Beispiel: Verknüpfen von Tabellen mittels Join im SQL-Modus
In diesem Beispiel wird gezeigt, wie Sie Daten aus zwei Datenbanktabellen mit Hilfe einer MapForce Join-Komponente miteinander verknüpfen. Die Join-Operation wird im SQL-Modus durchgeführt, wie in Join-Verknüpfungen im SQL-Modus beschrieben. Beachten Sie, dass das Verknüpfen von drei oder mehr Tabellen ähnlich funktioniert, siehe auch Beispiel: Erstellen eines CSV-Berichts anhand mehrerer Tabellen.
Das Mapping-Beispiel dazu finden Sie unter dem folgenden Pfad: <Dokumente>\Altova\MapForce2026\MapForceExamples\JoinDatabaseTables.mfd.
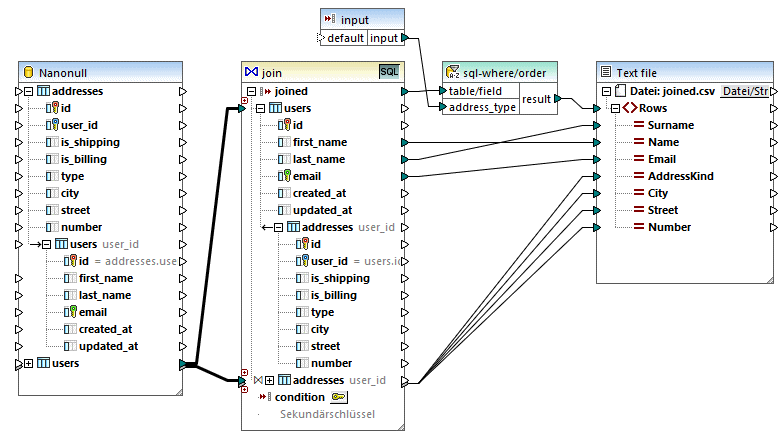
JoinDatabaseTables.mfd
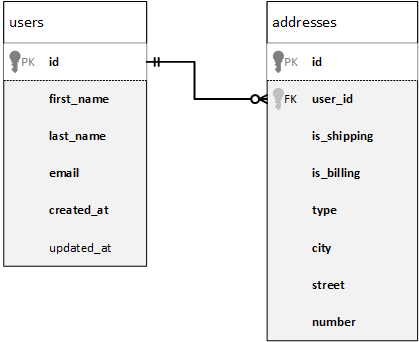
Ziel des obigen Mappings ist es, Daten aus zwei Datenbankquelltabellen in einer einzigen CSV-Zieldatei zu kombinieren. Wie im Datenbankdiagramm unten gezeigt, sind in der ersten Tabelle (users) Personenadressen und in der zweiten Tabelle (addresses) Personennamen und E-Mail-Adressen gespeichert. Die beiden Tabellen sind über ein gemeinsames Feld miteinander verknüpft (id in users entspricht user_id in addresses). In der Datenbankterminologie bezeichnet man diese Art von Beziehung auch als "Sekundärschlüsselbeziehung".
In der Abbildung unten sehen Sie die tatsächlichen Daten in beiden Tabellen.
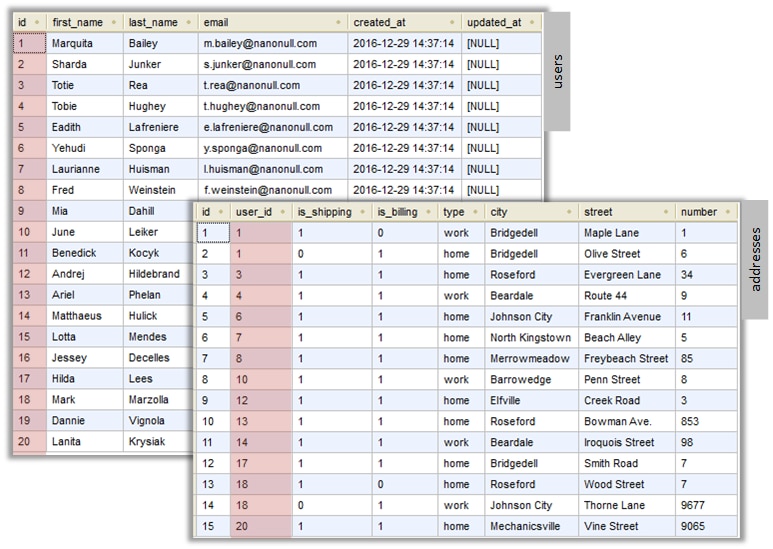
Jeder Benutzerdatensatz in der Tabelle users kann null oder mehr Adressen in der Tabelle addresses haben. So kann ein Benutzer etwa eine Adresse vom Typ "home" oder zwei Adressen (eine vom Typ "home" und eine weitere vom Typ "work") oder gar keine Adresse haben.
