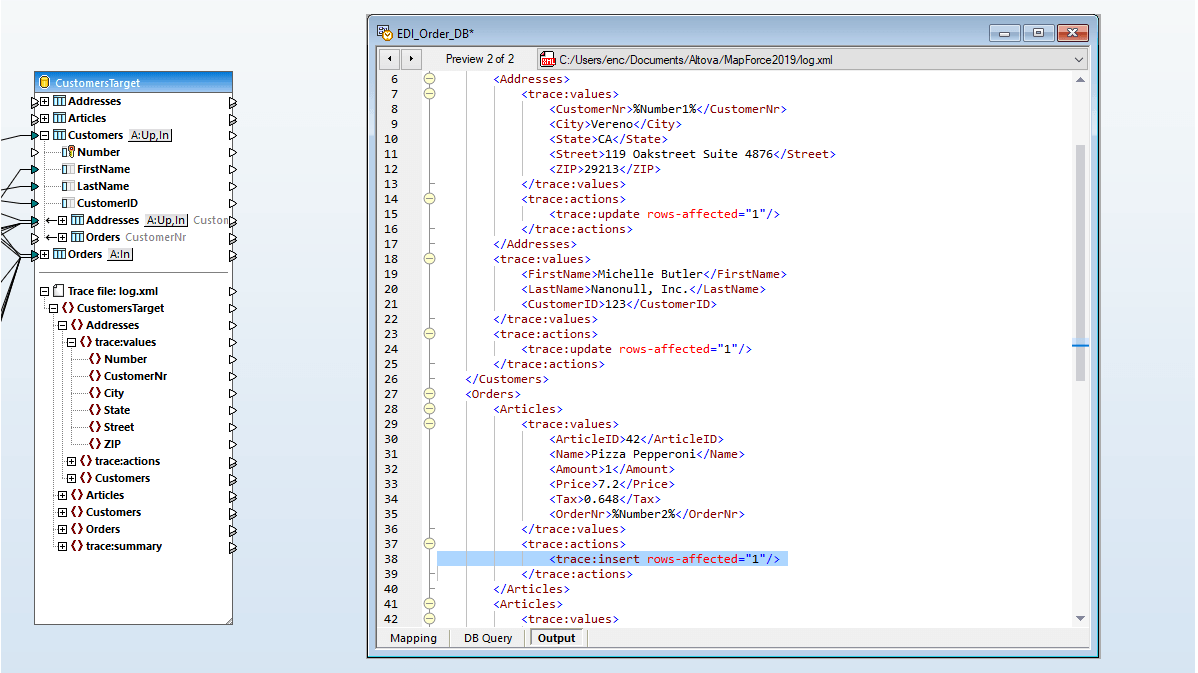
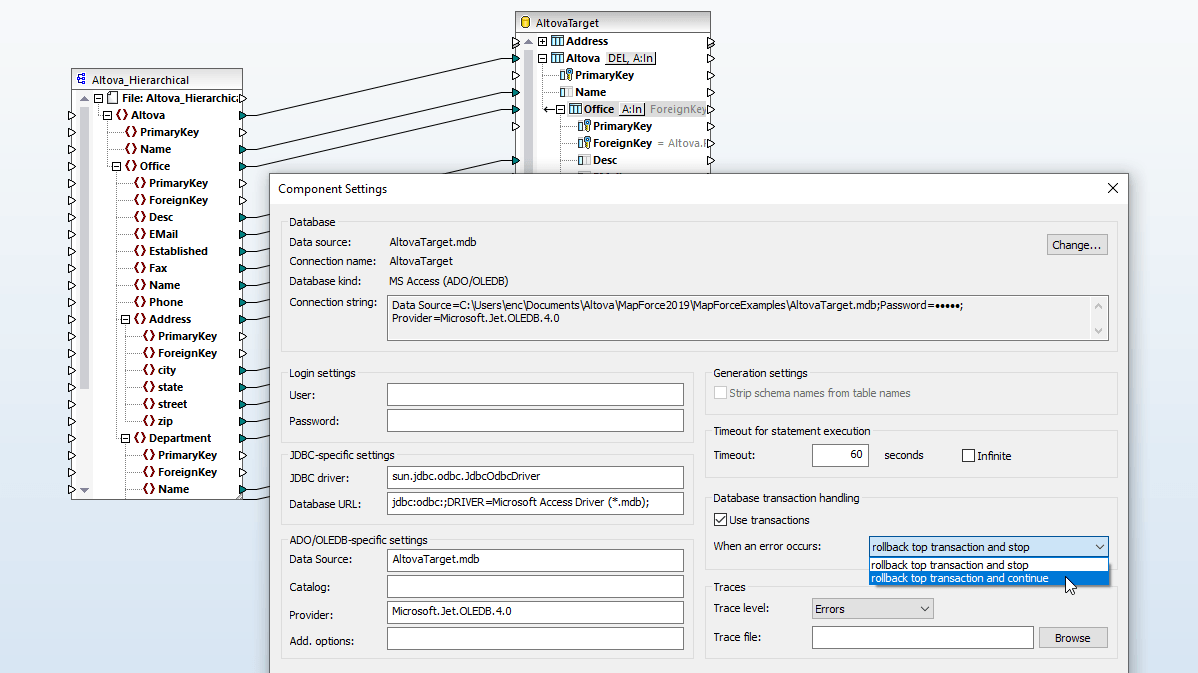
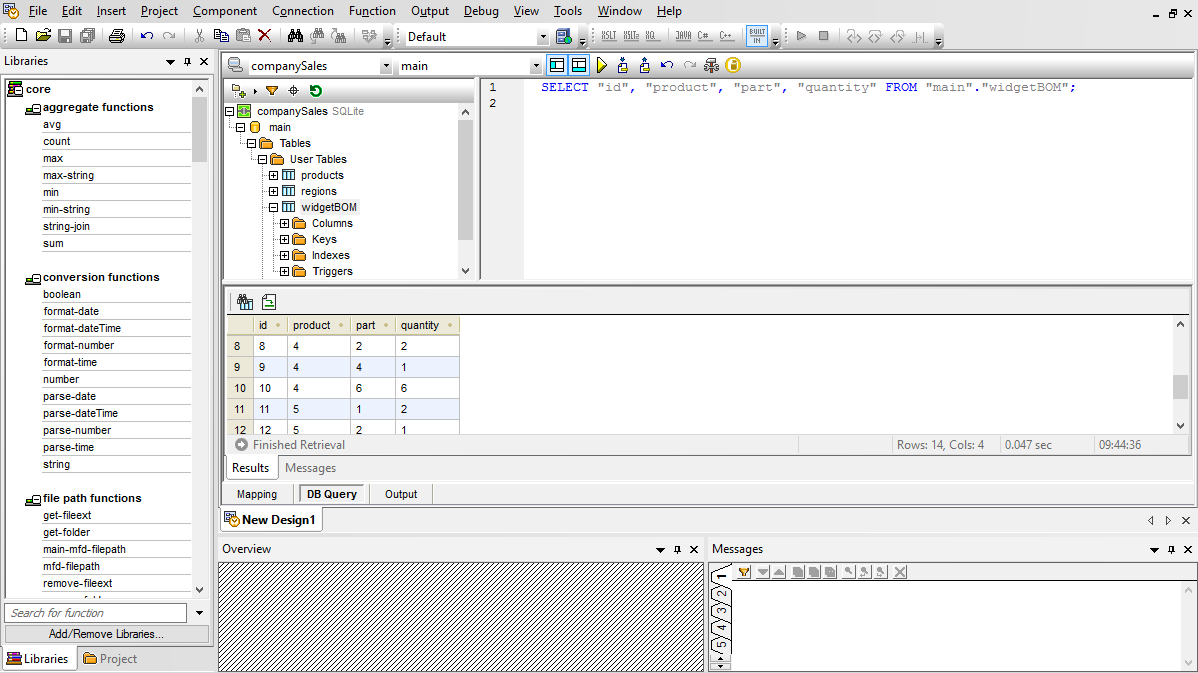
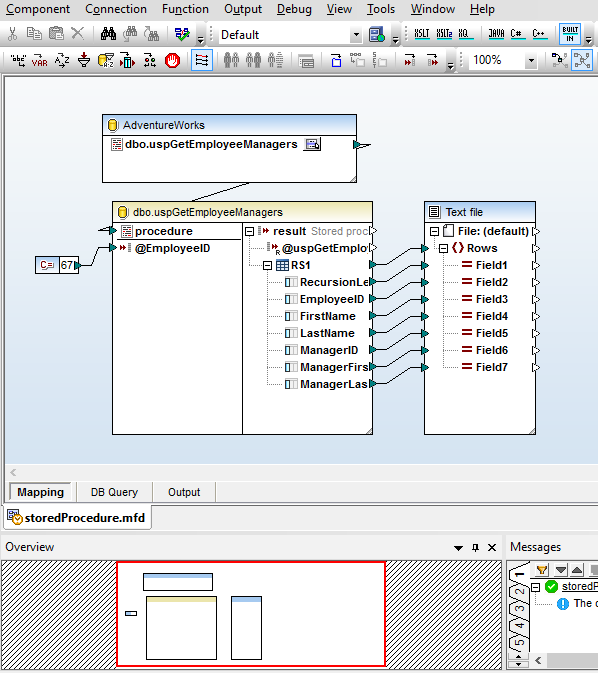
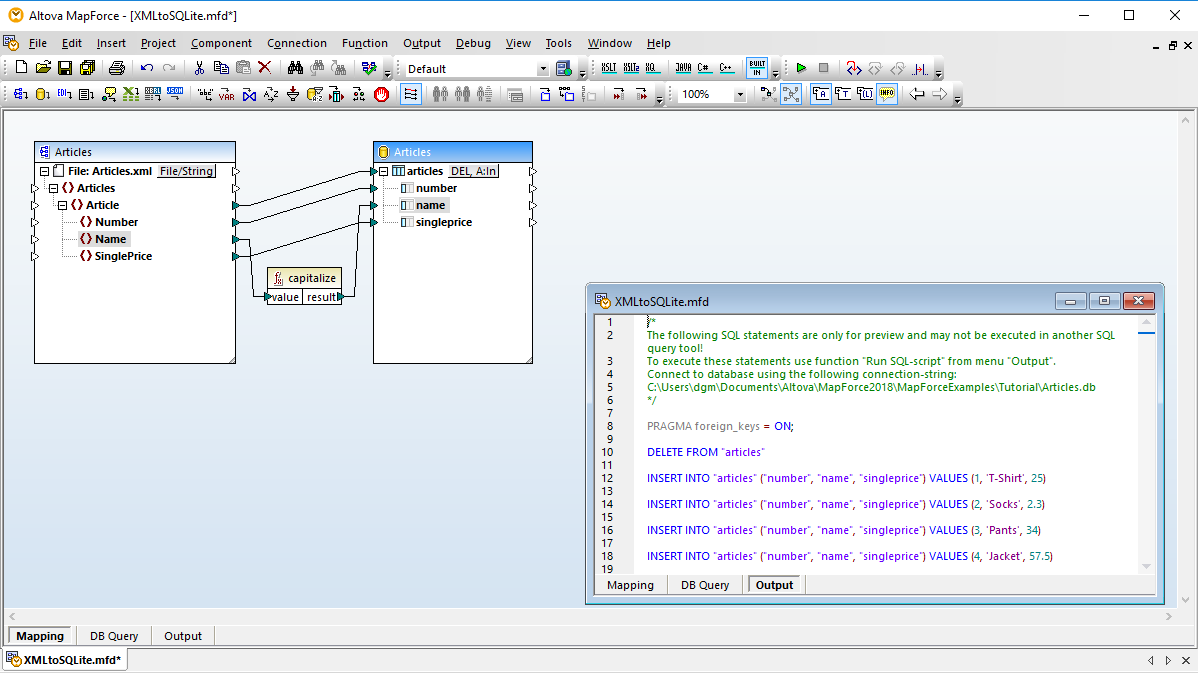
