Find, Find Next, Replace
The Find (Ctrl+F) command ![]() enables you to find text strings in Design View, JavaScript Editor, Authentic View, and XSLT stylesheets.
enables you to find text strings in Design View, JavaScript Editor, Authentic View, and XSLT stylesheets.
The Find & Replace dialog that is displayed depends on which view is currently active.
•When Design View is active, clicking the Find or Replace command will set the focus to the Find & Replace sidebar. The search and replace functionality of Design View is described in the topic Find & Replace sidebar.
•The search and replace functionality in JavaScript Editor, Authentic View, and XSLT stylesheets is described in this topic.
XSLT stylesheets and JavaScript Editor
Clicking the Find command in the XSLT-for-HTML, XSLT-for-RTF, XSLT-for-PDF, XSLT-for-Word 2007+, or JavaScript Editor tab displays the following dialog:

You can select from the following options:
•Match case: Case-sensitive search when toggled on (Address is not the same as address).
•Match whole word: Only the exact words in the text will be matched. For example, for the input string fit, with Match whole word toggled on, only the word fit will match the search string; the fit in fitness, for example, will not be matched.
•Regular expression: If toggeld on, the search term will be read as a regular expression. See Regular expressions below for a description of how regular expressions are used.
•Find anchor: When a search term is entered, the matches in the document are highlighted and one of these matches will be marked as the current selection. The Find anchor toggle determines whether that first current selection is made relative to the cursor position or not. If Find anchor is toggled on, then the first currently selected match will be the next match from the current cursor location. If Find anchor is toggled off, then the first currently selected match will be the first match in the document, starting from the top.
•Find in selection: When toggled on, locks the current text selection and restricts the search to the selection. Otherwise, the entire document is searched. Before selecting a new range of text, unlock the current selection by toggling off the Find in Selection option.
•Replace: In the JavaScript Editor tab, click the Down Arrow button, which is located at the top left of the dialog, to open the Replace field. Here you can enter the string that you want to substitute for the found string.
HTML Preview and Authentic View
Clicking the Find command in HTML Preview or Authentic View opens a simple Find and Replace dialog.
Note the following:
•To match the entry with whole words, check "Match whole word only". For example, an entry of soft will find only the whole word soft; it will not find, for example, the soft in software.
•To match the entry with fragments of words, leave the "Match whole word only" check box unchecked. Doing this would enable you, for example, to enter soft and software.
•To make the search case-insensitive, leave the "Match case" checkbox unchecked. This would enable you to find, say, Soft with an entry of soft.
•In Authentic View, the dynamic data (XML data) is searched, not text from the static (XSLT) input.
•The Replace functionality in Authentic View is straightforward, enabling you to replace a chosen text string with another. Available options are: (i) the matching of whole words only (not words in the text that contain the searched-for string), and (ii) the matching of words that have the same casing as the searched-for string.
Find Next command
The Find Next (F3) command ![]() repeats the last Find command to search for the next occurrence of the requested text. See Find for a description of how to use the search function.
repeats the last Find command to search for the next occurrence of the requested text. See Find for a description of how to use the search function.
You can use regular expressions (regex) to find a text string. To do this, first, switch the Regular expression option on (see above). This specifies that the text in the search term field is to be evaluated as a regular expression. Next, enter the regular expression in the search term field. For help with building a regular expression, click the Regular Expression Builder button, which is located to the right of the search term field. Click an item in the Builder to enter the corresponding regex metacharacter/s in the search term field. See below for a brief description of metacharacters.
Regular expression metacharacters
Given below is a list of regular expression metacharacters.
. | Matches any character. This is a placeholder for a single character. |
( | Marks the start of a tagged expression. |
) | Marks the end of a tagged expression. |
(abc) | The ( and ) metacharacters mark the start and end of a tagged expression. Tagged expressions may be useful when you need to tag ("remember") a matched region for the purpose of referring to it later (back-reference). Up to nine expressions can be tagged (and then back-referenced later, either in the Find or Replace field).
For example, (the) \1 matches the string the the. This expression can be literally explained as follows: match the string "the" (and remember it as a tagged region), followed by a space character, followed by a back-reference to the tagged region matched previously. |
\n | Where n is a variable that can take integer values from 1 through 9. The expression refers to the first through ninth tagged region when replacing. For example, if the find string is Fred([1-9])XXX and the replace string is Sam\1YYY, this means that in the find string there is one tagged expression that is (implicitly) indexed with the number 1; in the replace string, the tagged expression is referenced with \1. If the find-replace command is applied to Fred2XXX, it would generate Sam2YYY. |
\< | Matches the start of a word. |
\> | Matches the end of a word. |
\x | Allows you to use a character x, which would otherwise have a special meaning. For example, \[ would be interpreted as [ and not as the start of a character set. |
[...] | Indicates a set of characters. For example, [abc] means any of the characters a, b or c. You can also use ranges: for example [a-z] for any lower case character. |
[^...] | The complement of the characters in the set. For example, [^A-Za-z] means any character except an alphabetic character. |
^ | Matches the start of a line (unless used inside a set, see above). |
$ | Matches the end of a line. Example: A+$ to find one or more A's at end of line. |
* | Matches 0 or more times. For example, Sa*m matches Sm, Sam, Saam, Saaam and so on. |
+ | Matches 1 or more times. For example, Sa+m matches Sam, Saam, Saaam and so on. |
Representation of special characters
Note the following expressions.
