Mappage de bases de données et ETL avancé
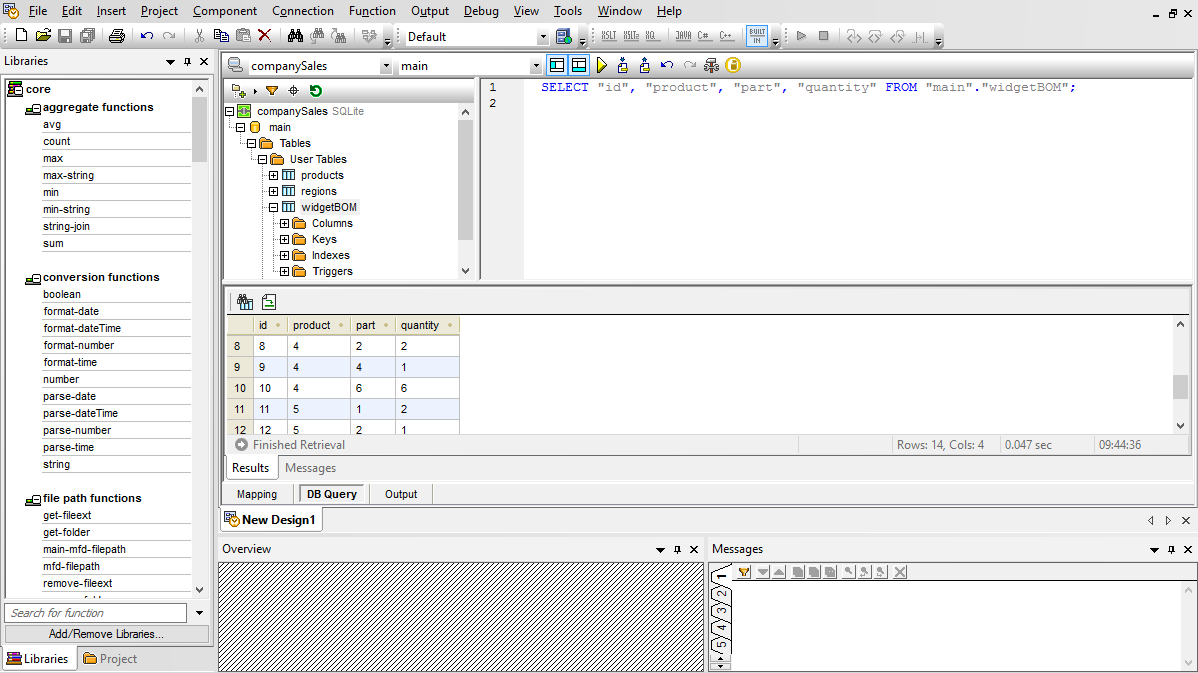
Pour les utilisateurs qui travaillent avec SQL, MapForce inclut un onglet de Requête de base de données pour l'exécution directe de requêtes de bases de données. Lorsque vous vous connectez à une base de données à l'aide de l'onglet de Requête de base de données, MapForce affiche ses tables dans une arborescence hiérarchique dans le panneau de navigation.
Vous pouvez ensuite utiliser l'onglet d'éditeur SQL pour afficher, éditer et exécuter les instructions SQL ou SQL/XML, soit en ouvrant des fichiers SQL existants, soit en créant des instructions SQL à partir de zéro en utilisant les fonctions glisser/déposer et de remplissage automatique.
