Compare CSV and Database Data
You can compare data from CSV files or databases side-by-side. You can also perform mixed comparisons; for example, you can compare data from a CSV file with data from a database table. When comparing two databases, the objects to be compared can either belong to the same database, or reside in two different databases.
A database or CSV comparison is similar to file comparisons; that is, it involves a "left" component and a "right" one. A "component" is just a representation of the database structure from where you can conveniently select the tables or columns that are to be compared.
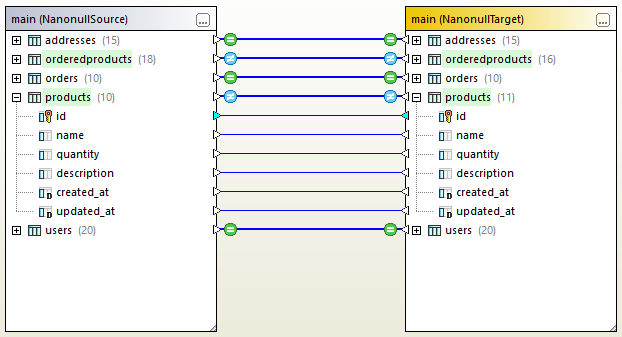
Database data comparison
In case of CSV files, the component includes only one table that represents the CSV file content. Each column corresponds to a CSV field. The column names correspond to header fields if the source CSV has a header row, and if you selected the First row is header row option when connecting to the CSV data source. If the CSV has no header row, columns are named automatically, for example, "c1", "c2", and so on.
After comparing data, you can optionally merge differences either from left to right, or from right to left. It is possible to merge all differences as one batch, or you can display the differences for each table in a data grid, and then review and merge each difference individually at row level. For more information, see Viewing Differences Between Tables and Merging CSV and Database Differences.
If you perform the same data comparison frequently, you can save it to a database data comparison (.dbdif) file, see Saving Comparison Files.
Prerequisites
•An active connection to a data source must exist in your project for each database table or file that is to be compared side-by-side. This data populates the "left" and "right" components, respectively. For more information, see Connecting to a Data Source. For CSV files, see Adding CSV Files as Data Source.
•If you are comparing tables, each table must have a primary key column. DiffDog requires the primary key column to sort the table rows before performing the actual comparison.
Limitations
•When comparing CSV files, the first column of each row is always considered the primary key column.
•If the primary key column is non-numeric, and if a change occurs in the key column, the entire row is treated as a new row. This applies both to CSV files and to database comparisons. Consider the following example:
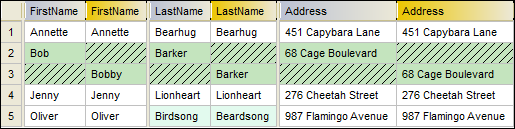
The comparison result illustrated above was obtained by comparing two CSV files. As mentioned before, the first column in CSV files is always the primary key. For this reason, even though value "Bob" has been renamed to "Bobby", this change is reported as a new row (rather than a difference in that particular column). On the other hand, the difference between "Birdsong" to "Beardsong" is displayed as a difference in the same row, because that column is not a primary key.
Database column icons
Database tables are represented by the ![]() icon. Database columns are represented by the
icon. Database columns are represented by the ![]() icon. If there is a constraint set for the column, the column's icon will have an additional symbol. If a column has more than one constraint assigned to it, only the constraint with the highest priority is shown in the column icon. The priority of constraints is described in the table below, starting with the highest priority.
icon. If there is a constraint set for the column, the column's icon will have an additional symbol. If a column has more than one constraint assigned to it, only the constraint with the highest priority is shown in the column icon. The priority of constraints is described in the table below, starting with the highest priority.
This column is used as the table's primary key. | |
This column has a unique constraint. | |
This column has a foreign key that references the primary key of a different table. | |
This column contains XML data. | |
There is a default value set for this column. If no value is supplied to this column, the default value will be inserted instead. |