Préparer les fichiers pour l'exécution de serveur
Cette rubrique décrit les principaux aspects de la préparation des mappages pour leur exécution sur un serveur. L'exécution de mappages dans un environnement serveur nécessite généralement une certaine préparation pour les raisons suivantes :
•Un mappage conçu dans MapForce peut faire référence à des ressources qui ne sont pas disponibles sur la machine et le système d'exploitation actuels (par exemple, des bases de données).
•Les chemins d'accès aux mappages suivent par défaut les conventions de style Windows.
•Il se peut que la machine sur laquelle MapForce Server est exécuté ne prenne pas en charge les mêmes connexions de base de données que la machine sur laquelle le mappage a été conçu.
Prérequis
Si MapForce Server fonctionne en mode autonome (sans FlowForce Server), les licences suivantes sont requises :
•Machine source : MapForce Enterprise ou Professional Edition est requis pour concevoir des mappages et les compiler en fichiers d'exécution serveur (.mfx).
•Machine cible : MapForce Server ou MapForce Server Advanced Edition est requis pour exécuter les mappages.
Si MapForce Server est géré par FlowForce Server, les conditions suivantes s'appliquent :
•Machine source : MapForce Enterprise ou Professional Edition est requis pour concevoir des mappages et les déployer sur une machine cible.
•Machine cible : MapForce Server et FlowForce Server doivent tous deux être sous licence.
•FlowForce Server doit être exécuté à l'adresse réseau et sur le port configurés et ne doit pas être bloqué par un pare-feu.
•Vous disposez d'un compte utilisateur FlowForce Server avec des autorisations pour le conteneur approprié (par défaut, le conteneur /public est accessible à tout utilisateur authentifié).
Note : le terme machine source désigne l'ordinateur sur lequel MapForce est installé. Le terme machine cible désigne l'ordinateur sur lequel MapForce Server et/ou FlowForce Server est installé. Dans un scénario type, MapForce s'exécute sur une machine Windows, tandis que MapForce Server et FlowForce Server s'exécutent sur une machine Linux.
Considérations générales
Tenez compte des points importants suivants :
•Si vous avez l'intention d'exécuter le mappage sur une machine cible avec MapForce Server autonome, tous les fichiers d'entrée référencés par le mappage doivent également être copiés sur la machine cible.
•Si MapForce Server est géré par FlowForce Server, aucune copie manuelle n'est nécessaire. Dans ce cas, les fichiers d'instance et de schéma sont inclus dans le pack de déploiement envoyé à la machine cible.
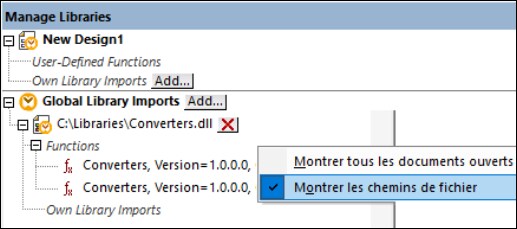
•Si un mappage utilise des fonctions personnalisées (par exemple, des fonctions implémentées dans des fichiers .dll ou .class), les fichiers de bibliothèque correspondants ne sont pas déployés automatiquement avec le mappage, car ils ne sont résolus qu'au moment de l'exécution. Dans ce cas, vous devez copier manuellement les fichiers de bibliothèque requis sur la machine cible. Le chemin d'accès à chaque fichier .dll ou .class sur le serveur doit correspondre au chemin spécifié dans le dialogue Gérer les bibliothèques de MapForce (voir la capture d'écran ci-dessous).
•Certains mappages lisent plusieurs fichiers d'entrée à l'aide d'un chemin d'accès générique. Dans ce cas, les noms des fichiers d'entrée ne sont pas connus avant l'exécution et ne sont donc pas déployés. Pour que le mappage s'exécute correctement, les fichiers d'entrée requis doivent exister sur la machine cible.
•Si le chemin d'accès de sortie du mappage comprend des répertoires, ceux-ci doivent déjà exister sur la machine cible. Sinon, une erreur se produit lors de l'exécution du mappage. Ce comportement diffère de celui de MapForce, où les répertoires inexistants peuvent être créés automatiquement si l'option Générer la sortie vers les fichiers temporaires est activée.
•Si le mappage appelle un service Web qui nécessite une authentification HTTPS avec un certificat client, le certificat doit également être transféré vers la machine cible.
•Avant de déployer un mappage sur FlowForce Server ou de le compiler vers un fichier d'exécution MapForce Server, assurez-vous que le mappage est validé avec succès dans MapForce.
Rendre les chemins d'accès portables
Pour exécuter un mappage sur un serveur, assurez-vous qu’il respecte les conventions de chemin d'accès applicables et utilise une connexion à une base de données prise en charge.
Pour rendre les chemins d'accès portables vers des systèmes d'exploitation non Windows, utilisez des chemins d'accès relatifs dans les mappages MapForce :
1.Ouvrez un fichier de conception de mappage (.mfd) avec MapForce sous Windows.
