| Ash |
| Member |
|
| United Kingdom |
|
|
| None Specified |
|
| Wednesday, August 21, 2019 |
| Monday, July 19, 2021 10:41:04 PM |
10
[0.05% of all post / 0.00 posts per day] |
|
Did you ever find a solution for this?? I'm attempting to do something very similar.
Much smaller files work perfectly fine, and it's fast... But as soon as you start matching 100's / 1000's of records, then we're talking 45 minutes to 1-2 hours.... I don't understand why?
|
Got it! Thank you very much.
Sometimes it either takes a simple explanation or some time away from the screen to understand where you're going wrong.
Just in case anyone else has similar issues, this was the solution.

Thanks again for your help!
|
Not quite that exact message, but similar
"Multiple values were mapped to Tariff Rate Identified (or TRID)."
"Multiple values were mapped to Tariff Rate ID (or TRID)."
I've tried connecting 'Filter' in a couple of places, but I can't seem to get the right combo... It still only seems to match the first record from the XLSX.
All others (although they match) are not 'changing'?
I connected the 'Filter' function to the parent node, and this resulted in all 'matches' appearing - but then anything that didn't match completely disappeared.
I feel like this is close...
I'm making the incorrect connections to 'Filter'? I'm not to sure how to utilize the 'Exists' function.
If I upload the files, would you mind taking a look? Only if you have time of course.
Thanks
[EDIT] I've added a link to the download. Here https://bit.ly/3vrEEOP
|
Hi,
