Suchen, Weitersuchen
Schaltflächen und Tastenkürzel
Befehl | Symbol | Tastaturkürzel |
Suchen | Strg+F | |
Weitersuchen | F3 |
Suchen
Mit dem Befehl Suchen rufen Sie das Dialogfeld "Suchen" auf (siehe Abbildung unten), in dem Sie den zu suchenden String sowie weitere Suchoptionen spezifizieren können. Um einen Text zu suchen, geben Sie diesen in das Feld "Suchen" ein oder verwenden Sie die Auswahlliste, um eines der letzten 10 Suchkriterien auszuwählen und definieren Sie anschließend die gewünschten Optionen für die Suche.
Mit dem Befehl Suchen können Sie auch nach Datei- und Ordnernamen suchen, wenn ein Projekt im Fenster "Projekt" ausgewählt ist.
Weitersuchen
Mit dem Befehl Weitersuchen wird der letzte Suchbefehl wiederholt. Er sucht die nächste Instanz des eingegebenen Texts.
Mit dem Next Befehl Weitersuchen können Sie auch nach Datei- und Ordnernamen suchen, wenn ein Projekt im Fenster "Projekt" ausgewählt ist.
Dialogfeld "Suchen/Ersetzen"
Das unten beschriebene Dialogfeld "Suchen/Ersetzen" wird in der Text- und der Grid-Ansicht angezeigt. Über Schaltflächen unterhalb des Suchfelds (siehe Abbildung unten) stehen Optionen zum Festlegen der Suchkriterien zur Verfügung. Wenn eine Option aktiv ist, ändert sich die Schaltflächenfarbe in Blau (siehe erste Option (Groß-/Kleinschreibung) in der Abbildung unten).

Die folgenden Optionen stehen zur Auswahl:
•GROSS/klein beachten: Wenn die Schaltfläche aktiv ist, wird die Groß- und Kleinschreibung bei der Suche berücksichtigt (Address ist nicht gleich address).
•Ganzes Wort: Nur die exakte Wortentsprechung im Text wird gefunden. So wird z.B. bei Eingabe von fit bei Aktivierung der Option ganzes Wort nur das Wort fit gefunden; fit in fitness wird z.B. nicht gefunden.
•Regular Expression: Wenn die Option aktiv ist, wird der Suchbegriff als Regular Expression gelesen. Eine Beschreibung zur Verwendung von Regular Expressions finden Sie weiter unten unter Regular Expressions.
•Ergebnisse filtern: Wählen Sie eine oder mehrere Dokumentkomponenten, in denen gesucht werden soll.
•Anker suchen: Die gefundenen Treffer werden in Dokumentreihenfolge indiziert und der Index des ausgewählten Treffers wird im Dialogfeld "Suchen" angegeben. So sehen wir etwa anhand der Information in der Abbildung oben, dass derzeit der zweite von vier gefundenen Treffern ausgewählt ist. Bei Klick auf Weitersuchen. (in der Abbildung rechts unten markiert) gelangen Sie zum nächsten gefundenen Treffer in der Indexreihenfolge. Wenn allerdings die Option Anker suchen aktiviert ist, gelangen Sie mit Weitersuchen zum nächsten gefundenen Treffer relativ zur aktuellen Cursorposition. Wenn also der aktuell ausgewählte Treffer der erste (z.B. 1 von 4) ist und Sie den Cursor hinter Treffer 3 platzieren, so gelangen Sie mit Weitersuchen zu Treffer 4 und nicht zu Treffer 2 (wie dies der Fall gewesen wäre, wenn Anker suchen deaktiviert gewesen wäre).
•In Auswahl suchen: Wenn diese Option aktiv ist, wird der aktuell ausgewählte Text gesperrt und die Suche auf die Auswahl eingeschränkt. Andernfalls wird das gesamte Dokument durchsucht. Bevor Sie einen neuen Textbereich auswählen, heben Sie die aktuelle Auswahl durch Deaktivieren der Option In Auswahl suchen auf.
Regular Expressions
Sie können zum Suchen eines Text-String Regular Expressions (regex) verwenden. Aktivieren Sie dazu zuerst die Option Regular Expression (siehe Suchoptionen oben). Dadurch legen Sie fest, dass der Text im Suchbegrifffeld als Regular Expression ausgewertet werden soll. Geben Sie als nächstes die Regular Expression in das Suchfeld ein. Hilfe zur Erstellung von Regular Expressions erhalten Sie durch Klick auf die Schaltfläche Regular Expression Builder rechts vom Suchfeld (siehe Abbildung unten). Klicken Sie auf einen Eintrag im Builder, um die/das entsprechende(n) regex-Metazeichen in das Suchfeld einzugeben. In der Abbildung unten sehen Sie eine einfache Regular Expression zum Suchen von E-Mail-Adressen. Eine kurze Beschreibung zu Metazeichen finden Sie im Abschnitt Regular Expression-Metazeichen weiter unten.

Regular Expression-Metazeichen
In der nachstehenden Liste sehen Sie eine Auflistung von Regular Expression-Metazeichen.