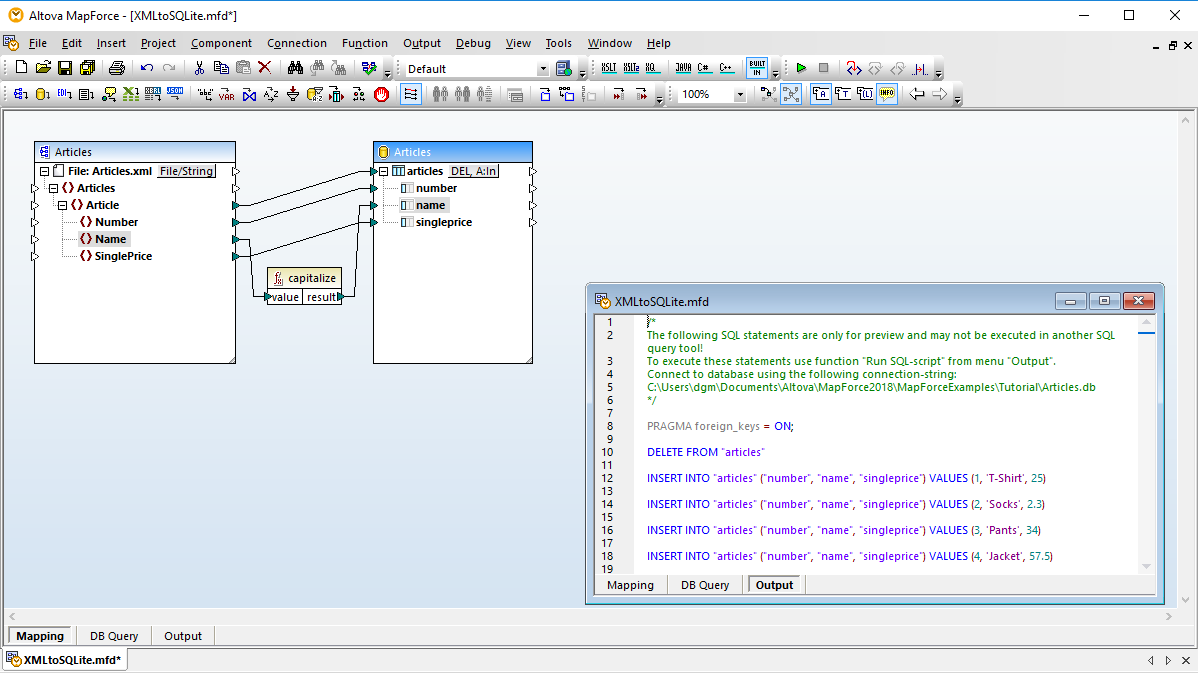
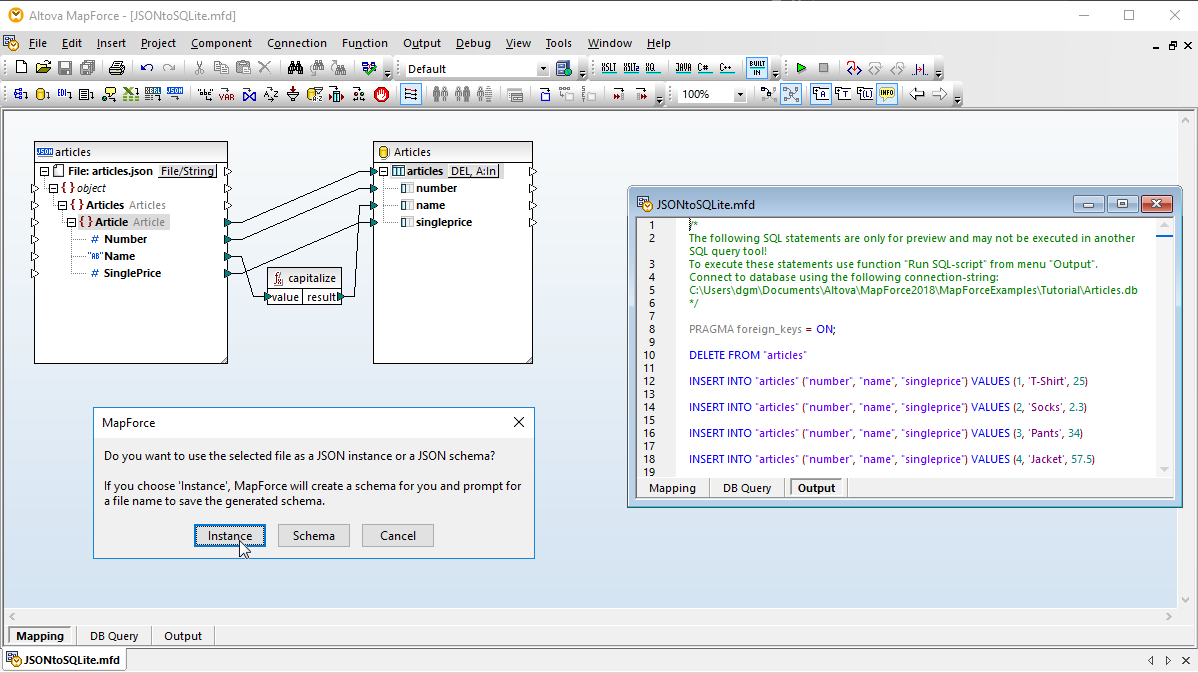
Vous pouvez exécuter votre script SQL et afficher les résultats de manière tabulaire et vous pouvez enregistrer les données extraites et le script SQL individuellement dans des fichiers séparés.
