Regular Expressions
Sie können Regular Expressions ("regex") bei der Erstellung eines MapForce Mappings in folgenden Situationen verwenden:
•im pattern-Parameter der Funktionen match-pattern und tokenize-regexp
•um die Nodes, auf die eine Node-Funktion angewendet werden sollen, zu filtern. Nähere Informationen dazu finden Sie unter Bedingte Anwendung von Node-Funktionen und Standardwerten.
Die Syntax und Semantik von Regular Expressions für XSLT und XQuery entspricht den in Appendix F von "XML Schema Part 2: Datatypes Second Edition" definierten Regeln.
Anmerkung: Die komplexen Funktionalitäten der Regular Expression-Syntax können bei der Generierung von C++-, C#- oder Java-Code etwas unterschiedlich sein. Nähere Informationen dazu finden Sie in der regex-Dokumentation zu den einzelnen Sprachen.
Terminologie
Die grundlegende Terminologie von Regular Expressions wird hier anhand des Beispiels tokenize-regexp erläutert. Diese Funktion teilt Text mit Hilfe von Regular Expressions in eine Sequenz von Strings auf. Zu diesem Zweck erhält die Funktion die folgenden Input-Parameter:
input | Der Input-String, der von der Funktion verarbeitet werden soll. Die Regular Expression wird an diesem String angewendet. |
pattern | Das eigentliche Muster der Regular Expression, die angewendet werden soll. |
flags | Dies ist ein optionaler Parameter, der zusätzliche Optionen (Flags) definiert, die festlegen, wie die Regular Expression interpretiert werden soll, siehe "Flags" weiter unten. |
Der Input-String im Mapping unten ist "Altova MapForce". Der Parameter pattern ist ein Leerzeichen. Es werden keine Regular Expression Flags verwendet.

Der Text wird dadurch überall dort, wo ein Leerzeichen steht, aufgeteilt, daher ist die Ausgabe des Mappings:
<items> |
Beachten Sie, dass die Funktion tokenize-regexp die übereinstimmenden Zeichen aus dem Ergebnis ausschließt. D.h. das Leerzeichen wird in diesem Beispiel aus der Ausgabe entfernt.
Das obige Beispiel ist sehr einfach gehalten. Dasselbe Ergebnis kann auch ohne Regular Expressions, mit Hilfe der Funktion tokenize erzielt werden. In einem realistischeren Szenario würde der Parameter pattern eine komplexere Regular Expression enthalten. Die Regular Expression kann aus beliebigen der folgenden Bestandteile bestehen:
•Literale
•Zeichenklassen
•Zeichenbereiche
•Negierte Klassen
•Metazeichen
•Quantifizierer
Literale
Literale dienen zum Finden von Zeichen in exakt dieser Schreibweise. Wenn der Input-String z.B. abracadabra lautet und pattern das Literal br ist, so ist die Ausgabe die folgende:
<items> |
Der Grund dafür ist, dass das Literal br im Input-String abracadabra zwei Übereinstimmungen hat. Nachdem die übereinstimmenden Zeichen aus der Ausgabe entfernt wurden, wird die oben gezeigte Sequenz von drei Strings erzeugt.
Zeichenklassen
Wenn Sie eine Gruppe von Zeichen in eckige Klammern ([ und ]) setzen, wird dadurch eine Zeichenklasse erstellt. Es wird immer nur jeweils ein einziges der Zeichen innerhalb der Zeichenklasse gefunden, z.B:
•Mit dem Muster [aeiou] werden alle klein geschriebenen Vokale gefunden.
•Mit dem Muster [mj]ust werden "must" und "just" gefunden.
Anmerkung: Die Groß- und Kleinschreibung spielt beim Muster eine Rolle, d.h. ein kleingeschriebenes "a" stimmt nicht mit dem Großbuchstaben "A" überein. Damit Groß- und Kleinschreibung ignoriert werden, verwenden Sie das Flag i, siehe unten.
Zeichenbereiche
Mit [a-z] erstellen Sie einen Bereich zwischen den beiden Zeichen. Es wird immer nur jeweils eines der Zeichen gefunden. So wird etwa mit dem Muster [a-z] jeder Kleinbuchstabe zwischen "a" und "z" gefunden.
