고급 데이터베이스 매핑 및 ETL (추출, 변환, 적재) 솔루션
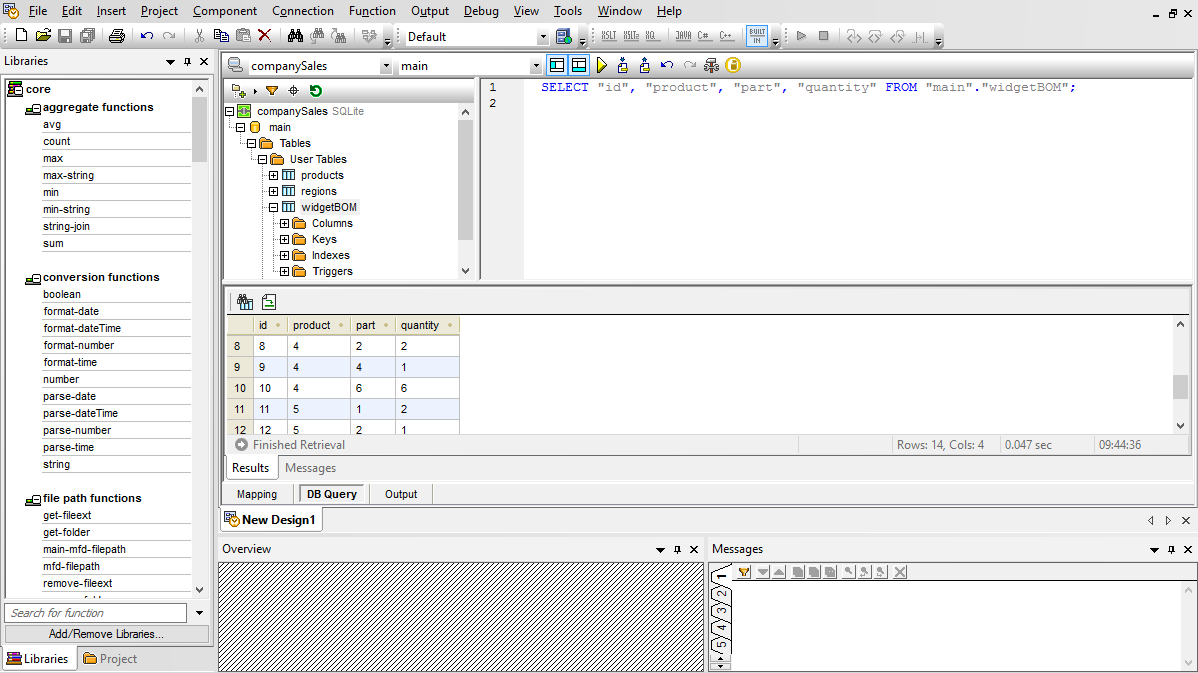
SQL을 사용하는 사용자를 위해 MapForce는 데이터베이스에 직접 쿼리를 수행할 수 있는 "데이터베이스 쿼리" 탭을 제공합니다. "데이터베이스 쿼리" 탭을 사용하여 데이터베이스에 연결하면, MapForce는 해당 데이터베이스의 테이블들을 계층 구조 트리 형태로 브라우저 창에 표시합니다.
