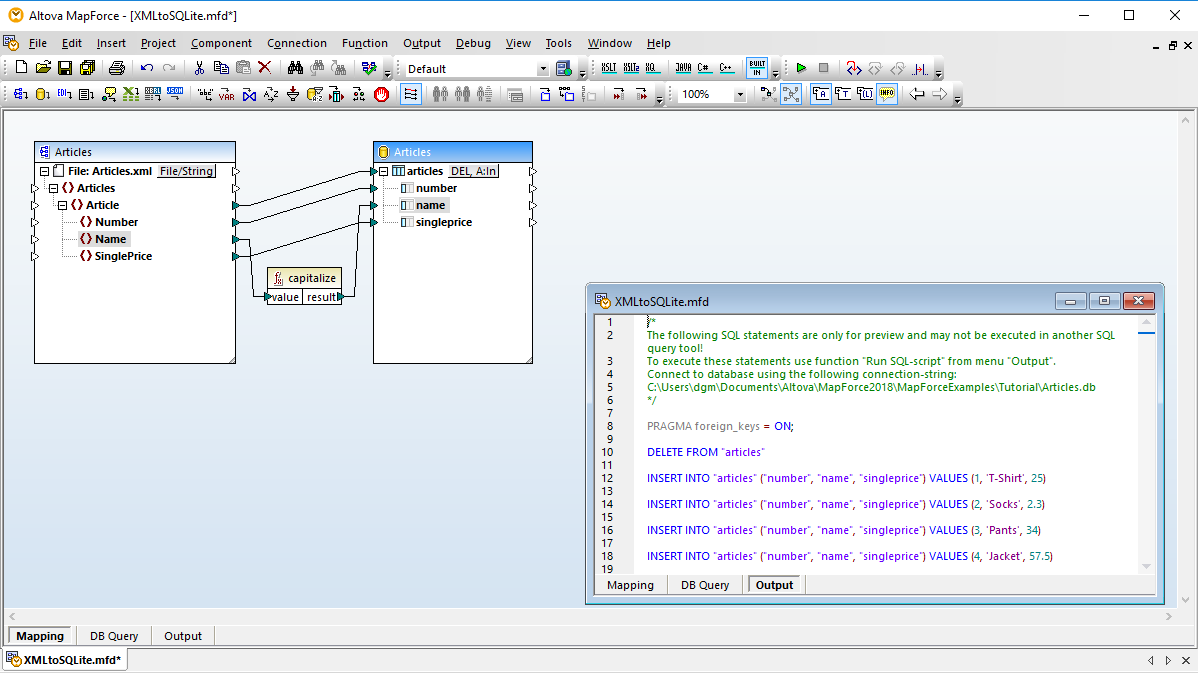
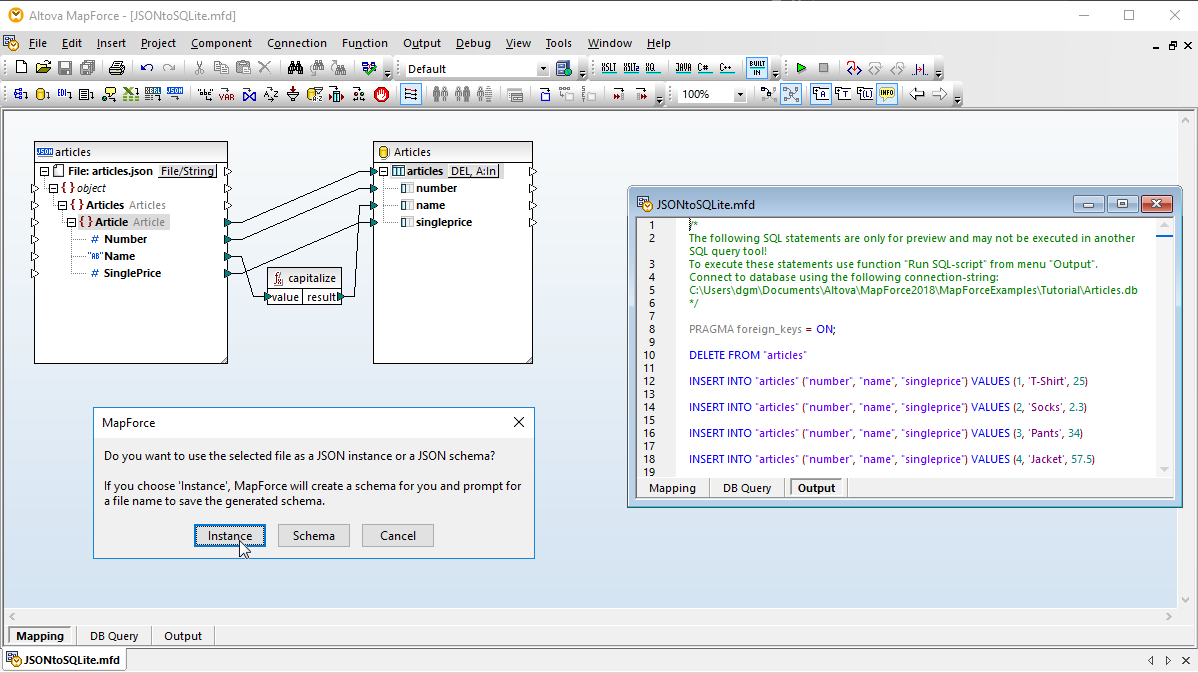
Mapeamento avançado