Beispiel: Lesen von XML-Dokumenten (Java)
Nachdem Sie anhand des Beispielschemas) Code generiert haben, wird ein Java-Testprojekt sowie eine Reihe von unterstützenden Altova-Bibliotheken generiert.
Informationen zu den generierten Java-Bibliotheken
Die zentrale Klasse des generierten Codes ist die Klasse Doc2. Sie repräsentiert das XML-Dokument. Eine solche Klasse wird für jedes Schema generiert. Ihr Name hängt vom Namen der Schemadatei ab. Beachten Sie, dass diese Klasse den Namen Doc2 erhält, um einen möglichen Konflikt mit dem Namespace-Namen zu vermeiden. Wie im Diagramm gezeigt, bietet diese Klasse Methoden zum Laden von Dokumenten aus Dateien, Binär-Streams oder Strings (oder zum Speichern von Dokumenten in Dateien, Streams, Strings). In der Referenz zur Klasse com.[YourSchema].[Doc] finden Sie eine Beschreibung dieser Klasse.
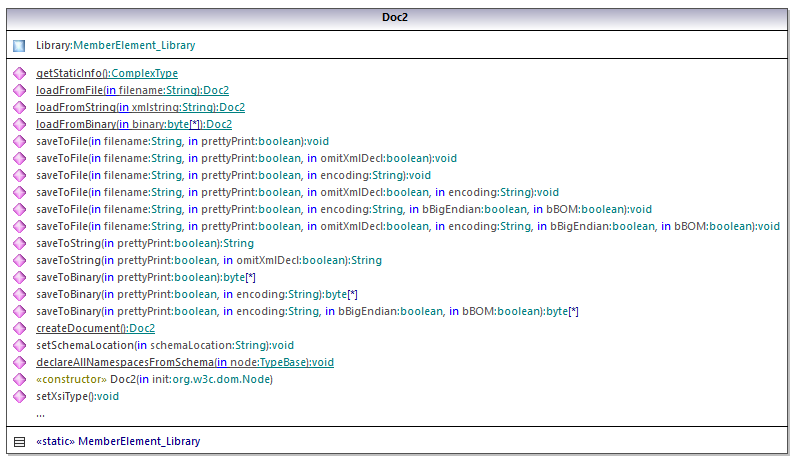
Der Member Library der Klasse Doc2 stellt die eigentliche Root des Dokuments dar.
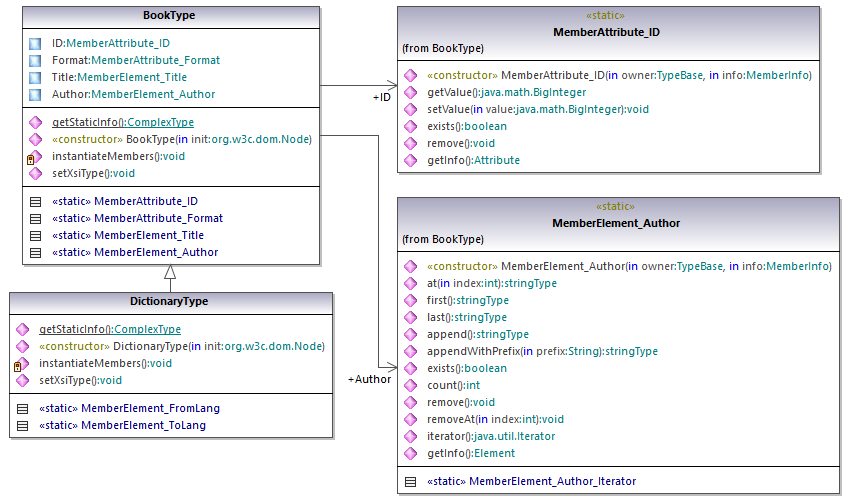
Gemäß den im Kapitel Informationen zu Schema Wrapper-Bibliotheken (Java) angeführten Codegenerierungsregeln werden für jedes Attribut und jedes Element eines Typs Member-Klassen generiert. Der Name solcher Member-Klassen erhält im generierten Code das Präfix MemberAttribute_ bzw. MemberElement_. Im Diagramm unten sind Beispiele für solche Klassen MemberAttribute_ID und MemberElement_Author, die anhand des Elements Author bzw. des Attributs ID eines Buchs generiert wurden. Sie ermöglichen die programmatische Bearbeitung (z.B. Anhängen, Entfernen, Wert definieren, usw.) der entsprechenden Elemente und Attribute im XML-Instanzdokument. Nähere Informationen dazu finden Sie in der Referenz zur Klasse unter com.[YourSchema].[YourSchemaType].MemberAttribute und com.[YourSchema].[YourSchemaType].MemberElement.