Paramètres clés de base de données
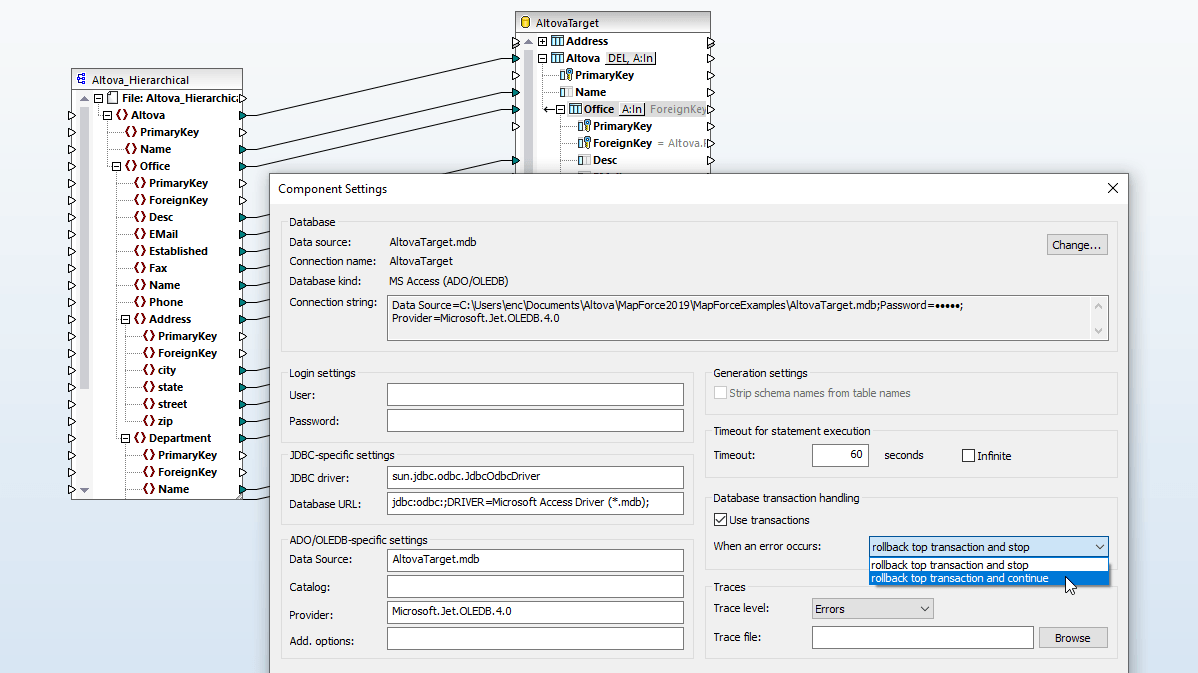
Les paramètres clés de base de données MapForce vous permettent de personnaliser comment ajouter les valeurs clé primary et foreign à une base de données qui est une cible de mappage de données. Vous pouvez soit fournir des valeurs pour les clés depuis MapForce, soit laisser le système de base de données gérer la génération des valeurs automatiques.