. | Steht für jedes beliebige Zeichen. Dies ist ein Platzhalter für ein einzelnes Zeichen. |
( | Markiert den Beginn eines markierten Ausdrucks. |
) | Markiert das Ende eines markierten Ausdrucks. |
(abc) | Die Metazeichen ( und )markieren Beginn und Ende eines markierten Ausdrucks. Markierte Ausdrücke eignen sich dazu, eine gesuchte Region zu markieren ("sich diese zu merken"), um diese später referenzieren zu können (Rückreferenz). Es können bis zu neun Unterausdrücke markiert werden (und später im Feld "Suchen" oder "Ersetzen" rückreferenziert werden).
So wird etwa mit (the) \1 der String the the gefunden. Dieser Ausdruck erklärt sich folgendermaßen: Suche den String "the" (und merke ihn Dir als markierte Region), gefolgt von einem Leerzeichen, gefolgt von einer Rückreferenz auf die zuvor gesuchte markierte Region. |
\n | n ist eine Variable, die Ganzzahlwerte von 1 bis 9 haben kann. Der Ausdruck bezieht sich auf die erste bis neunte markierte Region bei der Ersetzung. Lautet der Suchstring beispielsweise Fred([1-9])XXX und der Ersetzungsstring Sam\1YYY, so bedeutet dies, dass sich im Suchstring ein markierter Ausdruck befindet, der (implizit) mit der Zahl 1 indiziert ist; im Ersetzungsstring wird der markierte Ausdruck mit \1 referenziert. Wenn der Such- und Ersetzungsbefehl auf Fred2XXX angewendet wird, würde Sam2YYY generiert. |
\< | Steht für den Beginn eines Worts. |
\> | Steht für das Ende eines Worts. |
\x | Damit können Sie ein Zeichen x verwenden, das sonst eine spezielle Bedeutung hätte. So würde z.B. \[ als [ und nicht als Beginn einer Zeichenmenge interpretiert werden. |
[...] | Kennzeichnet eine Zeichenmenge, [abc] z.B. steht für jedes der Zeichen a, b oder c. Sie können auch Bereiche angeben, z.B. [a-z] für alle Kleinbuchstaben. |
[^...] | Die invertierte Zeichenmenge. [^A-Za-z] z.B. steht für jedes Zeichen mit Ausnahme alphabetischer Zeichen. |
^ | Steht für den Zeilenanfang (es sei denn dieses Zeichen wird innerhalb einer Menge verwendet, siehe oben). |
$ | Steht für das Zeilenende. Beispiel: A+$ findet ein oder mehrere A's am Ende der Zeile. |
* | Steht für 0 oder öfter. Mit Sa*m werden z.B. Sm, Sam, Saam, Saaam usw. gefunden. |
+ | Steht für 1 oder öfter. Mit Sa+m werden z.B. Sam, Saam, Saaam usw. gefunden. |
Darstellung von Sonderzeichen
Beachten Sie die folgenden Ausdrücke.
\r | Wagenrücklauf (Carriage Return = CR). Zum Suchen oder Erstellen einer neuen Zeile können Sie entweder CR (\r) oder LF (\n) verwenden. |
\n | Neue Zeile (LF). Zum Suchen oder Erstellen einer neuen Zeile können Sie entweder CR (\r) oder LF (\n) verwenden. |
\t | Tabulatorzeichen |
\\ | Verwenden Sie diese Zeichen, um Zeichen, die in Regular Expressions vorkommen, mit einem Escape zu versehen, z.B.: \\\n |
Beispiele für Regular Expressions
In diesem Beispiel wird gezeigt, wie Sie Text mit Hilfe von Regular Expressions suchen und ersetzen können. In vielen Fällen ist das Suchen und Ersetzen von Text unkompliziert und es werden dafür keine Regular Expressions benötigt. Es gibt jedoch Fälle, in denen Sie Text auf eine Art und Weise bearbeiten müssen, wie es mit der normalen Such- und Ersetzungsoperation nicht möglich ist, z.B. wenn Sie eine XML-Datei mit mehreren tausend Zeilen haben, in der Sie bestimmte Elemente in einer einzigen Operation umbenennen müssen, ohne dabei den darin enthaltenen Inhalt zu ändern. Ein weiteres Beispiel: Sie müssen die Reihenfolge mehrerer Attribute eines Elements ändern. Hier sind Regular Expressions hilfreich, da Sie sich damit eine Menge Arbeit ersparen.
Beispiel 1: Umbenennen von Elementen
Der unten gezeigte XML-Beispielcode enthält eine Liste von Büchern. Angenommen, Sie möchten das Element <Category> jedes Buchs durch <Genre> ersetzen. Ein der Methoden, mit denen Sie dies erreichen, ist mit Hilfe von Regular Expressions.
<?xml version="1.0" encoding="UTF-8"?> |
Gehen Sie dazu folgendermaßen vor:
1.Drücken Sie Strg+H, um das Such- und Ersetzungsdialogfeld aufzurufen.