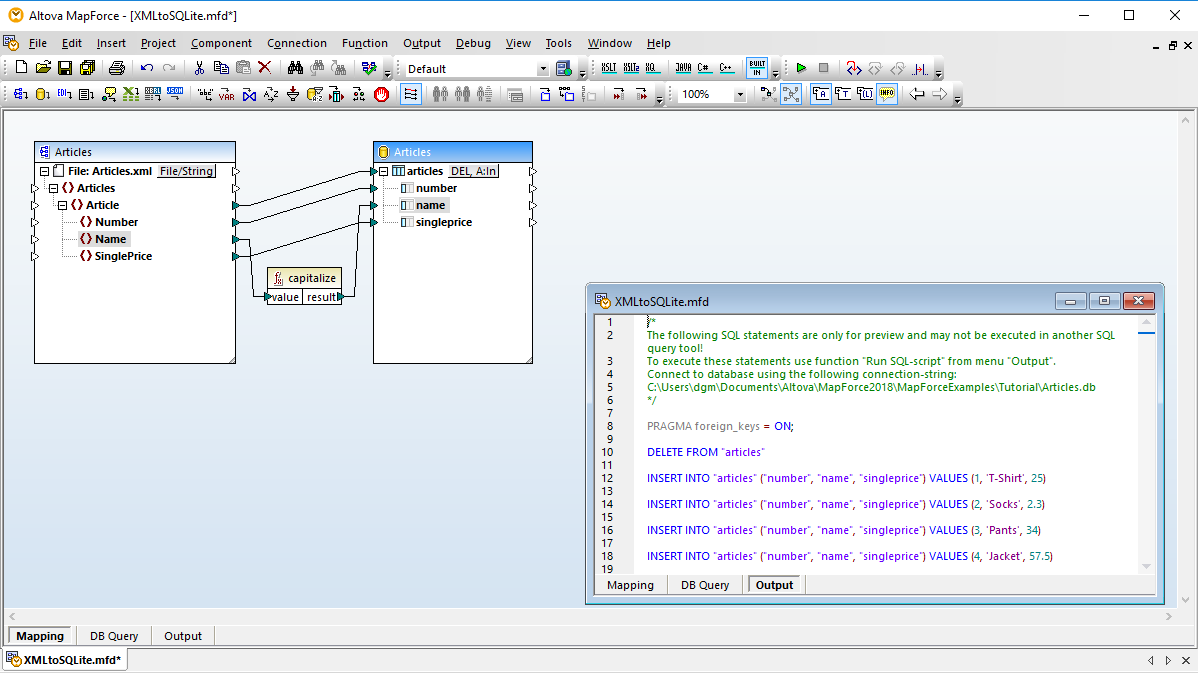
SQL 편집기 탭을 사용하여 기존 SQL 파일을 열거나, 드래그 앤 드롭 기능과 자동 완성 기능을 활용하여 SQL 또는 SQL/XML 문장을 직접 작성하고, 이를 표시, 편집 및 실행할 수 있습니다.
SQL 스크립트를 실행하고 결과를 표 형식으로 확인할 수 있으며, 검색된 데이터와 SQL 스크립트를 각각 별도의 파일로 저장할 수 있습니다.
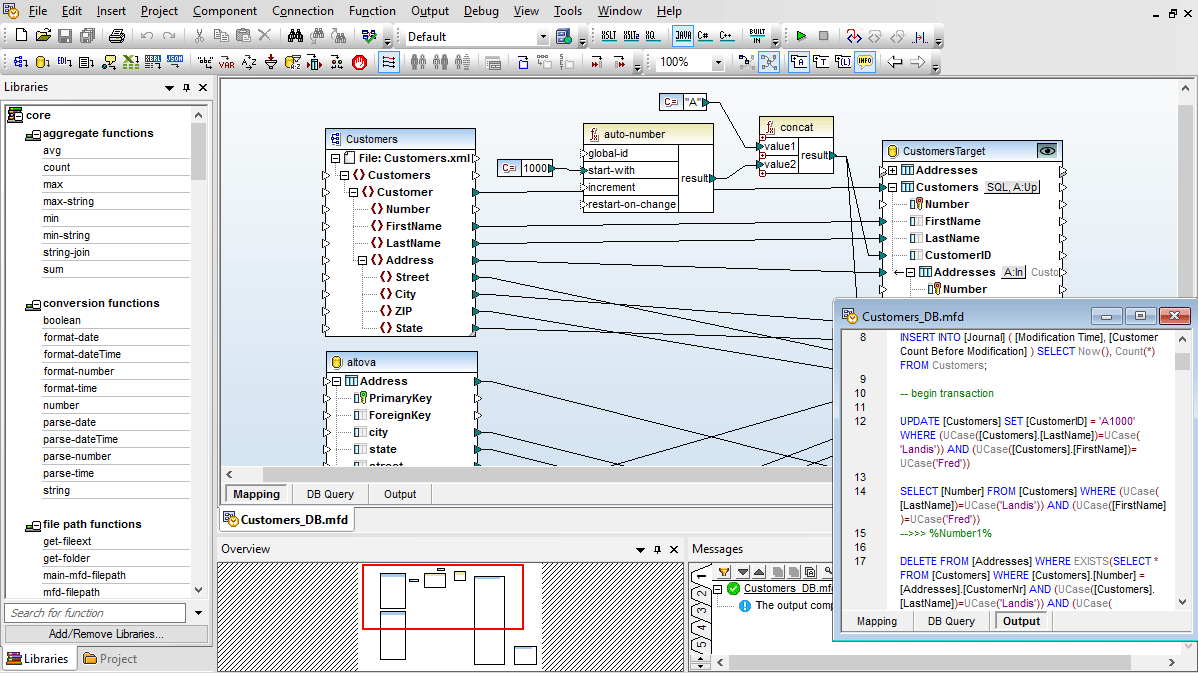
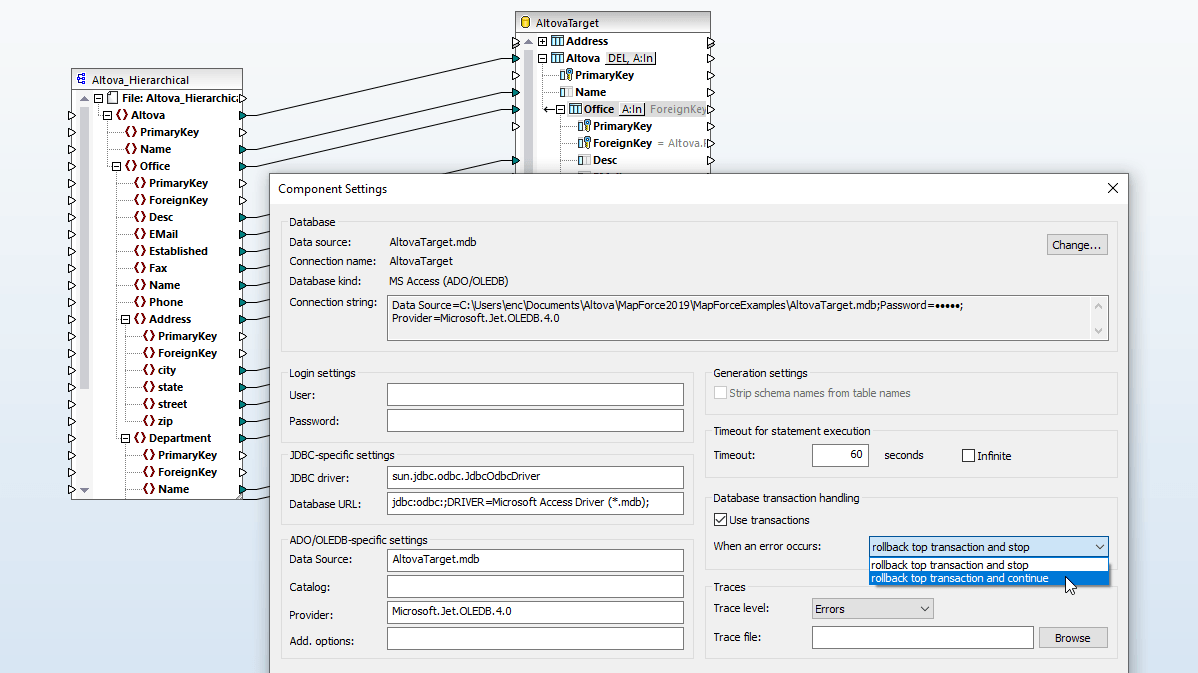
MapForce의 데이터베이스 키 설정은 데이터 매핑 대상이 되는 데이터베이스에 기본 키와 외래 키 값을 어떻게 추가할지 사용자 정의할 수 있도록 해줍니다. 사용자는 MapForce 내에서 직접 키 값을 제공하거나, 데이터베이스 시스템이 자동으로 값을 생성하도록 설정할 수 있습니다.
데이터베이스 테이블에서 기본 키 또는 외래 키 관계가 명시적으로 정의되어 있지 않은 경우, MapForce를 사용하면 원본 데이터에 영향을 주지 않고 해당 관계를 직접 정의할 수 있습니다.
데이터베이스에 데이터를 매핑할 때, MapForce를 사용하면 데이터베이스 테이블 작업(database table actions)을 선택하여 데이터가 데이터베이스에 어떻게 저장될지 제어할 수 있습니다. 이를 통해 가장 복잡한 데이터 관리 작업을 자동화할 수 있는 완벽한 유연성을 제공합니다.
