Gescannte Dokumente (OCR)
Der MapForce PDF Extractor kann gescannte PDF-Dokumente einer optischen Zeichenerkennung (OCR) unterziehen, sodass Sie Text aus diesen Dokumenten extrahieren können. Dieses Kapitel enthält eine Übersicht über die Struktur von OCR-Dokumenten sowie eine Beschreibung der OCR-Objekte.
Die OCR-Funktionen im PDF Extractor basieren auf der Tesseract OCR und sind als Vorverarbeitungsschritt in das Produkt integriert.
Übersicht über die Struktur eines OCR-Dokuments
Der PDF Extractor behandelt ein gescanntes PDF-Dokument als strukturiertes Objekt namens Dokument, welches in Seiten unterteilt ist. Jede Seite enthält einen Scan-Bereich und ErkannteWörter und kann auch Benutzerwörter enthalten. In der Modellstruktur unten sehen Sie die Hierarchie von OCR-Objekten:
Dokument
Seiten
Seite
Benutzerwort
Scan-Bereich
ErkanntesWort
Unten finden Sie eine Beschreibung der wichtigsten Eigenschaften der einzelnen Objekte:
•Dokument: Enthält eine Liste von Seiten.
•Seite: Enthält Benutzerwörter, Scan-Bereiche und ErkannteWörter. Standardmäßig gibt es für jede Seite in einem Dokument ein Seiten-Objekt.
•Scan-Bereich: Definiert den von OCR gescannten Bereich. Standardmäßig gibt es pro Seite einen Scan-Bereich; der Scan-Bereich umfasst die gesamte Seite und ist auf den Seitensegmenierungsmodus "Sparse Text" gesetzt (nähere Informationen siehe unten).
•Benutzerwort: Manuell eingegebene Wörter.
•ErkanntesWort: Automatisch von OCR erkannte Wörter. Wenn Sie ein ErkanntesWort bearbeiten, wird es zu einem Benutzerwort. ErkannteWörter können inkludiert, ausgenommen oder bei Bedarf durch ein Benutzerwort ersetzt werden.
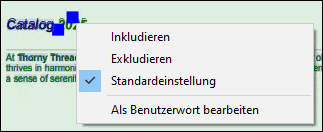
Kontextmenü von ErkanntenWörtern
Jedes ErkannteWort hat ein Kontextmenü (Abbildung unten), über das Sie folgende Möglichkeiten haben:
•Sie können das ErkannteWort explizit inkludieren oder exkludieren. Der OCR-Prozessor erkennt ein Wort möglicherweise korrekt, weist ihm aber nur 20 % Vertrauenswürdigkeit zu. In diesem Fall sollten Sie das Wort eventuell manuell inkludieren. Es kann auch vorkommen, dass der Prozessor ein Wort falsch erkennt. In diesem Fall müssen Sie es ausschließen.
•Wählen Sie die Standardoption aus, mit der der OCR-Prozessor selbst entscheidet, was inkludiert oder exkludiert werden soll. Erkannte Wörter werden automatisch inkludiert, wenn die Vertrauenswürdigkeit hoch genug ist (≥ 50%). ErkannteWörter werden ausgeschlossen, wenn sie hinter einem anderen Scan-Bereich verborgen sind.
•ErkannteWörter werden als Benutzerwörter bearbeitet. Um ein ErkanntesWort zu bearbeiten, könne Sie im Scan-Bereich des PDF-Dokument auch darauf doppelklicken.
Eigenschaften von Scan-Bereich
Das Objekt "Scan-Bereich" hat die folgenden Eigenschaften:
•Sprache
•Prozessormodus
•Seitensegmentierung
•Parameter
Sprache
Definiert die von Tesseract verwendete Sprachdatendatei. Damit wird sichergestellt, dass der OCR-Prozessor das korrekte Alphabet und die richtigen Sprachregeln (z.B. Deutsch) erkennt. Standardmäßig unterstützt der PDF Extractor die folgenden Optionen:
•deu
•eng
•fra
•jpn
•spa
Die meisten Sprachen, für die das lateinische Alphabet verwendet wird, können mit der Option eng erfolgreich verarbeitet werden. Falls die Erkennung Ihrer Sprache nicht korrekt ist, müssen Sie eventuell eine zusätzliche Sprachdatendatei herunterladen:
1.Laden Sie die entsprechende Sprachdatendatei (z.B. grc.traineddata) von der folgenden Seite herunter:
https://github.com/tesseract-ocr/tessdata_fast
2.Kopieren Sie die Sprachdatendatei in den folgenden Ordner:
C:\ProgramData\Altova\SharedBetweenVersions\TesseractFiles
3.Setzen Sie den Sprachparameter im Eigenschaftsfenster auf die neue Sprache (zB. grc).
Prozessormodus
Definiert, welchen Erkennungsprozessor Tesseract verwendet:
•Standard: Lässt Tesseract den Modus automatisch auswählen.
•Nur LSTM (Standardeinstellung): Verwendet den neueren auf einem neuronalen Netzwerk basierenden Prozessor. Der PDF Extractor wird mit dem "Nur LSTM"-Paket installiert und unterstützt fünf Sprachen (nähere Informationen siehe oben).
•Nur Tesseract: Verwendet den älteren Prozessor.
•LSTM kombiniert mit Tesseract: Führt beide Prozessoren gemeinsam aus, um potenziell verlässlichere Ergebnisse zu erzielen.