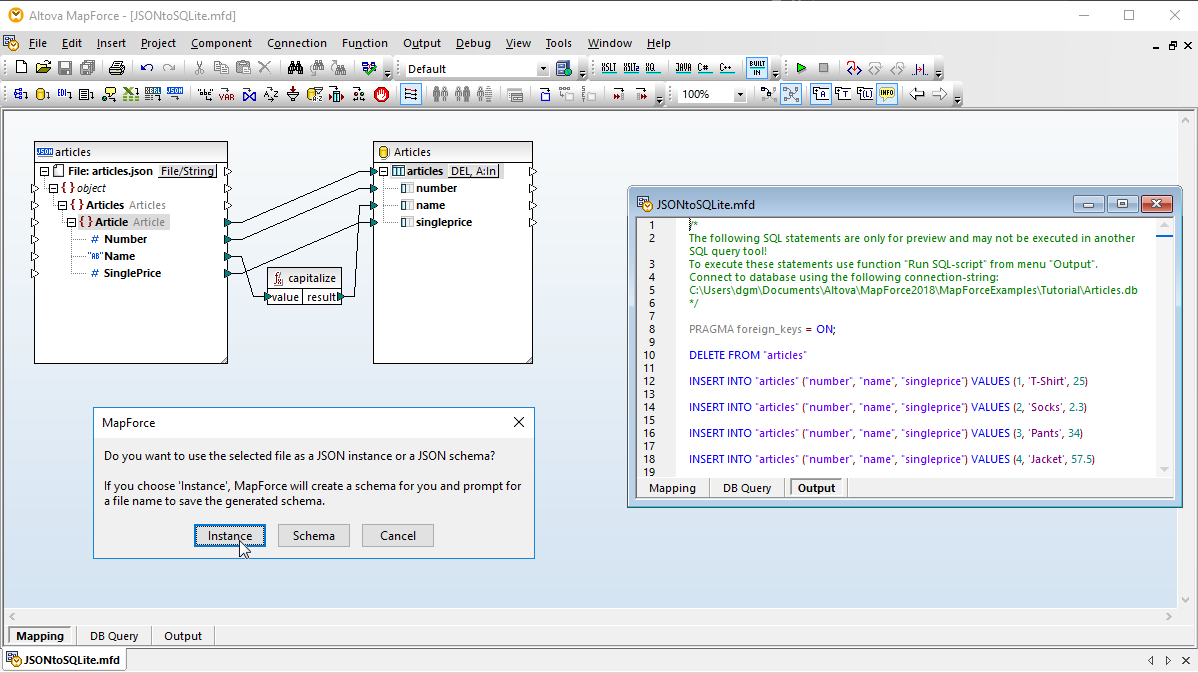
MapForce 是一款强大的数据集成和 ETL 工具,它对数据库转换提供了强大的支持。您可以将任何数据库数据转换为 XML、JSON、PDF、CSV 等各种格式的文本文件,以及 EDI、Excel、protobuf、XBRL、Web 服务、Shopify/GraphQL,甚至其他数据库格式。
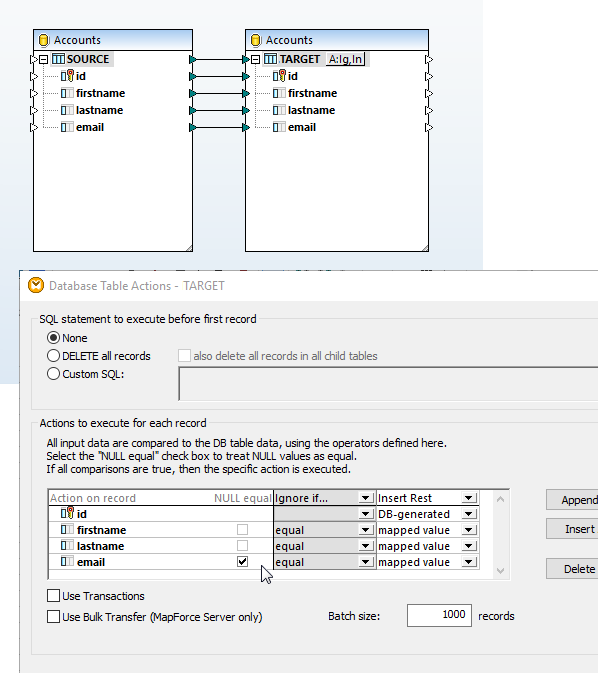