I've been provided with a text file which I have split into a CSV using FlexText. This appears to be all ok.
The source of the file is also the output - but with some string manipulation in between (typical MapForce stuff).
I'm attempting to search a specific field from the text file, and match it against the XLSX file... If it matches, then another field should be changed.
The logic seems simple - but for some reason, it only appears to be searching the first row of the XLSX file? But I can't work out why?
Here are a couple of screenshots showing what I mean.
First screenshot shows my logic:
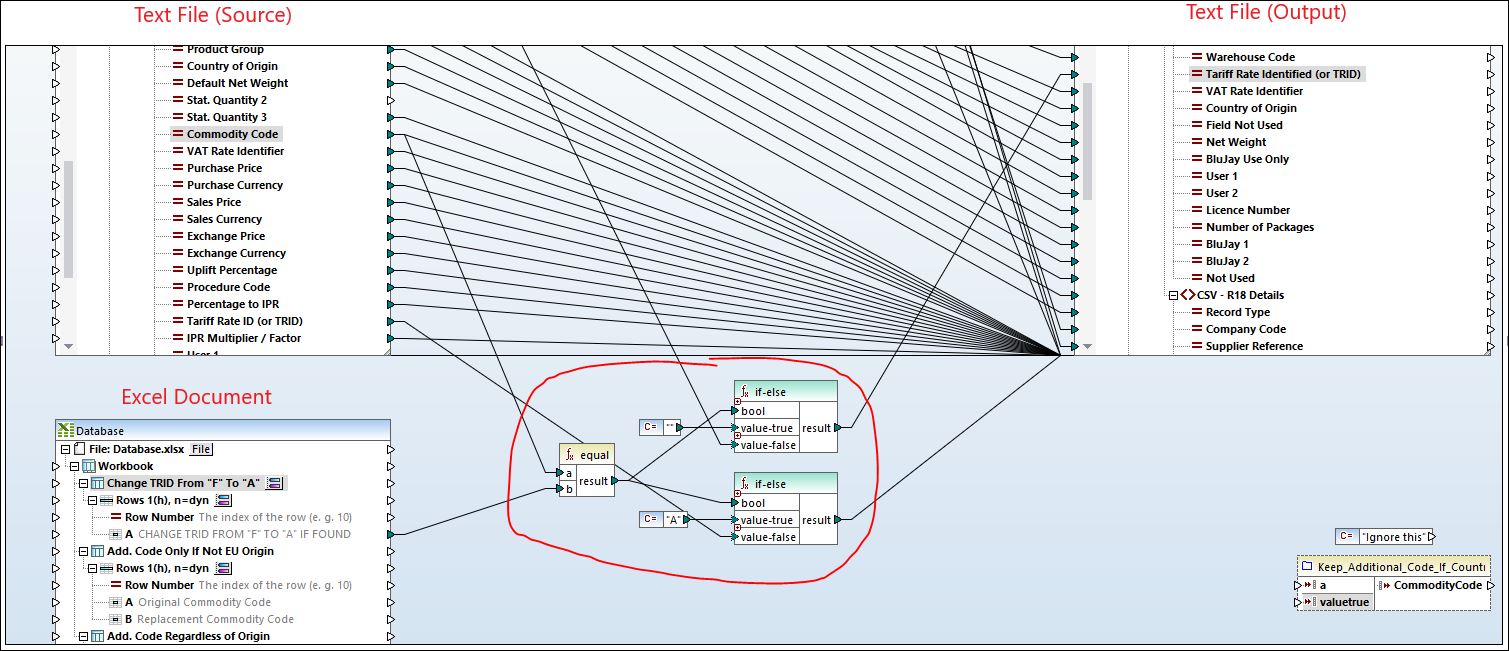
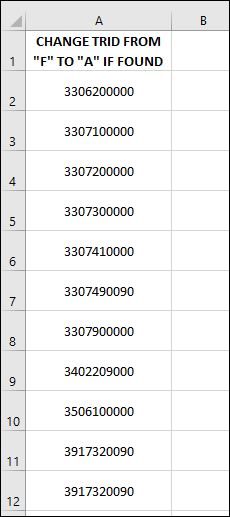
Second screenshot shows the layout of the XLSX file
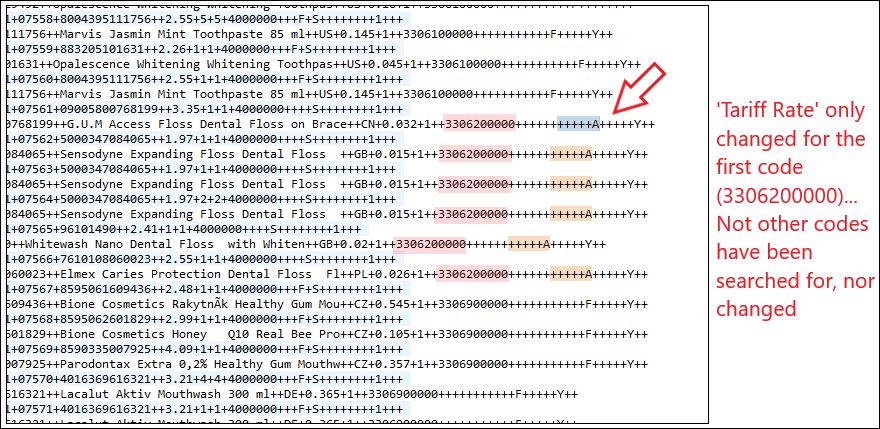
Third screenshot shows the output - showing that the criteria has been changed correctly... But only for the first code found in the XLSX list
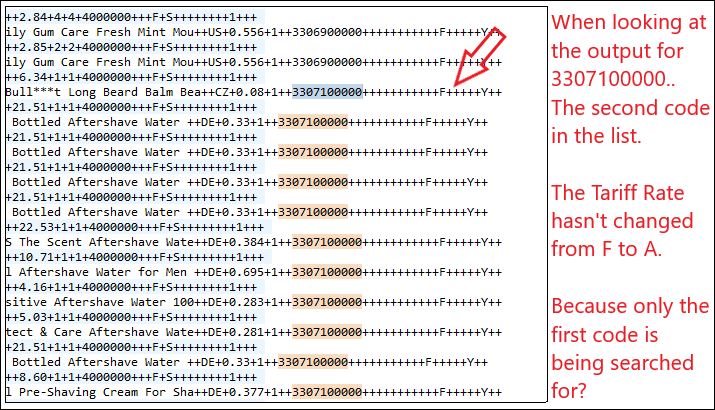
Fourth screenshot shows the output - showing that the criteria hasn't been changed... Even though the 'code' is the 2nd in the list.
|
|
Perfect, thank you very much!! Confirmed working.
|
Hi,
I'm mapping from one Excel file, to another Excel file. Essentially taking our customers data, and putting it into a format that our system will read.
There is a requirement that I need to dynamically list a set of numbers twice (on top of another).
I've managed to achieve this by using "Generate-Sequence" and "Replicate-Sequence". It gives me the desired result, as shown in the screenshots below.