\r | Carriage Return (CR). You can use either CR (\r) or LF (\n) to find or create a new line |
\n | Line Feed (LF). You can use either CR (\r) or LF (\n) to find or create a new line |
\t | Tab character |
\\ | Use this to escape characters that appear in regex expression, for example: \\\n |
Regular expression examples
This example illustrates how to find and replace text using regular expressions. In many cases, finding and replacing text is straightforward and does not require regular expressions at all. However, there may be instances where you need to manipulate text in a way that cannot be done with a standard find and replace operation. Consider, for example, that you have an XML file of several thousand lines where you need to rename certain elements in one operation, without affecting the content enclosed within them. Another example: you need to change the order of multiple attributes of an element. This is where regular expressions can help you, by eliminating a lot of work which would otherwise need to be done manually.
Example 1: Renaming elements
The sample XML code listing below contains a list of books. Let's suppose your goal is to replace the <Category> element of each book to <Genre>. One of the ways to achieve this goal is by using regular expressions.
<?xml version="1.0" encoding="UTF-8"?> |
To solve the requirement, follow the steps below:
1.Press Ctrl+H to open the Find and Replace dialog box.
2.Click Use regular expressions ![]() .
.
3.In the Find field, enter the following text: <category>(.+)</category> . This regular expression matches all category elements, and they become highlighted.
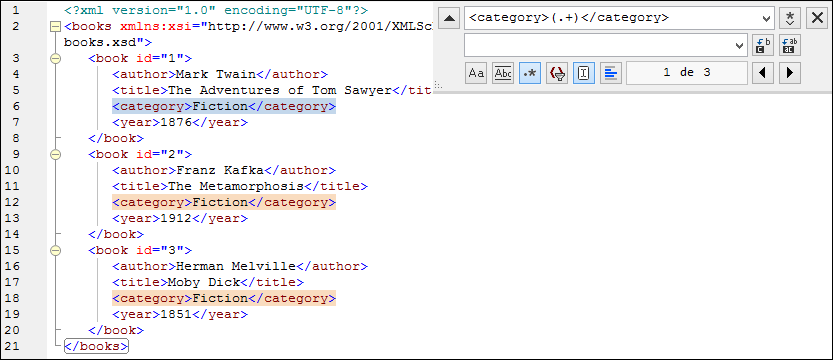
To match the inner text of each element (which is not known in advance), we used the tagged expression (.+) . The tagged expression (.+) means "match one or more occurrences of any character, that is .+ , and remember this match". As shown in the next step, we will need the reference to the tagged expression later.
4.In the Replace field, enter the following text: <genre>\1</genre> . This regular expression defines the replacement text. Notice it uses a back-reference \1 to the previously tagged expression from the Find field. In other words, \1 in this context means "the inner text of the currently matched <category> element".
5.Click Replace All ![]() and observe the results. All category elements have now been renamed to genre, which was the intended goal.
and observe the results. All category elements have now been renamed to genre, which was the intended goal.
Example 2: Changing the order of attributes
The sample XML code listing below contains a list of products. Each product element has two attributes: id and a size. Let's suppose your goal is to change the order of id and size attributes in each product element (in other words, the size attribute should come before id). One of the ways to solve this requirement is by using regular expressions.
<?xml version="1.0" encoding="UTF-8"?> |
To solve the requirement, follow the steps below:
1.Press Ctrl+H to open the Find and Replace dialog box.
2.Click Use regular expressions  .
.
3.In the Find field, enter the following: <product id="(.+)" size="(.+)"/> . This regular expression matches a product element in the XML document. Notice that, in order to match the value of each attribute (which is not known in advance), a tagged expression (.+) is used twice. The tagged expression (.+) matches the value of each attribute (assumed to be one or more occurrences of any character, that is .+ ).
4.In the Replace field, enter the following: <product size="\2" id="\1"/> . This regular expression contains the replacement text for each matched product element. Notice that it uses two references \1 and \2 . These correspond to the tagged expressions from the Find field. In other words, \1 means "the value of attribute id" and \2 means "the value of attribute size".

6.Click Replace All  and observe the results. All product elements have now been updated so that attribute size comes before attribute id.
and observe the results. All product elements have now been updated so that attribute size comes before attribute id.