Postpone Steps
A typical FlowForce job returns a result only after the processing of all steps has finished, assuming that no error has occurred. For jobs configured as Web services, this means that the HTTP transaction must be kept open for the entire duration of the job execution, which may take several minutes or even hours in some cases, depending on the amount of processed data. To handle such cases more efficiently, you can create postponed steps.
Postponed steps take place only after all non-postponed steps have been processed and the job has returned a result. Even though a job with postponed steps might return a result early, the job is considered in progress until the execution of all postponed steps has finished.
Add a Postpone step
You can create postponed steps anywhere in the job where a step is allowed. To add a postponed step, take the steps below:
1.Create a new job or open an existing one.
2.Click the new Postpone step button in the Execution steps section.
3.Click  inside the Postpone block to add a step or several steps that will be postponed.
inside the Postpone block to add a step or several steps that will be postponed.
Depending on your business needs, you can create Execution steps, Choose, For-Each, and Error/Success Handling blocks inside a Postpone block. You can also nest other Postpone blocks inside your Postpone block.
Error handling
A job can contain multiple Postpone blocks (each containing a step or several steps to be postponed) at various places in the job. Creating postponed steps might be useful for error handling: If an error occurs within a postponed block, other steps in the job will not be affected. A postponed block is like a mini-job and behaves in the same way as a regular job:
•If a step in a postponed block encounters an error, the step will be canceled, along with any subsequent steps in the same postponed block, and an error will be logged.
•Postponed blocks do not influence each other. In a job with multiple postponed blocks, a postponed block will run even if the preceding postponed block results in a failure.
•If a postponed step within a protected block encounters an error, all postponed steps that are part of that block will be canceled.
Possible scenarios
The subsections below describe some of the possible scenarios of using postponed steps.
Job with several postponed steps
The sample job below will run in the following order: A, C, B, D. The non-postponed steps are executed first, followed by the postponed steps. Step C returns a result.
A
postpone B
C
postpone D
Postpone steps in Choose steps
You can also add postponed steps to Choose steps. In this case, the postponed step will be run only if the respective When or Otherwise branch is run as well.
when expression=true
{
postpone A
B
C
}
otherwise
{
postpone D
E
F
}
In this job, if the expression is true, the steps will run in the following order: B, C*, A. Otherwise, the run order will be: E, F*, D. The asterisks indicate steps that return results.
Postpone steps in For-Each steps
The sample job below shows a For-Each step, in which the postponed steps will be processed after the non-postponed steps, in the same order as in the loop they are part of.
for each item in list
{
A
postpone B
}
For example, if the loop runs three times, the steps above will run in the following order: A1, A2, A3*, B1, B2, B3. The digits indicate loop numbers. The asterisk indicates a step that returns a result.
Postponed steps nested in postponed steps
You can also nest postponed steps within other postponed steps (see code listing below). In this case, outer steps of the same depth are processed first, and the nested postponed steps will be executed only after the processing of their parent sequence has finished. In our sample job, the steps will run in the following order: A, G, N, B, D, F, C, E, H, K, M, J, L. Step N returns a result.
A
postpone
[
B
postpone C
D
postpone E
F
]
G
postpone
[
H
postpone J
K
postpone L
M
]
N
If you need to create and test advanced configurations like the one above, you can always track the execution order of steps in the log.
Example
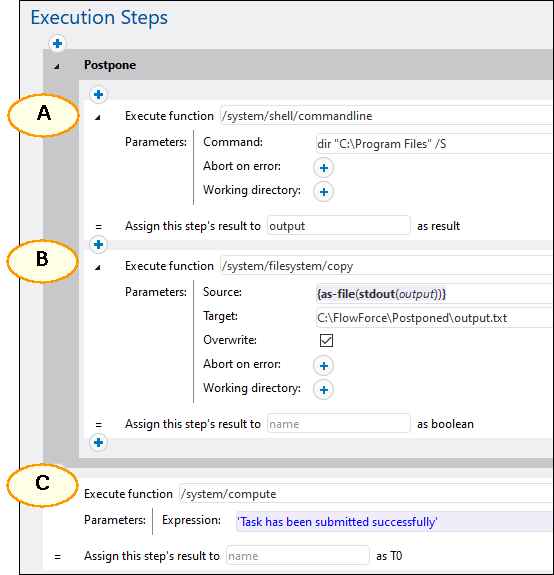
The example below illustrates a possible scenario in which postponed steps might be useful. This job is run as a Web service and can be invoked at any time by a client, including from the browser.
Step A runs a time-consuming shell command that lists recursively all the directories and files within a large system directory. For this reason, Step A is defined as a postponed step. Step B takes the standard output (stdout) produced by A and writes it to a file. Step B depends on the output produced by Step A and, therefore, has to be part of the postponed sequence, too. Step C informs callers of the service that the task has been submitted successfully. Whenever the Web service is called, the steps above will run in the following order: C, A, B. The reason for that is that A and B are postponed steps, so C is executed first.
The advantage of this configuration is that the job returns the result immediately after running Step C, and the HTTP transaction can end, freeing up server resources for other requests. After returning the result of the job, FlowForce will go on to run postponed Steps A and B.
When you invoke the job above in your browser, the message Task has been submitted successfully will be displayed in the browser. At the same time, the job continues running until it creates output.txt. If neither A nor B fails, the output file will be created at the following path: C:\FlowForce\Postponed\output.txt.
Note about step order
In our example, Step C has to be the last one in the job, because this step outputs the result to the browser. If you move Step C to the very top, it is still executed first, and Step B is still the last to be executed. However, this would change the job result, and the browser would display some empty output similar to []. The reason is that the result of a job is always the result of the last executed step. Postponed steps do not have a return value but produce an empty sequence instead.