Ziel des Mappings ist es, die vollständigen Daten (Namen, Familienname, E-Mail, Stadt, Straße, Hausnummer) aller Benutzer, die in der Tabelle "addresses" mindestens eine Adresse haben, abzurufen. Es sollte auch problemlos möglich sein, nur Adressen einer bestimmten Art (z.B. nur Home-Adressen oder nur Work-Adressen) abzurufen. Die Art der abzurufenden Adressen ("home" oder "work") sollte in Form eines Parameters an das Mapping übergeben werden. Die abgerufenen Personendatensätze müssen nach dem Nachnamen (last name) alphabetisch sortiert werden.
Dies wird mit Hilfe einer Join-Komponente erreicht, wie in den Schritten unten beschrieben.
Anmerkung: Datenbanktabellen oder -ansichten können nicht nur mittels einer Join-Komponente miteinander verknüpft werden. Join-Verknüpfungen bei Datenbanken können auch mit Hilfe von SQL SELECT-Anweisungen durchgeführt werden. Siehe SELECT-Anweisungen als virtuelle Tabellen. Ein bedeutender Unterschied zwischen SQL SELECT-Anweisungen und Join-Komponenten ist, dass erstere von Hand geschrieben werden, so dass sie mehr Flexibilität bieten. Join-Komponenten sind eine einfachere Alternative, wenn Sie mit dem Schreiben von SQL-Anweisungen nicht so vertraut sind.
Schritt 1: Hinzufügen der Quelldatenbank
1.Klicken Sie im Menü Einfügen auf Datenbank. (Klicken Sie alternativ dazu auf die Symbolleisten-Schaltfläche Datenbank einfügen  ).
).
2.Wählen Sie als Datenbankart "SQLite" aus und klicken Sie auf Weiter.
3.Navigieren Sie zur Datei Nanonull.sqlite im Ordner <Dokumente>\Altova\MapForce2026\MapForceExamples\ und klicken Sie auf Verbinden.
4.Wenn Sie dazu aufgefordert werden, wählen Sie die Tabellen addresses und users aus.
Schritt 2: Hinzufügen der Join-Komponente
1.Wählen Sie im Menü Einfügen den Befehl Verbinden. (Klicken Sie alternativ dazu auf die Symbolleisten-Schaltfläche Join  ).
).
2.Ziehen Sie eine Verbindung von der Tabelle users zum ersten Input der Join-Komponente.
3.Erweitern Sie die Tabelle users und ziehen Sie eine Verbindung von der Tabelle addresses (Child von users) zum zweiten Input der Join-Komponente. Über die Schaltfläche  können Sie, falls nötig, weitere Tabellen hinzufügen; in diesem Beispiel werden jedoch nur zwei Tabellen miteinander verknüpft.
können Sie, falls nötig, weitere Tabellen hinzufügen; in diesem Beispiel werden jedoch nur zwei Tabellen miteinander verknüpft.
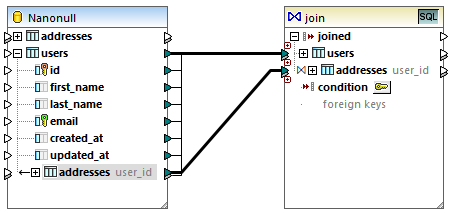
Anmerkung: Die Verbindung kann auch direkt von der Tabelle addresses aus hinzugefügt werden (die Tabelle, die kein Child von users ist); in diesem Fall müssten die Bedingungen jedoch manuell definiert werden, wie unter Hinzufügen von Join-Bedingungen beschrieben. In diesem Beispiel sollten Sie die Verbindungen jedoch wie oben gezeigt ziehen. Dadurch stellen Sie sicher, dass die benötigte Join-Verbindung automatisch erstellt wird.
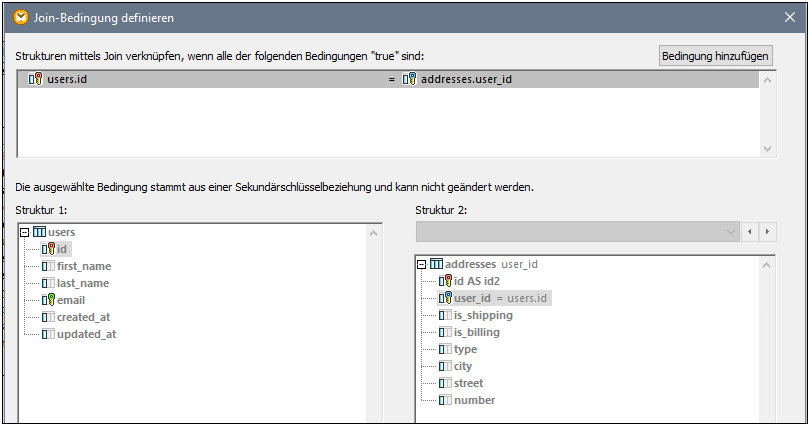
4.Klicken Sie in der Join-Komponente auf die Schaltfläche Join-Bedingung definieren  . Beachten Sie, dass die Join-Bedingung automatisch erstellt wurde (users.id = addresses.user_id).