当您在设计窗口加载数据库结构时,MapForce 会自动解析数据库模式,让您选择可用的数据库表和视图,并识别表之间的关系。 这样,您就可以直观地查看数据库结构。
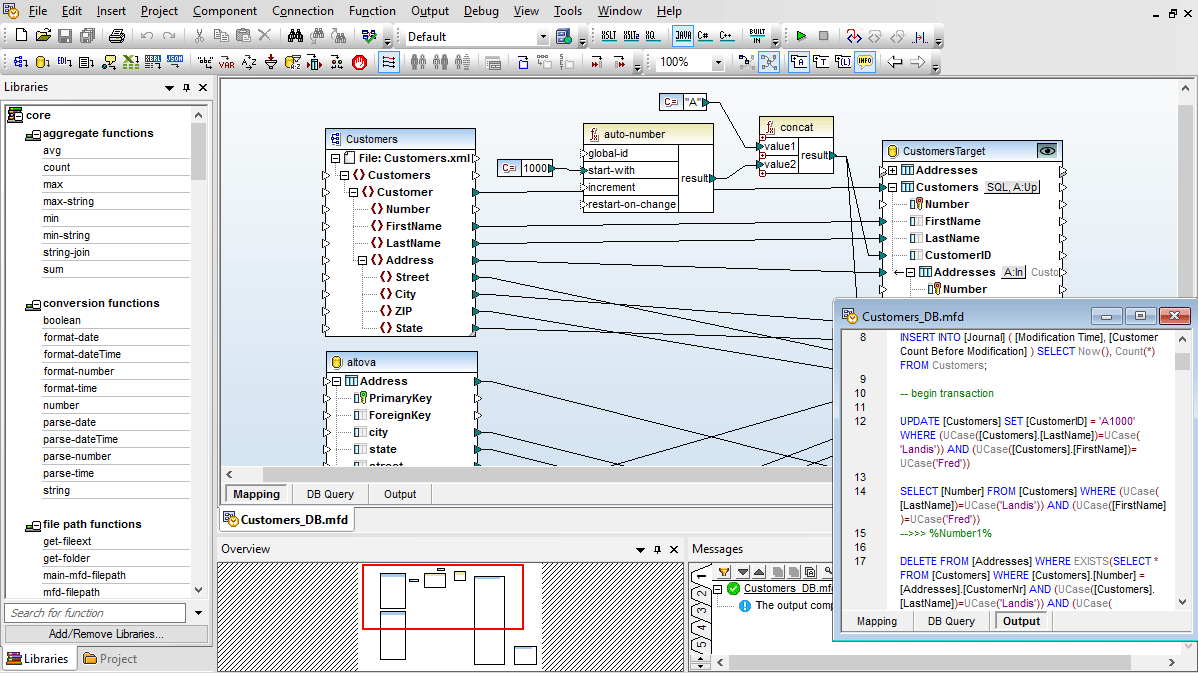
一旦您已加载数据库映射所需的所有内容模型,只需通过拖动连接线,将源结构和目标结构连接起来,即可完成映射过程。
支持 关系型的 数据库:
- Firebird
- IBM DB2 for iSeries®
- IBM DB2®
- Informix®
- MariaDB
- Microsoft Access™
- Microsoft® Azure SQL
- Microsoft® SQL Server®
- MySQL®
- Oracle®
- PostgreSQL
- Progress OpenEdge
- SQLite
- Sybase® ASE
- Teradata
支持 NoSQL 数据库:
- MongoDB
- CouchDB
- 微软 Azure Cosmos DB
MapForce 支持所有主流的关系型数据库,以及流行的 NoSQL 数据库,让您能够创建图形化的数据库映射设计,连接数据库源数据、数据处理函数和过滤器,以及各种类型的数据结构。这使得它能够支持常见的数据库迁移场景,例如 从 MySQL 迁移到 PostgreSQL,以及无数其他可能性,包括一对多关系和链式数据转换。