Wenn Sie die Option "Tesseract" verwenden möchten, gehen Sie vor, wie unten beschrieben:
1.Machen Sie eine Kopie der bestehenden Tesseract-Dateien, falls Sie diese zu einem späteren Zeitpunkt wiederherstellen möchten. Die Dateien befinden sich im folgenden Ordner:
C:\ProgramData\Altova\SharedBetweenVersions\TesseractFiles
2.Laden Sie die entsprechenden Trainingsdaten für die Option "Tesseract" herunter:
https://github.com/tesseract-ocr/tessdata
3.Ersetzen Sie die alten Tesseract-Dateien durch die neuen.
Speichern Sie alternativ dazu die heruntergeladenen Dateien in einem neuen Ordner und bearbeiten Sie den Standardpfad von TesseractData im Registry Editor im folgenden Registry Key:
Computer\HKEY_LOCAL_MACHINE\SOFTWARE\Altova\MapForce PDF Extractor\Settings
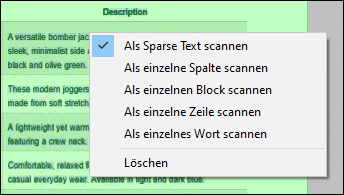
Seitensegmentierung
Legt fest, wie Tesseract das Layout des Texts im Scan-Bereich interpretiert. Es stehen die folgenden Optionen zur Verfügung:
•Standard: Lässt Tesseract den Modus automatisch auswählen.
•Auto: Automatische Seitensegmentierung; keine Ausrichtung oder Skripterkennung (Schriftsysteme wie Lateinisch, Arabisch, usw.).
•Auto mit OSD: Automatische Segmentierung mit Ausrichtung und Skripterkennung (Schriftsystemerkennung).
•Einzelner Block: Behandelt den Bereich als einzelnen Block (wie einen Absatz).
•Einzelner Block vertikalen Texts: Behandelt den Bereich als einen einzelnen Block aus vertikalem Text (wird außer in Sonderfällen wie bei bestimmten Tabellen selten verwendet).
•Einzelne Spalte: Geht von einer einzigen Spalte mit Text unterschiedlicher Größe aus.
•Einzelne Zeile: Behandelt den Bereich als eine einzige Textzeile.
•Einzelnes Wort: Behandelt den Bereich als ein einzelnes Wort.
•Sparse Text (Standardeinstellung): Erkennt Text an zufälligen Positionen ohne bestimmte Reihenfolge; ist nützlich für Zeichenerkennung auf der gesamten Seite.
•Sparse Text mit OSD: Wie oben, erkennt jedoch auch Ausrichtung und Schriftsystem (Skript).
Die Auswahl des richtigen Segmentierungsmodus kann die Genauigkeit der Erkennung verbessern. Wenn ein Bereich z.B. nur eine einzige Zeile enthält, erhalten Sie mit Einzelne Zeile oft bessere Ergebnisse als mit Sparse Text. Bei allgemeinen Dokumenten ist Sparse Text oft die beste Option.
Die Seitensegmentierungsmodi stehen auch über das Kontextmenü zur Verfügung, das aufgerufen wird, wenn Sie auf einen leeren Bereich des Scan-Bereichs des PDF-Dokuments klicken (Abbildung unten).
Parameter
Optionen, die Sie direkt an Tesseract übergeben können. Mit Hilfe dieser Parameter können Sie eine Feinabstimmung des OCR-Verhaltens vornehmen: So können Sie die Zeichenerkennung etwa auf bestimmte Zeichen einschränken (z.B. tessedit_char_whitelist=0123456789, um nur Zahlen zu erkennen). Sie können mehrere Parameter, jeweils als Schlüssel–Wert-Paar hinzufügen.
Tesseract unterstützt viele Parameter, doch sind nicht alle davon für die normale PDF-Extraktion nützlich. Einige nützliche Parameter:
•tessedit_zero_rejection – deaktiviert die Ablehnung unklarer Zeichen.
•tessedit_no_rejects – Verhindert, dass Wörter abgelehnt werden, selbst wenn die Zuverlässigkeit gering ist.
•tessedit_char_blacklist – Schließt bestimmte Zeichen von der Erkennung aus.
•tessedit_char_whitelist – Schränkt die Erkennung auf einen bestimmten Zeichensatz ein.
•tessedit_char_unblacklist – Macht die Erkennung zuvor ausgeschlossener Zeichen wieder aktiv.
•chs_leading_punct – Definiert am Beginn eines Worts zulässige Interpunktionszeichen.
•chs_trailing_punct1 – Definiert am Ende eines Worts zulässige Interpunktionszeichen.
•chs_trailing_punct2 – Definiert Interpunktionszeichen, die nach chs_trailing_punct1 erscheinen können.
•numeric_punctuation – Definiert Interpunktionssymbole, die als Teil einer Zahl behandelt werden.
Nachdem Sie eine Einstellung im Eigenschaftsfenster geändert haben, klicken Sie auf Anwenden, um die Änderungen zu übernehmen.
Nützliche Links
Nähere Informationen zu verschiedenen Tesseract-Optionen finden Sie in der Tesseract Class Reference und unter All Tesseract OCR Options. Allgemeine Informationen zu Tesseract finden Sie im Tesseract User Manual.
Neuer Scan-Bereich
Sie können einen neuen Scan-Bereich folgendermaßen hinzufügen:
1.Ziehen Sie über dem gewünschten Bereich ein Rechteck auf.
2.Klicken Sie mit der rechten Maustaste auf die Auswahl und wählen Sie den Seitensegmentierungsmodus aus (Beschreibung siehe oben).
3.Konfigurieren Sie die Eigenschaften des neuen Scan-Bereichs nach Bedarf.
OCR-Arbeitsablauf
Eine allgemeine Beschreibung der OCR-Verfahren im PDF Extractor finden Sie unter OCR-Arbeitsablauf. Ein Schritt-für-Schritt-Beispiel dazu finden Sie im Tutorial.