2.Sélectionnez l'élément de menu Fichier | Paramètres de mappage et désactivez la case à cocher Rendre les chemins absolus dans le code généré.
3.Pour chaque composant, ouvrez le dialogue Propriétés, rendez tous les chemins d'accès aux fichiers relatifs et cochez la case Enregistrer tous les chemins de fichier relatifs au fichier MFD.
Pour plus d'informations sur les chemins d'accès relatifs et absolus dans les mappages, voir la documentation MapForce.
Répertoire de travail
MapForce Server et FlowForce Server utilisent le répertoire de travail pour résoudre tous les chemins relatifs. Le répertoire de travail est spécifié au moment de l'exécution du mappage comme suit :
•FlowForce Server : en modifiant le paramètre Répertoire de travail d'une tâche.
•API MapForce Server : via la propriété WorkingDirectory des API COM et .NET ou via la méthode setWorkingDirectory de l'API Java.
•Ligne de commande MapForce Server : le répertoire de travail est le répertoire actuel du shell de commande.
Compiler des mappages pour l’exécution MapForce Server (Java)
Lorsque vous compilez un mappage pour l'exécution avec MapForce Server et que vous sélectionnez Java comme langage de transformation, vous pouvez utiliser les options de commande run suivantes pour éviter les problèmes de résolution du chemin de classe Java :
•--java-classpath
•--java-ignore-codebase
Pour plus d'informations sur ces options, voir la documentation MapForce Server.
Deployer des mappages vers FlowForce Server (Java)
Lorsque vous déployez un mappage vers FlowForce Server et que vous sélectionnez Java comme langage de transformation, vous pouvez configurer le chemin de classe et l'option java-ignore-codebase dans le fichier MapForce_<version>.tool afin d'éviter tout problème lié à la résolution du chemin de classe Java. Pour personnaliser le fichier outil, procédez comme suit :
1.Copiez le fichier outil depuis :
C:\Program Files\Altova\FlowForceServer<year>\tools
vers le répertoire d'instance de FlowForce Server :
C:\ProgramData\Altova\FlowForceServer\data\tools (emplacement par défaut)
2.Modifiez le fichier dans le répertoire d'instance comme suit :
[Options]
java.codebase.ignore=1
[Environment]
CLASSPATH=<path>
Connexions à la base de données
Si le mappage comprend des composants de base de données qui nécessitent des pilotes spécifiques, ceux-ci doivent également être installés sur la machine cible.
Lorsque vous déployez un mappage sur des plates-formes non Windows, les connexions aux bases de données ADO, ADO.NET et ODBC sont automatiquement converties en JDBC. Dans ce cas, vous pouvez configurer la connexion JDBC dans MapForce à l'aide de l'une des options suivantes avant de déployer le mappage ou de le compiler en fichier d'exécution serveur :
•Créez une connexion JDBC à la base de données.
•Remplissez les détails de la connexion à la base de données JDBC dans la section Paramètres spécifiques à JDBC du composant de base de données.
Les connexions SQLite et PostgreSQL natives sont conservées et ne nécessitent aucune configuration supplémentaire.. Si le mappage se connecte à une base de données fichier telle que SQLite, une configuration supplémentaire peut être nécessaire (voir Bases de données basées sur des fichiers ci-dessous).
Conditions requises pour exécuter des mappages avec des connexions JDBC
Pour exécuter des mappages avec des connexions JDBC, un environnement d'exécution Java ou un kit de développement Java doit être installé sur le serveur. Il peut s'agir d'Oracle JDK ou d'une version open source telle qu'Oracle OpenJDK. Notez les points importants suivants :
•La variable d'environnement JAVA_HOME doit pointer vers le répertoire d'installation du JDK.
•Sous Windows, le chemin d'accès à la machine virtuelle Java dans le registre Windows a priorité sur JAVA_HOME.
•La plate-forme JDK (64 bits, 32 bits) doit correspondre à la plate-forme de MapForce Server. Sinon, vous risquez d'obtenir l'erreur suivante : « JVM inaccessible ».
Configurer une connexion JDBC sous Linux
Pour configurer une connexion JDBC sous Linux, procédez comme suit :
1.Téléchargez le pilote JDBC fourni par le fournisseur de la base de données et installez-le sur le système d'exploitation. Veillez à sélectionner la version bit adaptée à votre plate-forme.
2.Définissez les variables d'environnement de manière à ce qu'elles pointent vers l'emplacement où le pilote JDBC est installé. Consultez la documentation fournie avec le pilote JDBC pour déterminer les variables d'environnement à configurer.
Bases de données basées sur des fichiers
Si le mappage se connecte à une base de données basée sur des fichiers, telle que Microsoft Access ou SQLite, le fichier de base de données n'est pas inclus dans le pack déployé sur FlowForce Server ni dans le fichier d'exécution compilé MapForce Server. Par conséquent, le fichier de base de données doit être transféré manuellement vers la machine cible ou stocké dans un répertoire partagé accessible à la fois à la machine source et à la machine cible.
