Options for XML Comparison
The XML tab of the Comparison Options dialog box displays the options that are used for XML-based comparison.
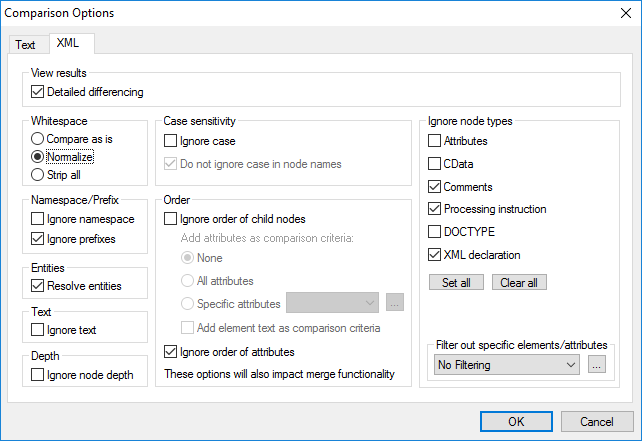
View results
The Detailed differencing option enables you to show differences in detail or reduce the number of differences (so that navigation is faster). With detailed differencing toggled off, consecutive nodes that are different are displayed as a single node. This applies also to consecutive nodes on different hierarchical levels, such as an element node and its child attribute node.
Note the following points:
•In Grid View, consecutive differences are counted together as one difference, whereas, in Text View, they are counted as separate differences. As a result, the count of differences in Text View might be higher.
•Detailed differencing must be selected to enable the merging and exporting of differences.
•This setting is not applicable XML DB data comparisons.
Whitespace
See Comparison Options for Whitespace Characters.
Namespace/Prefix
These are options for ignoring namespaces and prefixes when searching for differences.
Entities
If Resolve entities is selected, then all entities in the document are resolved. Otherwise the files are compared with the entities as is.
Text
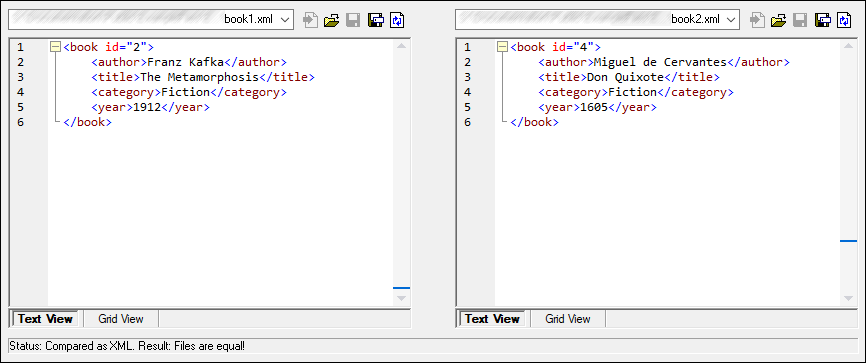
If Ignore text is selected, then differences in corresponding text nodes are not reported. Only the XML structure is compared but not the text content. This is useful when you want to compare two XML structures and disregard the actual content. For example, let's assume that the Ignore text check box is selected. In this case, the following two XML files are equal (even though their content differs).
Depth
If Ignore node depth is selected, then elements are treated as equal without regard to their depth. For example, let's assume that the check box Ignore node depth is selected. In this case, in a comparison like the one below, element <c> is equal on both sides, even though it is nested deeper on the right side.
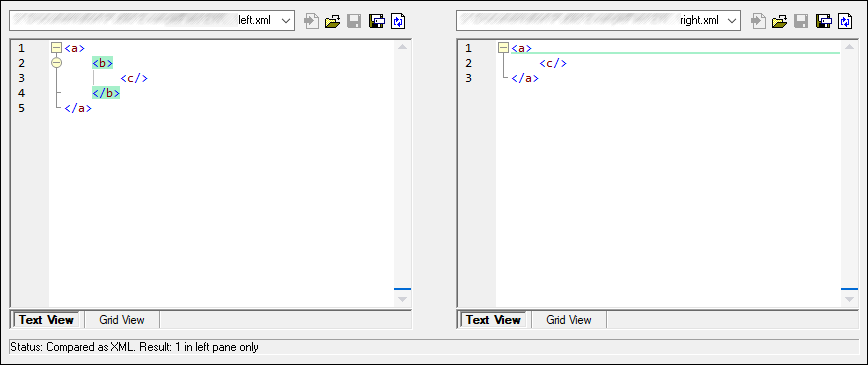
Note: When the Ignore node depth check box is selected, merging and exporting differences are not possible.
Case sensitivity
If the Ignore case check box is checked, then case is ignored, and you have the option of ignoring or not ignoring case in node names.
Order
If Ignore order of child nodes is selected, then the relative position of the child nodes of an element is ignored, provided that the individual nodes within a node level have unique node names. As long as an element node with the same name exists in each of the two sets of sibling nodes, the two sets are considered to be equal. In the following example, the order of the <Name> and <FirstName> nodes is different in the left and right file and is marked as different if the Ignore order of child nodes option is deactivated.

Checking the Ignore order of child nodes option will ignore this difference in the comparison window.

Note, however, that DiffDog can ignore the order of child nodes only if the node names on a certain node level are unique. If several occurrences of a node appear, e.g. with different attributes assigned, a node, if appearing in a different order, will always be considered unequal to an element with the same name and attribute in the compared sibling set—even if the Ignore order of child nodes is selected. If we add different attributes to the <Phone> node of our example, then the difference in order of the three occurrences of the <Phone> node will appear in the comparison window although the Ignore order of child nodes check box is selected.

In order to ignore the order of several occurrences of child nodes that have different attributes assigned, you can add these attributes as comparison criteria. DiffDog provides two options: (i) add all attributes and (ii) define a list of specific attributes, which in our example will both result in the <Phone> nodes being displayed as equal. However, if you select the Specific attributes option, you will first have to define an attribute group accordingly.

It may happen that several occurrences of child nodes appear that have also the same attribute assigned (e.g. a person with more than one mobile phone number in our example). In the image below, the All attributes radio button has been selected, however differences are still reported since two mobile phone numbers are listed.

In DiffDog you can cope also with this scenario by activating the Add element text as comparison criteria check box. If element text, attribute value, and node name are identical and only the order of the nodes is different, no differences will be reported.

Note that, if the Ignore Order option is specified, then the merge functionality also ignores the order. If Ignore order of child nodes is unselected, then differences in order are represented as differences.
The option of ignoring the order of attributes is also available, and applies to the order of attributes of a single element. In the above example, the Ignore order of attributes option has been checked and DiffDog, therefore, has ignored the order of the attributes of the <Person> node. Note that the order of attributes will always be ignored, if the Ignore order or child nodes check box is activated. In the screenshot below, both the Ignore order of child nodes and the Ignore order of attributes check box are deactivated.

Ignore node types
Check the node types that will not be compared in the Compare session. Node types that may be ignored are Attributes, CDATA, Comments, Processing Instructions, DOCTYPE statements, and XML declarations.
Filter out specific elements/attributes
Enables you to define filters to set what elements and/or attributes should not be considered for comparison. A filter is defined at the application level, which means that once a filter is defined, it is available for every comparison. More than one filter can be defined, and, for every comparison, the filter to be used is selected in the drop-down list in the Filter out specific elements/attributes group box.