Der Typ DictionaryType ist ein complexType, der im Schema von BookType abgeleitet wurde, daher wird diese Beziehung auch in den generierten Klassen übernommen. Im Diagramm unten sehen Sie, dass die Klasse DictionaryType die Klasse BookType erbt.
Wenn in Ihrem XML-Schema simpleTypes als Enumerationen definiert sind, so stehen die enumerierten Werte im generierten Code als Enum-Werte zur Verfügung. In dem in diesem Beispiel verwendeten Schema gibt es die Buchformate hardcover, paperback, e-book, usw. Im generierten Code stehen diese Werte folglich in Form einer Enum, d.h. als Member der Klasse CBookFormatType, zur Verfügung.
Schreiben eines XML-Dokuments
1.Klicken Sie im Menü File von Eclipse auf Import, wählen Sie Existing Projects into Workspace, und klicken Sie auf Next.
2.Klicken Sie neben Select root directory auf Browse, wählen Sie das Verzeichnis, in dem der Java-Code generiert werden soll aus und klicken Sie auf Finish.
3.Erweitern Sie im Eclipse Package Explorer das Paket com.LibraryTest und öffnen Sie die Datei LibraryTest.java.
Beim Erstellen eines Prototyps einer Applikation anhand eines häufig geänderten XML-Schemas müssen Sie eventuell immer wieder Code im selben Verzeichnis generieren, damit die Änderungen am Schema sofort im Code berücksichtigt werden. Beachten Sie, dass die generierte Testapplikation und die Altova-Bibliotheken jedes Mal, wenn Sie Code im selben Zielverzeichnis generieren, überschrieben werden. Fügen Sie daher keinen Code zur generierten Testapplikation hinzu, sondern integrieren Sie stattdessen die Altova-Bibliotheken in Ihr Projekt (siehe Integrieren von Schema Wrapper-Bibliotheken). |
4.Bearbeiten Sie die Methode Example() wie unten gezeigt.
protected static void example() throws Exception { |
5.Bauen Sie das Java-Projekt und führen Sie es aus. Wenn der Code erfolgreich ausgeführt wurde, wird im Projektverzeichnis die Datei Library1.xml erstellt.
Lesen eines XML-Dokuments
1.Klicken Sie im Menü File von Eclipse auf Import, wählen Sie Existing Projects into Workspace, und klicken Sie auf Next.
2.Klicken Sie neben Select root directory auf Browse, wählen Sie das Verzeichnis, in dem der Java-Code generiert werden soll aus und klicken Sie auf Finish.
3.Speichern Sie den unten gezeigten Code unter dem Namen Library1.xml in einem lokalen Verzeichnis (Sie müssen den Pfad der Datei Library1.xml aus dem Beispielcode unten referenzieren).
<?xml version="1.0" encoding="utf-8"?> |
4.Erweitern Sie im Eclipse Package Explorer das Paket com.LibraryTest und öffnen Sie die Datei LibraryTest.java.
5.Bearbeiten Sie die Methode Example() wie unten gezeigt.
protected static void example() throws Exception { |
6.Bauen Sie das Java-Projekt und führen Sie es aus. Wenn der Code erfolgreich ausgeführt wurde, wird Library1.xml vom Programmcode gelesen und ihr Inhalt in der Konsolenansicht angezeigt.
Lesen und Schreiben von Elemente und Attributen
Die Werte von Attributen und Elementen können über die Methode getValue() der generierten Member-Element- bzw. Attribut-Klasse aufgerufen werden, z.B.:
// output values of ID attribute and (first and only) title element |
Um in diesem konkreten Beispiel den Wert des Elements Title abzurufen, haben wir auch die Methode First() verwendet, da es sich hier um des erste (und einzige) Title-Element eines Buchs handelt. In Fällen, in denen ein bestimmtes Element nach dem Index aus einer Liste gewählt werden soll, verwenden Sie die Methode At().