Negierte Klassen
Mit dem Zikumflexzeichen ( ^ ) als erstem Zeichen nach der öffnenden Klammer wird die Zeichenklasse negiert. Mit dem Muster [^a-z] wird z.B. jedes Zeichen außerhalb der Zeichenklasse, einschließlich Zeilenschaltungen (newline-Zeichen) gefunden.
Übereinstimmung mit jedem beliebigen Zeichen.
Mit Hilfe des Punkt-Metazeichens ( . ) wird jedes beliebige Einzelzeichen mit Ausnahme einer Zeilenschaltung (newline) gefunden. So wird z.B. mit dem Muster . jedes einzelne Zeichen gefunden.
Quantifizierer
Quantifizierer definieren in einer Regular Expression, wie oft das vorangestellte Zeichen oder der vorangestellte Unterausdruck vorkommen darf, damit eine Übereinstimmung gefunden wird.
? | Steht für null oder eine Instanz des direkt davor stehenden Elements. Das Muster mo? steht z.B. für "m" und "mo". |
+ | Steht für eine oder mehr Instanzen des direkt davor stehenden Elements. Das Muster mo+ steht z.B. für "mo", "moo", "mooo", usw. |
* | Steht für null oder mehr Instanzen direkt davor stehenden Elements. |
{min,max} | Steht für beliebig viele Instanzen zwischen min und max. So steht etwa das Muster mo{1,3} für "mo", "moo" und "mooo". |
Klammern
Mit Hilfe von Klammern ( und ) werden Teile eines regex-Ausdrucks gruppiert. Sie können damit Quantifizierer auf einen Unterausdruck (anstatt auf nur ein Zeichen) anwenden. Oder Sie verwenden diese mit einer Alternative (siehe unten).
Alternative
Der senkrechte Strich (Pipe-Zeichen) | bedeutet "oder". Er findet einen beliebigen von mehreren durch | getrennte Unterausdrücke. So findet etwa das Muster (horse|make) sense sowohl "horse sense" und "make sense".
Flags
Flags sind optionale Parameter, die definieren, wie die Regular Expression interpretiert werden soll. Jedes Flag entspricht einem Buchstaben. Die Buchstaben können in jeder Reihenfolge vorkommen und auch wiederholt werden.
s | Falls dieses Flag vorhanden ist, wird der Suchvorgang im "dot-all"-Modus durchgeführt.
Wenn der Input-String "hello" und "world" in zwei verschiedenen Zeilen vorkommt, findet die Regular Expression hello*world nur dann eine Übereinstimmung, wenn das Flag s gesetzt wurde. |
m | Wenn dieses Flag vorhanden ist, wird der Suchvorgang im mehrzeiligen Modus durchgeführt.
Im mehrzeiligen Modus steht das Zirkumflexzeichen ^ für den Beginn jeder Zeile, d.h. den Beginn des gesamten Strings und das erste Zeichen nach einem "newline"-Zeichen.
Das Dollarzeichen $ steht für das Ende jeder Zeile, d.h. das Ende des gesamten Strings und das Zeichen unmittelbar vor einem "newline" Zeichen.
Newline (Neue Zeile) ist das Zeichen #x0A. |
i | Wenn dieses Flag vorhanden ist, wird die Groß- und Kleinschreibung ignoriert. So würden etwa mit der Regular Expression [a-z] plus dem i Flag alle Buchstaben von a-z und A-Z gefunden. 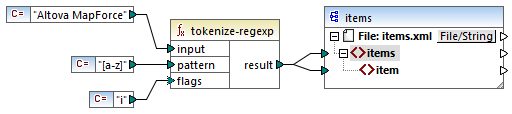 |
x | Falls dieses Flag vorhanden ist, werden Leerzeichen und andere Whitespace-Zeichen vor dem Suchvorgang aus der Regular Expression entfernt. Whitespace-Zeichen sind #x09, #x0A, #x0D und #x20.
Anmerkung: Whitespace-Zeichen innerhalb einer Zeichenklasse z.B. [#x20] werden nicht entfernt. |