사용하기 쉬운 "데이터베이스 테이블 작업" 대화 상자를 통해, 선택한 테이블 내의 특정 열을 지정하여 데이터베이스에서 어떤 작업(삽입, 수정, 삭제)을 수행할지 설정할 수 있습니다.
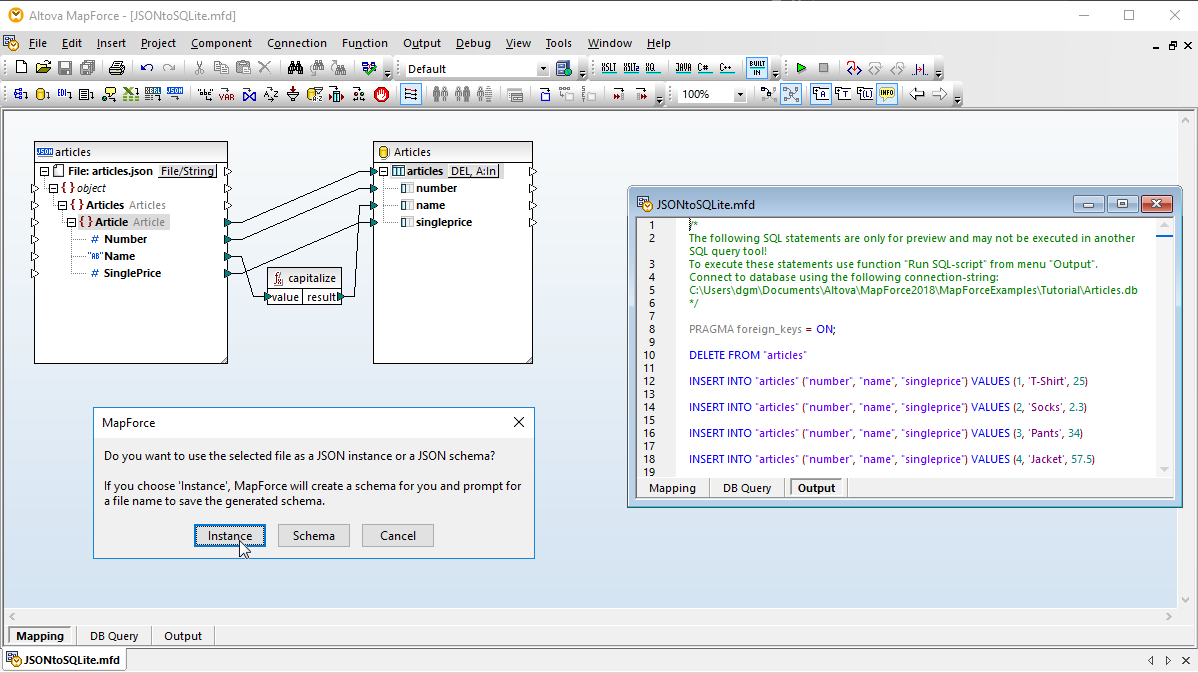
MapForce를 통해 XML, 데이터베이스, EDI, XBRL, 일반 파일, 엑셀, JSON, JSON5, 웹 서비스 또는 기타 데이터베이스 데이터를 활용하여 데이터베이스의 행을 이전에는 불가능했던 수준으로 자유롭게 조작할 수 있습니다.