Transfert manuel
Pour transférer manuellement le fichier de base de données, procédez comme suit :
1.Dans MapForce, ouvrez le menu Fichier | Paramètres de mappage et désactivez la case à cocher Rendre les chemins absolus dans le code généré.
2.Ouvrez les paramètres du composant de base de données et spécifiez un chemin relatif vers le fichier de base de données. Pour éviter les problèmes liés aux chemins, conservez le fichier de mappage et le fichier de base de données dans le même répertoire.
3.Copiez le fichier de base de données dans un répertoire sur la machine cible.
Pour exécuter le mappage sur le serveur, procédez de l'une des manières suivantes :
•Si le mappage est déployé sur FlowForce Server, configurez une tâche FlowForce Server pour qu'il pointe vers l'emplacement où le fichier de base de données est stocké. Pour un exemple, voir Exposer une tâche en tant que service Web.
•Si le mappage est exécuté par MapForce Server autonome à partir de la ligne de commande, changez le répertoire actuel pour le répertoire de travail (par exemple, cd path\to\working\directory) avant d'appeler la commande run.
•Si le mappage est exécuté par l'API MapForce Server, définissez le répertoire de travail par programmation avant d'exécuter le mappage. La propriété WorkingDirectory est disponible dans les API COM et .NET, et la méthode setWorkingDirectory est disponible dans l'API Java.
Répertoire partagé
Si les machines source et cible sont des machines Windows fonctionnant sur le réseau local, vous pouvez configurer le mappage pour lire le fichier de base de données à partir d'un répertoire partagé :
1.Placez le fichier de base de données dans un répertoire partagé accessible par les deux machines.
2.Ouvrez les paramètres du composant de base de données dans le mappage et spécifiez un chemin absolu vers le fichier de base de données.
Ressources globales
Si un mappage inclut des références à des ressources globales au lieu de chemins d'accès directs ou de connexions à des bases de données, vous pouvez également utiliser ces ressources sur le serveur. Notez les points suivants :
•Lorsque vous compilez un mappage en un fichier d'exécution MapForce Server (.mfx), les références aux ressources globales sont conservées. Cela vous permet de fournir les ressources réelles sur le serveur au moment de l'exécution du mappage.
•Lorsque vous déployez un mappage vers FlowForce Server, vous pouvez choisir si le mappage doit utiliser les ressources disponibles sur le serveur.
Pour qu'un mappage s'exécute correctement, les ressources que vous fournissez en tant que ressources globales doivent être compatibles avec l'environnement serveur :
•Les chemins d'accès aux fichiers ou aux dossiers doivent respecter les conventions du système d'exploitation du serveur (par exemple, des chemins d'accès de type Linux si le mappage s'exécute sur un serveur Linux).
•Les connexions à des bases de données définies comme ressources globales doivent être valides et accessibles depuis le serveur.
Pour plus d'informations, voir Ressources.
Packs de taxonomie XBRL
Lorsque vous déployez un mappage faisant référence à des Packs de taxonomie XBRL vers FlowForce Server, MapForce collecte toutes les références externes du mappage et les résout à l'aide de la configuration actuelle et des packs de taxonomie installés :
•S'il existe des références externes résolues qui pointent vers un pack de taxonomie, ce pack est déployé avec le mappage.
•FlowForce Server utilise le pack déployé, exactement tel qu'il était lors du déploiement, pour exécuter le mappage.
•Pour actualiser le pack de taxonomie utilisé par FlowForce Server, vous devez le mettre à jour dans MapForce et redéployer le mappage.
Catalogue racine
Le catalogue racine de MapForce Server influence la manière dont les taxonomies sont résolues sur la machine cible. Le catalogue racine se trouve dans le chemin relatif au répertoire d'installation de MapForce Server :
etc/RootCatalog.xml
Les règles suivantes s'appliquent :
•Les packs de taxonomie déployés avec un mappage ne sont utilisés que si le catalogue racine de MapForce Server ne contient pas le pack ou un pack défini pour le même préfixe d'URL.
•Le catalogue racine de MapForce Server a priorité sur la taxonomie déployée.
Serveur MapForce autonome
Si MapForce Server fonctionne en mode autonome (sans FlowForce Server), vous pouvez spécifier le catalogue racine à utiliser pour le mappage :
•Ligne de commande : ajoutez l'option -catalog à la commande run.
•API MapForce Server : appelez la méthode SetOption avec "catalog" comme premier argument et le chemin d'accès au catalogue racine comme deuxième argument.
Mappages utilisant des bases de liens de table
Si un mappage utilise des composants XBRL avec des bases de liens de table, le pack de taxonomie ou son fichier de configuration doit être fourni au mappage lors de l'exécution :
•Ligne de commande MapForce Server : ajoutez l'option --taxonomy-package ou --taxonomy-packages-config-file à la commande run.
•API MapForce Server : Appelez SetOption avec "taxonomy-package" ou "taxonomy-packages-config-file" comme premier argument et le chemin d'accès au pack de taxonomie ou au fichier de configuration comme deuxième argument.