Dans des situations où les relations clé primary et/ou foreign ne sont pas définies explicitement dans vos tables de base de données, MapForce vous permet de définir ces relations inline, sans effet sur les données de source.
Définir les actions de table de base de données
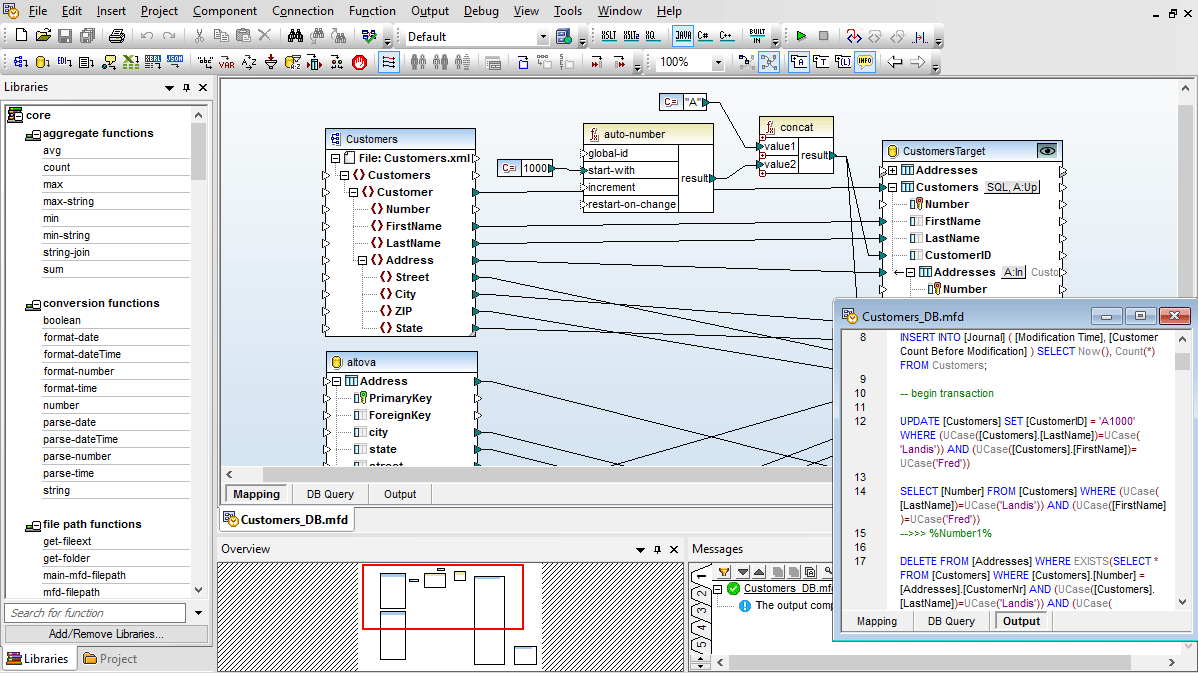
Lorsque vous mappez sur une base de données, MapForce vous permet de sélectionner les actions de tables de base de données pour contrôler la manière dont les données sont écrites dans la base de données. Cela vous confère une pleine flexibilité pour automatiser les tâches de gestion de données les plus avancées.
La fenêtre de dialogue conviviale Actions de table de base de données vous permet de définir les colonnes dans lesquelles la table sélectionnée sera utilisée afin de déterminer quelle action (INSERT, UPDATE, DELETE) doit être exécutée dans la base de données.
Cela vous confère une flexibilité inouïe dans la manipulation des lignes de base de données en réponse aux données XML, base de données, EDI, XBRL, fichier plat, Excel, JSON, services Web ou autres données de base de données par le biais de MapForce.
Prise en charge des Procédures stockées SQL
MapForce offre une prise en charge robuste pour les procédures stockées en tant que composants d'entrée (des procédures qui fournissent des résultats) ou en tant que composants de sortie (des procédures qui insèrent ou mettent à jour des données). Ou bien encore, les procédures stockées peuvent être insérées en tant qu'un appel semblable à une fonction permettant aux utilisateurs de fournir des données d'entrée, d'exécuter la procédure stockée et de lire/mapper les données de sortie en d'autres composants.
