünschten Ergebnis entspricht.
Speichern der Vorlage
Der letzte Schritt beim Vorlagendesign ist das Speichern der Vorlage. Gehen Sie dazu folgendermaßen vor:
1.Klicken Sie im Menü Datei auf Speichern oder Speichern unter. Klicken Sie alternativ dazu auf die Symbolleisten-Schaltfläche ![]() .
.
2.Geben Sie Ihrer neuen Vorlage im daraufhin angezeigten Dialogfeld Speichern unter einen Namen und wählen Sie den Ordner aus, in dem die Vorlage gespeichert werden soll. In unserem Beispiel hat die Vorlage den Namen GardenInvoice.pxt.
3.Klicken Sie zur Bestätigung auf Speichern.
Die Vorlage kann nun in MapForce importiert werden. Nähere Informationen dazu finden Sie unter Importieren der Vorlage in MapForce.