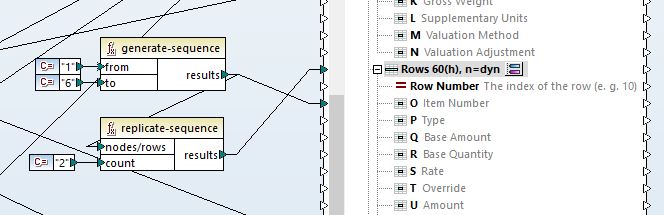
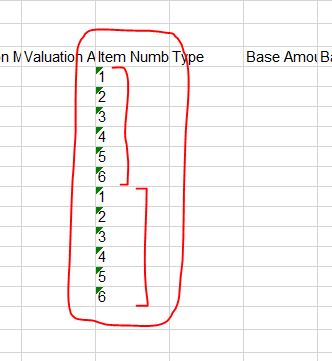
However, the issue that I'm having is that I'm now attempting to put A00 next to the first sequence of numbers and B00 next to the second sequence of numbers.
1 A00
2 A00
3 A00
4 A00
5 A00
6 A00
1 B00
2 B00
3 B00
4 B00
5 B00
6 B00
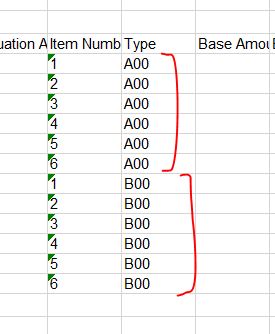
I've tried various combinations and various different functions, but I can't see to find a way of doing it.
Everything that I try only ends up with me having A00 next to all numbers (both sequences).
Is there a way of doing this?
Thank you in advance
|
That solution works perfectly K101 thank you very much!
|
I'll try to explain what I'm attempting to do.
I have a 'string' of words, and this string can be between 10 and 200 characters long.
I would like to find a way of splitting this string, but a maximum of 30 characters. But the string should not split in the middle of a word.
For this example, I've taken the below sentences from a 'random sentence generator' website
The fact that there's a stairway to heaven and a highway to hell explains life well. You can't compare apples and oranges, but what about bananas and plantains? As he looked out the window, he saw a clown walk by.
I will now mark out where the 30 character splits are:
The fact that there's a stairw|ay to heaven and a highway to |hell explains life well. You c|an't compare apples and orange|s, but what about bananas and |plantains? As he looked out th|e window, he saw a clown walk |by.
This is a problem, because the splits will looks like this:
1. The fact that there's a stairw
2. ay to heaven and a highway to
3. hell explains life well. You c
4. an't compare apples and orange
5. s, but what about bananas and
6. plantains? As he looked out th
7. e window, he saw a clown walk
8. by.
What I would like to do, is split these strings at the 'space' before the word thats being cut into (if that makes sense).... So like this:
The fact that there's a |stairway to heaven and a |highway to hell explains life |well. You can't compare apples |and oranges, but what about |bananas and plantains? As he |looked out the window, he saw |a clown walk by.
Resulting in the following splits:
1. The fact that there's a
2. stairway to heaven and a
3. highway to hell explains life
4. well. You can't compare apples
5. and oranges, but what about
6. bananas and plantains? As he
7. looked out the window, he saw
8. a clown walk by.
I hope this makes sense.
If someone can show me how to do this within MapForce that would be great.
Unfortunately I don't have any 'real' dummy data to hand, but essentially I'll be taking a string / splitting it (as per the example above) / and then placing it within an XML file.
But I just need to know how to achieve the above effect.
I've read that RegEx might be able to do it and I tried to achieve this by using RegEx... But I can't seem to get the RegEx to work? I don't know anything about RegEx, so I'm unable to debug it.
|
Hi,
I hope you can help.
=== EDITED VERSION ===
I'll ask a slightly different question...
If I have 10 Excel files, all files have a different unique reference in column B...
File 1 = Ref111
File 2 = Ref222
etc
How could I split these Excel files into smaller files that only contains 10 rows each?
If File 1 has 3 rows, then only one file should exist...
If File 2 has 65 rows, then 7 files should exist (6 files containing 10 rows each, and 1 file containing 5 rows).
I've tried a couple of different techniques ... But MapForce seems to be taking my source files, and creating files that are 30 rows (despite the reference).