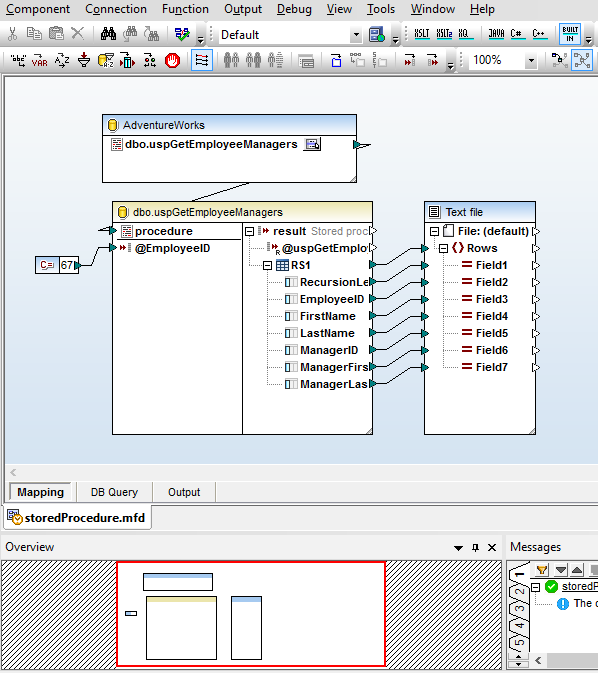
Cette capture d'écran montre le mappage d'une procédure stockée dans un serveur SQL Server pour créer un fichier XML. La procédure retourne une table de données affichant tous les managers contenus dans la chaîne de commande situés au-dessus de l'ID de l'employé spécifié, fournie en tant que paramètre d'entrée. Dans cet exemple, la constante 67.
Le paramètre peut aussi être fourni en tant que valeur calculée ou en tant qu'élément de données extrait d'un autre endroit dans la base de données.
MapForce fournit un menu contextuel qui permet aux utilisateurs d'exécuter la procédure stockée pour révéler la structure de données pour le mappage. L'exécution du mappage illustré génère la sortie XML.
Mapper XML stocké dans les champs de BD
MapForce permet aussi de vous connecter à et de mapper les données de bases XML stockées dans les champs de base de données relationnelles (actuellement prise en charge du serveur SQL & IBM DB2). Vous pouvez simplement attribuer un schéma XML au champ, et MapForce rend le schéma en tant que sous-arborescence du champ de la base de données à des fins de mappage.
Trier les composants d'entrée de base de données
Les requêtes SQL qui fonctionnent dans la base de données ne sont pas toujours suffisantes pour les tâches de mappage de données complexes. MapForce fournit des fonctions de tri de base de données supplémentaires par le biais du composant SQL-WHERE/ORDER pour l'entrée de base de données qui nécessite un traitement supplémentaire.
