Regular expressions
When designing a MapForce mapping, you can use regular expressions ("regex") in the following contexts:
•In the pattern parameter of the tokenize-regexp function.
The regular expression syntax and semantics for XSLT and XQuery are as defined in Appendix F of "XML Schema Part 2: Datatypes Second Edition".
Note: When generating C++, C#, or Java code, the advanced features of the regular expression syntax might differ slightly. See the regex documentation of each language for more information.
Terminology
Let's examine the basic regular expression terminology by analyzing the tokenize-regexp function as an example. This function splits text into a sequence of strings, with the help of regular expressions. To achieve this, the function takes the following input parameters:
input | The input string to be processed by the function. The regular expression will operate on this string. |
pattern | The actual regular expression pattern to be applied. |
flags | This is an optional parameter that defines additional options (flags) that determine how the regular expression is interpreted, see "Flags" below. |
In the mapping below, the input string is "Altova MapForce". The pattern parameter is a space character, and no regular expression flags are used.

This causes the text to be split whenever the space character occurs, so the mapping output is:
<items> |
Note that the tokenize-regexp function excludes the matched characters from the result. In other words, the space character in this example is omitted from the output.
The example above is very basic and the same result can be achieved without regular expressions, with the tokenize function. In a more practical scenario, the pattern parameter would contain a more complex regular expression. The regular expression can consist of any of the following:
•Literals
•Character classes
•Character ranges
•Negated classes
•Meta characters
•Quantifiers
Literals
Use literals to match characters exactly as they are written (literally). For example, if input string is abracadabra, and pattern is the literal br, the output is:
<items> |
The explanation is that the literal br had two matches in the input string abracadabra. After removing the matched characters from the output, the sequence of three strings illustrated above is produced.
Character classes
If you enclose a set of characters in square brackets ([ and ]), this creates a character class. One and only one of the characters inside the character class is matched, for example:
•The pattern [aeiou] matches any lowercase vowel.
•The pattern [mj]ust matches "must" and "just".
Note: The pattern is case sensitive, so a lowercase "a" does not match the uppercase "A". To make the matching case insensitive, use the i flag, see below.
Character ranges
Use [a-z] to create a range between the two characters. Only one of the characters will be matched at one time. For example, the pattern [a-z] matches any lowercase character between "a" and "z".
Negated classes
Using the caret ( ^ ) as the first character after the opening bracket negates the character class. For example, the pattern [^a-z] matches any character not in the character class, including newline characters.
Matching any character
Use the dot ( . ) meta character to match any single character, except for newline character. For example, the pattern . matches any single character.
Quantifiers
Within a regular expression, quantifiers define how many times the preceding character or sub-expression is allowed to occur in order for the match to take place.
? | Matches zero or one occurrences of the immediately preceding item. For example, the pattern mo? will match "m" and "mo". |
+ | Matches one or more occurrences of the immediately preceding item. For example, the pattern mo+ will match "mo", "moo", "mooo", and so on. |
* | Matches zero or more occurrences of the immediately preceding item. |
{min,max} | Matches any number of occurrences between min and max. For example, the pattern mo{1,3} matches "mo", "moo", and "mooo". |
Parentheses
Parentheses ( and ) are used to group parts of a regex together. They can be used to apply quantifiers to a sub-expression (as opposed to just one character), or with alternation (see below).
Alternation
The vertical bar (pipe) character | means "or". It can be used to match any of the several sub-expressions separated by |. For example, the pattern (horse|make) sense will match both "horse sense" and "make sense".
Flags
These are optional parameters that define how the regular expression is to be interpreted. Each flag corresponds to a letter. Letters may be in any order and can be repeated.
s | If this flag is present, the matching process operates in the "dot-all" mode.
If the input string contains "hello" and "world" on two different lines, the regular expression hello*world will only match if the s flag is set. |
m | If this flag is present, the matching process operates in multi-line mode.
In multi-line mode, the caret ^ matches the start of any line, i.e. the start of the entire string and the first character after a newline character.
The dollar character $ matches the end of any line, i.e. the end of the entire string and the character immediately before a newline character.
Newline is the character #x0A. |
i | If this flag is present, the matching process operates in case-insensitive mode. For example, the regular expression [a-z] plus the i flag matches all letters a-z and A-Z. 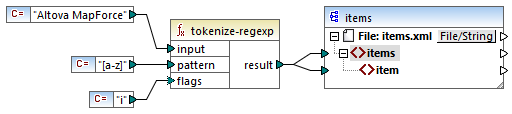 |
x | If this flag is present, whitespace characters are removed from the regular expression prior to the matching process. Whitespace characters are #x09, #x0A, #x0D and #x20.
Note: Whitespace characters within a character class are not removed, for example, [#x20]. |