Resulting in my target file looking like this:
Ref111
Ref111
Ref111
Ref222
Ref222
Ref222
Ref222
Ref222
etc
Whereas I want Ref111 to be in it's own file... And Ref222 to be in it's own 'set' of files.
File 1
Ref111
Ref111
Ref111
File 2 (Part 1 of 7)
Ref222
Ref222
Ref222
Ref222
Ref222
Ref222
Ref222
Ref222
Ref222
Ref222
File 2 (Part 2 or 7)
Ref222
Ref222
Ref222
Ref222
Ref222
Ref222
Ref222
Ref222
Ref222
Ref222
etc etc
I really hope that simplifies things? :-(
=== ORIGINAL POST ===
I have been provided with a small chunk of CSV data containing just 400 rows.
Within the CSV file is a reference number. This reference number can be spread across 5 rows or even 300 rows.
I have managed to take the CSV file, and create seperate Excel files for each of the unique references. Each Excel file will hold data relating to only that reference too.
But I would like to take this a step further.
I need to split the Excel files into several files which only contains 30 rows of data.
Meaning that if my original Excel file for Reference: "ISS130721", contained 100 rows of data, then I should have 4 Excel files.
3 Excel files containing 30 records each, and 1 remaining Excel file containing 10 records.
I would like the file name to be:
ISS130721- Part 1 of 4.xlsx
ISS130721- Part 2 of 4.xlsx
ISS130721- Part 3 of 4.xlsx
ISS130721- Part 4 of 4.xlsx
I could potentially have 200 to 300 excel files, so I would like the mapping to run through each file without having to change paths etc.
Here's a couple of screenshots which might help:
What the CSV file looks like:
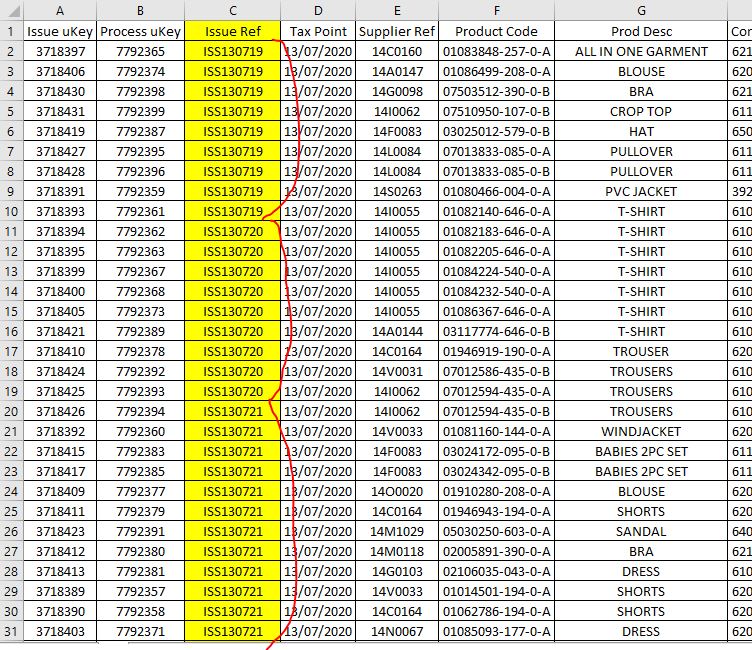
What the Excel files look like after splitting by Reference:
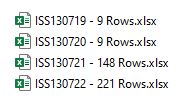
Depending on the amount of rows inside the Excel files, this is how I would like them split... Using the same filename structure if possible.
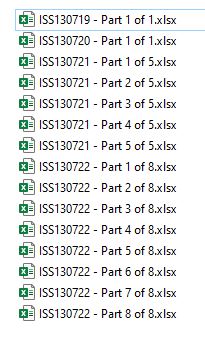
If the middle step of just creating the Excel files by reference can be skipped, then that would be ideal.
So going from the CSV file, straight to generating Excel files by 'unique reference' and '30 rows each' would be awesome!!
But if that's not possible, that's fine.
I have included a zip file containing my files. Since it would be easier to work with these rather than creating your own :)
https://1drv.ms/u/s!Am2W_9SKfEw1kFxlj0WvyC4PwpND?e=RrGVcD
Thank you so much.
|
|