. Beachten Sie, dass die Join-Bedingung automatisch erstellt wurde (users.id = addresses.user_id).
Schritt 3: Hinzufügen der CSV-Zielkomponente
1.Klicken Sie im Menü Einfügen auf Textdatei. (Klicken Sie alternativ dazu auf die Symbolleisten-Schaltfläche Textdatei einfügen ![]() ).
).
2.Wenn Sie aufgefordert werden, einen Textverarbeitungsmodus auszuwählen, wählen Sie Einfache Verarbeitung für Standard-CSV... .
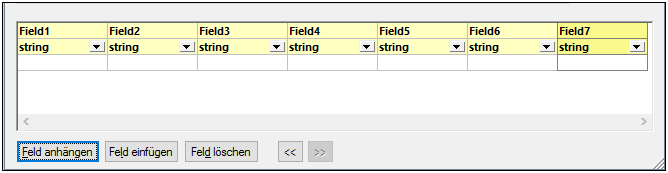
3.Klicken Sie mehrmals auf Feld anhängen, um sieben CSV-Felder zu erstellen. Belassen Sie alle anderen Einstellungen unverändert.
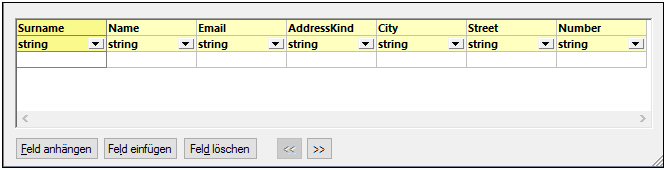
4.Doppelklicken Sie auf die Titelzellen der einzelnen Felder, um ihnen einen beschreibenden Namen zu geben (dadurch wird Ihr Mapping leichter lesbar).
5.Ziehen Sie die Mapping-Verbindungen zwischen der Join-Komponente und der CSV-Komponente, wie unten gezeigt. Die Verbindung zwischen dem Datenelement joined der Join-Komponente und dem Datenelement Rows der Zielkomponente bedeutet "Erstelle in der Zielkomponente so viele Datensätze (Zeilen) wie Datensätze vorhanden sind, die die Join-Bedingung erfüllen".
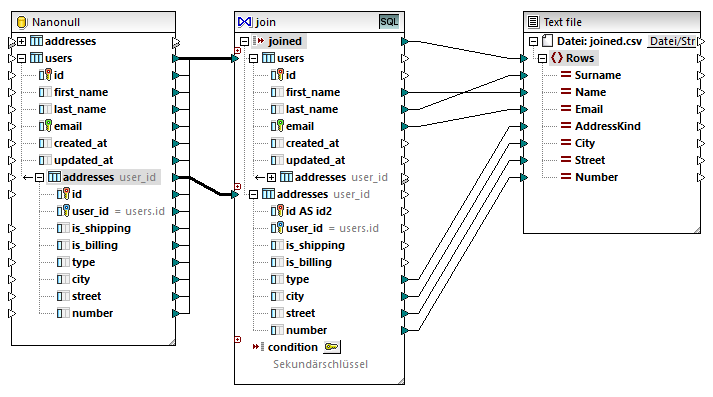
Schritt 4: Hinzufügen der SQL WHERE/ORDER-Bedingung und der Input-Parameter
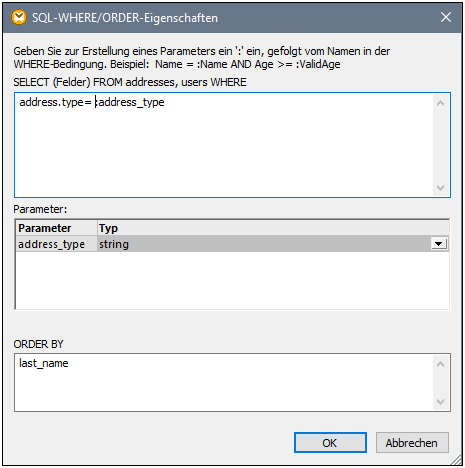
1.Klicken Sie mit der rechten Maustaste auf die Verbindung zwischen dem Datenelement joined der Join-Komponente und dem Datenelement Rows der CSV-Zielkomponente und wählen Sie SQL-WHERE/ORDER einfügen.
2.Geben Sie die unten gezeigten WHERE- und ORDER BY-Klauseln ein.