2.Klicken Sie auf die Schaltfläche Regular Expressions verwenden ![]() .
.
3.Geben Sie in das Suchfeld den folgenden Text ein: <category>(.+)</category> . Mit dieser Regular Expression werden alle category-Elemente gefunden und markiert.
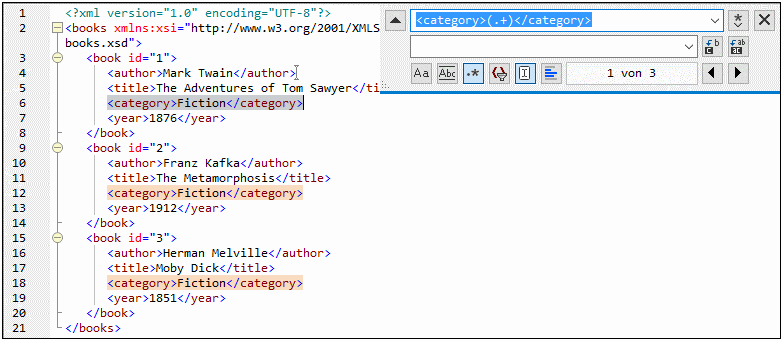
Um den Text im Inhalt der einzelnen Elemente zu suchen (der im Vorhinein nicht bekannt ist), haben wir den getaggten Ausdruck (.+) verwendet. Der getaggte Ausdruck (.+) bedeutet, "finde eine oder mehrere Instanzen eines beliebigen Zeichens, welches .+ entspricht, und merke Dir diese Übereinstimmung". Wie Sie im nächsten Schritt sehen, benötigen wird die Referenz auf den getaggten Ausdruck später.
4.Geben Sie in das Ersetzungsfeld den folgenden Text ein: <genre>\1</genre> . Mit dieser Regular Expression wird der Ersetzungstext definiert. Beachten Sie, dass darin eine Rückreferenz \1 auf den vorhin im Suchfeld getaggten Ausdruck verwendet wird, d.h. \1 bedeutet in diesem Zusammenhang "der Textinhalt der aktuellen <category>-Elementübereinstimmung".
5.Klicken Sie auf Alle ersetzen ![]() und überprüfen Sie die Ergebnisse. Alle category-Elemente wurden nun, wie geplant, in genre umbenannt.
und überprüfen Sie die Ergebnisse. Alle category-Elemente wurden nun, wie geplant, in genre umbenannt.
Beispiel 2: Ändern der Reihenfolge von Attributen
Der unten gezeigte XML-Beispielcode enthält eine Liste von Produkten. Jedes Produktelement hat zwei Attribute: id und size. Angenommen, Sie möchten die Reihenfolge der Attribute id und size in allen product-Elementen ändern (d.h. das Attribut size soll vor id stehen). Eine der Lösungsmethoden dafür ist mittels Regular Expressions.
<?xml version="1.0" encoding="UTF-8"?> |
Gehen Sie dazu folgendermaßen vor:
1.Drücken Sie Strg+H, um das Such- und Ersetzungsdialogfeld aufzurufen.
2.Klicken Sie auf die Schaltfläche Regular Expressions verwenden  .
.
3.Geben Sie ins Suchfeld den folgenden Ausdruck ein: <product id="(.+)" size="(.+)"/> . Mit dieser Regular Expression wird ein product-Element im XML-Dokument gefunden. Beachten Sie, dass zwei Mal ein getaggter Ausdruck (.+) verwendet wird, um den Wert der einzelnen Attribute (der im Vorhinein nicht bekannt ist) zu finden. Mit dem getaggten Ausdruck (.+) wird der Wert jedes einzelnen Attributs gefunden (Der Wert wird als eine oder mehrere Instanzen eines beliebigen Zeichens angenommen, also .+ ).
4.Geben Sie in das Ersetzungsfeld den folgenden Ausdruck ein: <product size="\2" id="\1"/> . Diese Regular Expression enthält den Ersetzungstext für jedes gefundene product-Element. Beachten Sie, dass darin zwei Referenzen \1 und \2 verwendet werden. Diese entsprechen den getaggten Ausdrücken aus dem Suchfeld. Anders ausgedrückt, bedeutet \1 "der Wert des Attributs id" und \2 "der Wert des Attributs size".
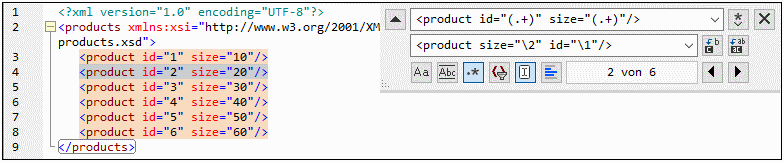
6.Klicken Sie auf Alle ersetzen  und überprüfen Sie die Ergebnisse. Alle product-Elemente wurden nun aktualisiert, so dass das Attribut size jetzt vor dem Attribut id steht.
und überprüfen Sie die Ergebnisse. Alle product-Elemente wurden nun aktualisiert, so dass das Attribut size jetzt vor dem Attribut id steht.