Um über mehrere Elemente zu iterieren, verwenden Sie entweder eine Index-basierte Iteration oder java.util.Iterator. So können Sie etwa folgendermaßen über die Bücher einer Bibliothek iterieren:
// index-based iteration |
Mit Hilfe der Methode Append()können Sie ein neues Element hinzufügen. Im folgenden Code wird z.B. ein leeres Root-Element Library an das Dokument angehängt:
// create the root element <Library> and add it to the document |
Nachdem ein Element angehängt wurde, können Sie den Wert eines seiner Elemente oder Attribute mit Hilfe der setValue()-Methode definieren:
// set the value of the Title element |
Lesen und Schreiben von Enumerationswerten
Wenn in Ihrem XML-Schema simpleTypes als Enumerationen definiert sind, so stehen die enumerierten Werte im generierten Code als Enum-Werte zur Verfügung. In dem in diesem Beispiel verwendeten Schema gibt es die Buchformate hardcover, paperback, e-book, usw. Im generierten Code stehen diese Werte folglich in Form einer Enum zur Verfügung (siehe die Klasse BookFormatType im Diagramm oben). Mit Hilfe von Code wie dem unten gezeigten können Sie einem Objekt Enumerationswerte zuweisen:
// set an enumeration value |
Solche Enumerationswerte können folgendermaßen aus XML-Instanzdokumenten ausgelesen werden:
// read an enumeration value |
Wenn eine "if"-Bedingung nicht genügt, erstellen Sie einen Switch, um jeden Enumerationswert zu ermitteln und wie erforderlich zu verarbeiten.
Arbeiten mit den Typen xs:dateTime und xs:duration
Wenn im Schema, anhand dessen Sie Code generiert haben, Uhrzeit- und Zeitdauer-Typen wie xs:dateTime oder xs:duration vorkommen, so werden diese im generierten Code in native Altova-Klassen konvertiert. Gehen Sie daher folgendermaßen vor, um einen Datums- oder Zeitdauerwert in das XML-Dokument zu schreiben:
1.Erstellen Sie ein com.altova.types.DateTime- oder com.altova.types.Duration-Objekt.
2.Definieren Sie das Objekt als Wert des benötigten Elements oder Attributs, z.B.:
// set the value of an attribute of DateTime type |
Um ein Datum oder eine Zeitdauer aus einem XML-Dokument zu lesen, gehen Sie folgendermaßen vor:
1.Deklarieren Sie den Elementwert (oder den Attributwert) als com.altova.types.DateTime- oder com.altova.types.Duration-Objekt.
2.Formatieren Sie das benötige Element oder Attribut, z.B.:
// read a DateTime type |
Nähere Informationen dazu finde Sie in der Referenz zu den Klassen com.altova.types.DateTime und com.altova.types.Duration.
Arbeiten mit abgeleiteten Typen
Wenn in Ihrem XML-Schema abgeleitete Typen (derived types) definiert sind, so können Sie die Typableitung in programmatisch erstellten oder geladenen XML-Dokumenten beibehalten. Im folgenden Codefragment wird gezeigt, wie Sie anhand des in diesem Beispiel verwendeten Schemas ein neues Buch mit dem abgeleiteten Typ DictionaryType erstellen.
// create a dictionary (book of derived type) and populate its elements and attributes |
Beachten Sie, dass es wichtig ist, dass Sie das xsi:type Attribut des neu erstellten Buchs definieren. Damit stellen Sie sicher, dass der Buchtyp korrekt vom Schema interpretiert wird, wenn das XML-Dokument validiert wird.
Im folgenden Codefragment gezeigt, wie ein Buch vom abgeleiteten Typ DictionaryType in der geladenen XML-Instanz identifiziert wird, wenn Sie Daten aus einem XML-Dokument laden. Zuerst wird im Code der Wert des xsi:type-Attributs des Buchs gefunden. Wenn die Namespace URI dieses Node http://www.nanonull.com/LibrarySample lautet und wenn das URI-Lookup-Präfix und der Typ mit dem Wert des xsi:type-Attributs übereinstimmen, so handelt es sich um ein Wörterbuch:
// find the derived type of this book |