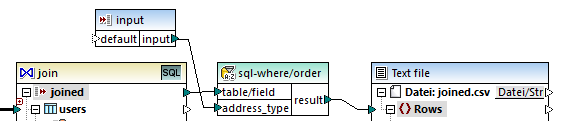
3.Fügen Sie im Mapping (mit dem Befehl Einfügen | Input-Komponente einfügen) eine Input-Komponente hinzu und verbinden Sie ihren Output mit dem im vorherigen Schritt erstellten Parameter address_type.
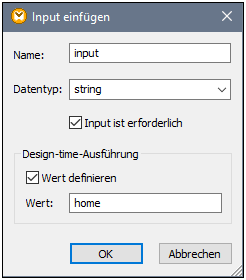
4.Doppelklicken Sie auf die Input-Komponente und konfigurieren Sie sie, wie unten gezeigt. Um in MapForce eine Vorschau auf die Mapping-Ausgabe anzuzeigen, wird ein Design-time-Wert benötigt (in diesem Fall "home"). Wenn in der Vorschau Arbeitsadressen abgerufen werden sollen, ersetzen Sie den Wert durch "work".
Erläuterung des Mappings
Mit der in Schritt 2 automatisch erstellten Join-Bedingung wird sichergestellt, dass nur Datensätze, die die Join-Bedingung users.id = addresses.user_id erfüllen, in die Zielkomponente kopiert werden. Die Join-Bedingung wurde automatisch hinzugefügt, weil die zwei Tabellen durch eine Sekundärschlüsselbeziehung verbunden sind und die Mapping-Verbindungen wurden entsprechend gezeichnet. Nähere Informationen zu Tabellenbeziehungen finden Sie unter Behandlung von Datenbankbeziehungen. Da in diesem Beispiel die bereits existierenden Tabellenbeziehungen verwendet wurden, mussten keine Join-Bedingungen manuell definiert werden. Ein Beispiel, in dem gezeigt wird, wie Join-Bedingungen manuell definiert werden, finden Sie unter Beispiel: Erstellen eines CSV-Berichts anhand mehrerer Tabellen.
Die beiden Quelltabellen stammen aus derselben Datenbank und derselben Komponente, daher können Sie für diese Join-Verknüpfung den SQL-Modus  nutzen. Da der SQL-Modus aktiviert ist, wird die Join-Operation von der Datenbank und nicht von MapForce ausgeführt. Anders ausgedrückt, wird von MapForce intern eine INNERER JOIN-Anweisung generiert und für die Ausführung an die Datenbank gesendet. Die Art des Join (INNERER JOIN) wird in der Join-Komponente durch das Innerer Join
nutzen. Da der SQL-Modus aktiviert ist, wird die Join-Operation von der Datenbank und nicht von MapForce ausgeführt. Anders ausgedrückt, wird von MapForce intern eine INNERER JOIN-Anweisung generiert und für die Ausführung an die Datenbank gesendet. Die Art des Join (INNERER JOIN) wird in der Join-Komponente durch das Innerer Join ![]() Symbol vor der Tabelle addresses angezeigt. Sie können den Join-Typ auch in LINKER ÄUSSERER JOIN
Symbol vor der Tabelle addresses angezeigt. Sie können den Join-Typ auch in LINKER ÄUSSERER JOIN ![]() ändern, wie unter Ändern des Join-Modus beschrieben. Beachten Sie jedoch, dass eine Änderung des Join-Modus keine Auswirkung auf den Output dieses Beispiels hat.
ändern, wie unter Ändern des Join-Modus beschrieben. Beachten Sie jedoch, dass eine Änderung des Join-Modus keine Auswirkung auf den Output dieses Beispiels hat.
Mit Hilfe der in Schritt 4 hinzugefügten SQL WHERE/ORDER-Komponente können die Datensätze gefiltert (so dass entweder Heimat- oder Arbeitsadressen abgerufen werden) und sortiert werden. Beachten Sie, dass mit der WHERE-Klausel ein Parameter :address_type vom Typ string erstellt wurde. Über diesen Parameter kann die Art der Adresse (home oder work) aus dem Mapping bereitgestellt werden. Nähere Informationen zu SQL WHERE/ORDER finden Sie unter Filtern und Sortieren von Datenbankdaten (SQL WHERE/ORDER).
Über die Input-Komponente kann schließlich während der Ausführung des Mappings der tatsächliche Parameterwert bereitgestellt werden. Beachten Sie, dass der Input bei Ausführung des Mappings außerhalb von MapForce (z.B. wenn das Mapping von MapForce Server auf einem anderen Rechner ausgeführt wird) zur Mapping-Laufzeit als Befehlszeilenparameter bereitgestellt werden muss, d.h. der oben erwähnte Design-time-Wert wird ignoriert. Nähere Informationen dazu finden Sie unter Bereitstellen von Parametern für das Mapping.