CDATA Sections
CDATA sections are used to represent parts of a document as character data which would normally be interpreted as markup. For more information about CDATA sections, see the W3C Specification. Target nodes receiving data as CDATA sections can be any of the following: XML data, XML data embedded in database fields, and XML child elements of typed dimensions in an XBRL target. CDATA sections can also be defined on duplicate nodes and xsi:type nodes.
To create a CDATA section, right-click the relevant target node and select Write Content as CDATA Section. A prompt will warn you that the input data should not contain the CDATA section close-delimiter ]]>. The [C.. icon appears below the element tag, which indicates that this node is now defined as a CDATA section.
Example
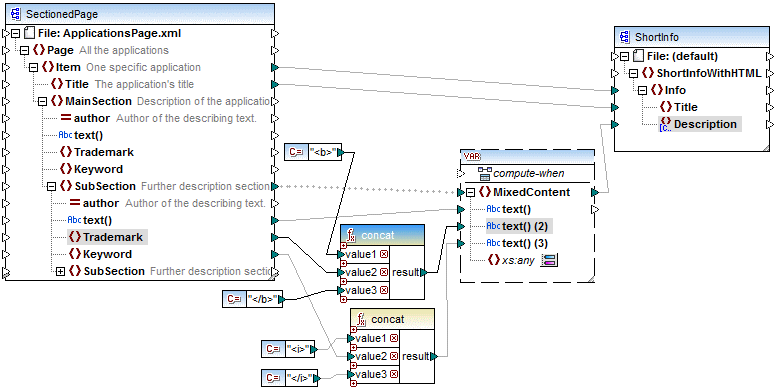
The example below shows a scenario in which a CDATA section might be useful. The sample mapping called MapForceExamples\HTMLinCDATA.mfd (see screenshot below) has the following aspects:
•The SubSection element has mixed content. For more information about mixed-content nodes, see Source-Driven Connections.
•With the help of the concat function, the content of the Trademark element will have the <b></b> tags.
•The content of the Keyword element will have the <i></i> tags.
•The data with the new tags is passed on to the duplicate text() nodes in the same order as in the source document.
•The output of the MixedContent node is then passed on to the Description node in the ShortInfo target component. The Description node has been defined as a CDATA section.
Output
Click the Output pane to see the CDATA section in the Description node (screenshot below).