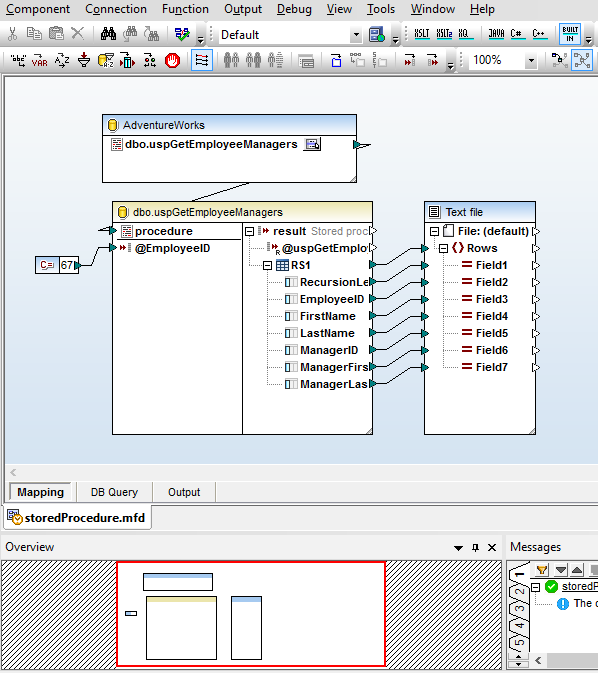
MapForce는 저장 프로시저를 입력 구성 요소(결과를 제공하는 프로시저) 또는 출력 구성 요소(데이터를 삽입하거나 업데이트하는 프로시저)로 강력하게 지원합니다. 또한, 저장 프로시저를 함수처럼 호출하여 사용할 수도 있습니다. 이 경우 사용자는 입력 데이터를 제공하고, 저장 프로시저를 실행한 후, 출력 데이터를 다른 구성 요소에 연결하거나 활용할 수 있습니다.
이 스크린샷은 SQL Server에서 저장 프로시저를 사용하여 XML 파일을 생성하는 과정을 보여줍니다. 이 프로시저에서는 입력 매개변수로 제공된 특정 직원 ID(이 예에서는 상수 67)보다 상위 계층에 있는 모든 관리자들의 정보를 담은 테이블을 반환합니다.
이 파라미터는 계산된 값으로 제공될 수도 있고, 데이터베이스의 다른 부분에서 가져온 데이터 요소로 제공될 수도 있습니다.
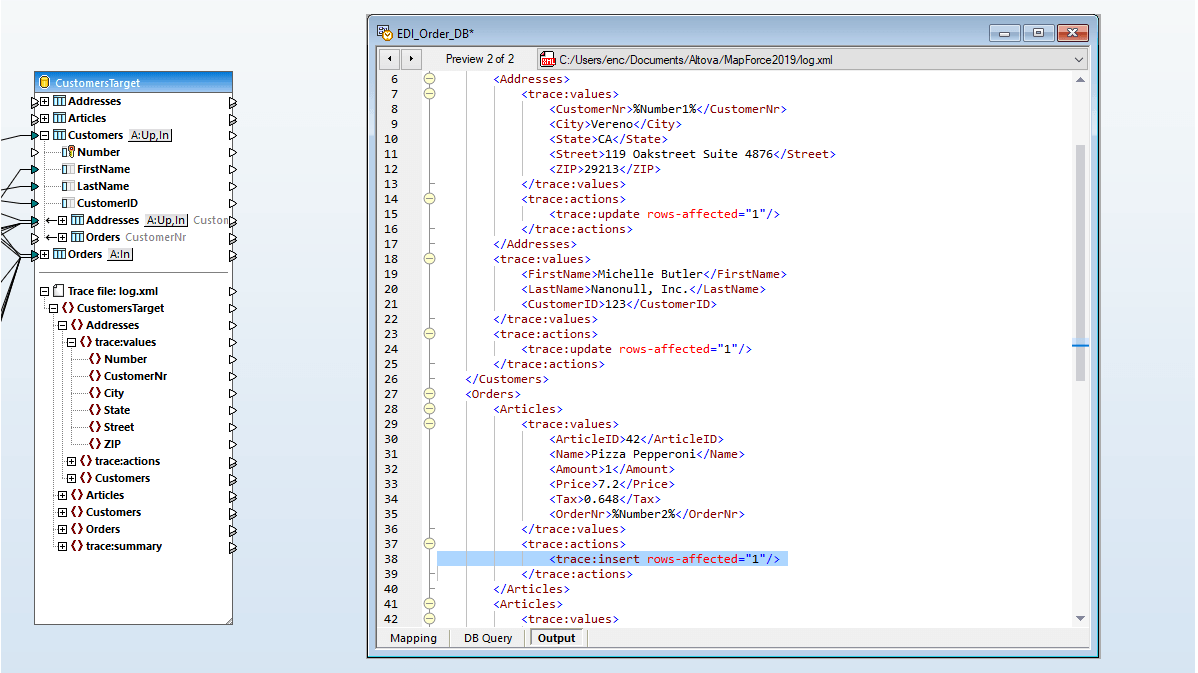
MapForce는 컨텍스트 메뉴를 제공하여 사용자가 저장된 프로시저를 실행하고, 매핑에 필요한 데이터 구조를 확인할 수 있도록 합니다. 제시된 매핑을 실행하면 XML 형식의 결과물이 생성됩니다.