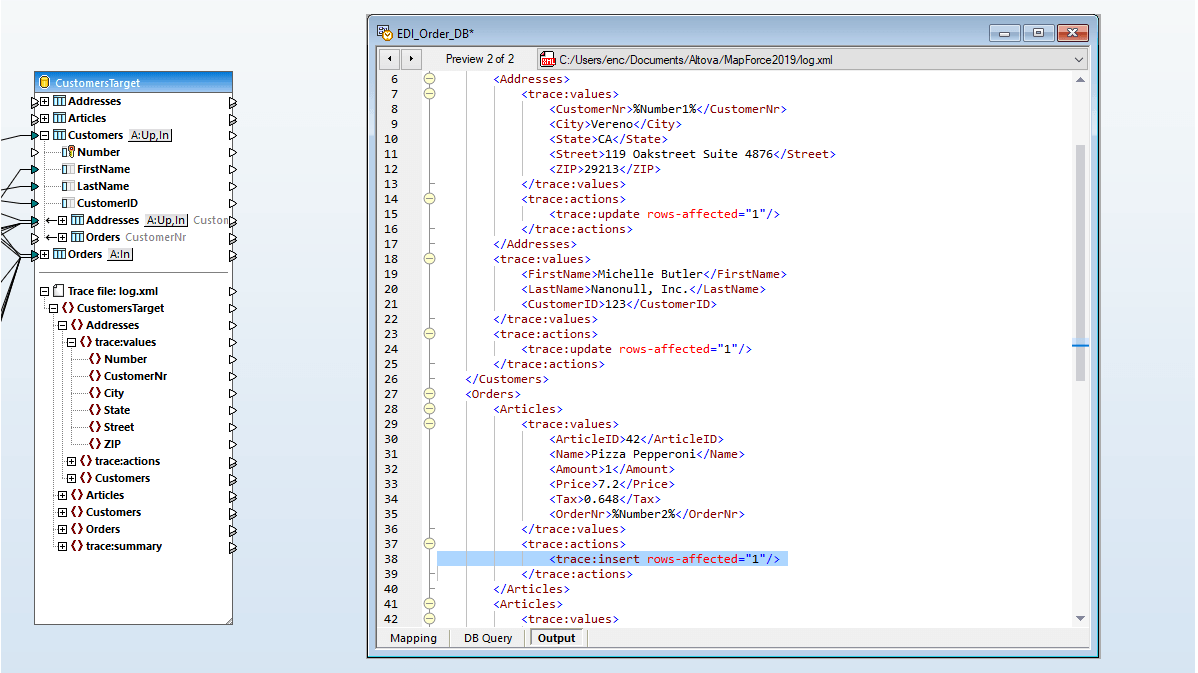
Prise en charge des valeurs NULL dans les actions de table de base de données
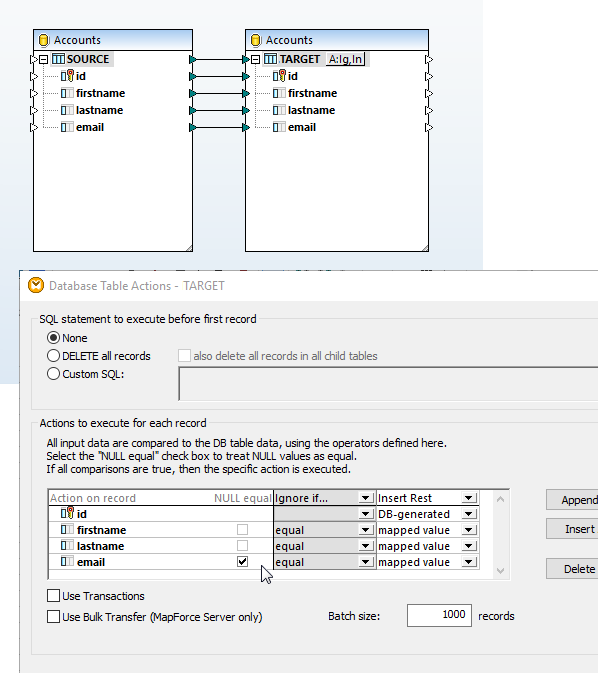
Le dialogue Actions de table de base de données prend en charge la comparaison de valeur NULL. Les comparaisons NULL-aware permettent de mieux gérer des BD qui contiennent des valeurs null. Les utilisateurs de MapForce peuvent configurer un mappage de BD pour faire une comparaison de données de manière NULL-aware.
Le mappage de données à droite a pour but de mettre à jour la table cible sans insérer des entrées doubles. Les deux tables sont définies, permettant au champ d'e-mail d'être NULL, donc les entrées de nom correspondantes avec des champs d'e-mail NULL peuvent exister dans chaque table.
Cliquer sur l'icône Actions à côté de la table de base de données CIBLE. La case à cocher NULL égal située à côté du champ E-mail permet à MapForce de traiter les valeurs NULL dans la source et la cible de manière égale, même si elles ne sont pas considérées comme égales de par les règles de base de données.