지도 XML 데이터가 데이터베이스 필드에 저장됨
MapForce는 관계형 데이터베이스 필드에 저장된 XML 데이터를 연결하고 매핑할 수 있습니다 (현재 SQL Server 및 IBM DB2를 지원). 사용자는 데이터베이스에 등록된 XML 스키마 또는 로컬 파일 시스템의 스키마를 해당 필드에 할당하면, MapForce는 해당 스키마를 데이터베이스 필드의 하위 트리로 렌더링하여 매핑 작업을 수행할 수 있도록 합니다.
데이터베이스 내에서 실행되는 SQL 쿼리는 복잡한 데이터 매핑 작업에 항상 충분하지 않을 수 있습니다. MapForce는 SQL-WHERE/ORDER 컴포넌트를 통해 데이터베이스 입력에 대한 추가적인 정렬 기능을 제공합니다. 이는 추가적인 처리가 필요한 경우, 또는 매핑 과정에서 다른 데이터나 조건이 데이터 행의 정렬 순서에 영향을 미치는 경우에 유용합니다.
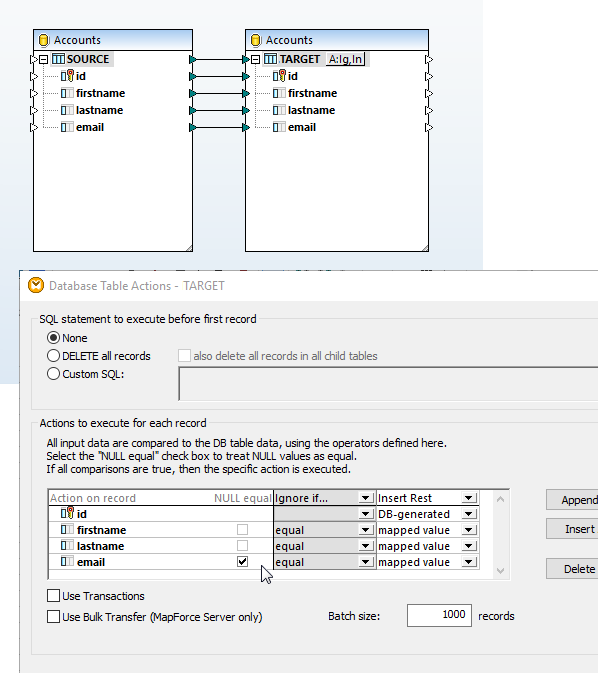
데이터베이스 테이블 작업에서 NULL 값 지원
데이터베이스 테이블 작업 대화 상자는 NULL 값 비교를 지원합니다. NULL 값을 고려한 비교 기능은 NULL 값이 포함된 데이터베이스를 처리하는 데 더 효과적인 방법을 제공합니다. MapForce 사용자는 데이터 비교를 NULL 값을 고려하여 수행하도록 데이터베이스 매핑을 설정할 수 있으며, 이는 매핑에 관련된 데이터베이스 유형에 적용되는 규칙에 따라 이루어집니다.
오른쪽에 표시된 데이터 매핑은 중복 항목을 삽입하지 않고 대상 테이블을 업데이트하는 데 사용됩니다. 두 테이블 모두 "이메일" 필드가 NULL 값을 가질 수 있도록 정의되어 있으므로, 각 테이블에서 이름은 동일하지만 이메일 필드가 NULL인 항목이 존재할 수 있습니다.
"작업" 아이콘을 클릭하면 대상 데이터베이스 테이블 옆에 "데이터베이스 작업" 대화 상자가 열립니다. 이메일 필드 옆에 있는 "NULL 값 동일" 확인란을 선택하면, 매핑 과정에서 소스 및 대상 데이터베이스의 NULL 값을 동일한 것으로 간주할 수 있습니다. 이는 데이터베이스 규칙상 NULL 값은 동일하지 않더라도, 데이터 매핑의 편의를 위해 설정하는 기능입니다.