de bases de dados e ETL (Extração, Transformação e Carga)
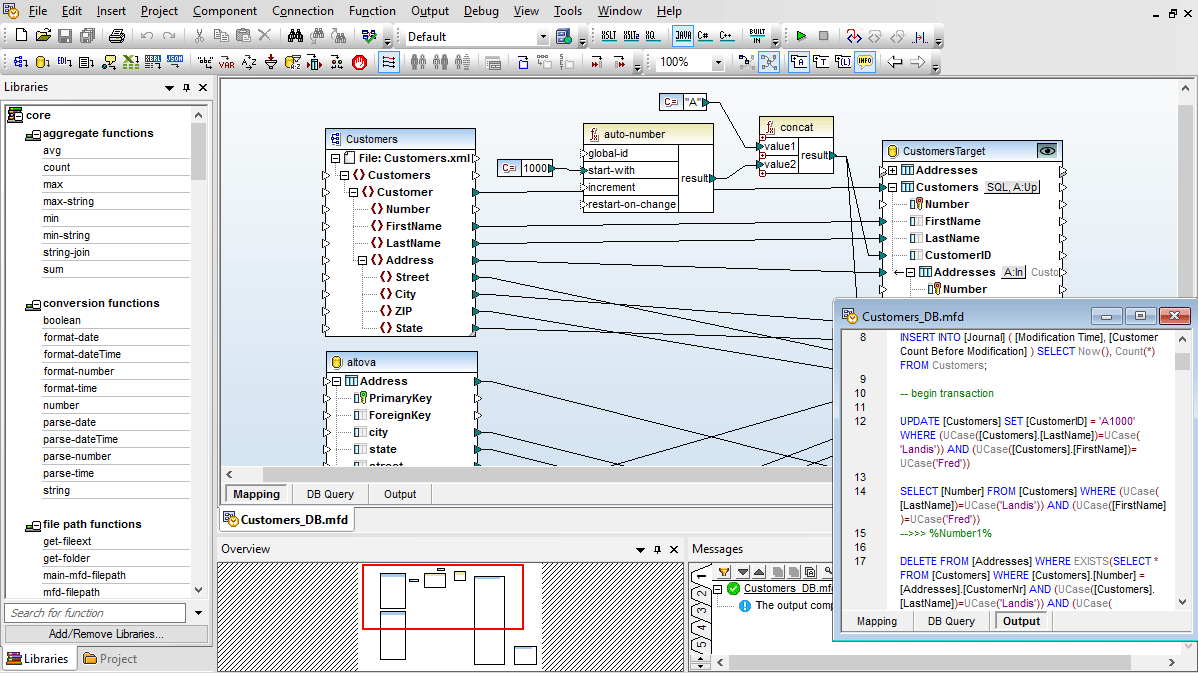
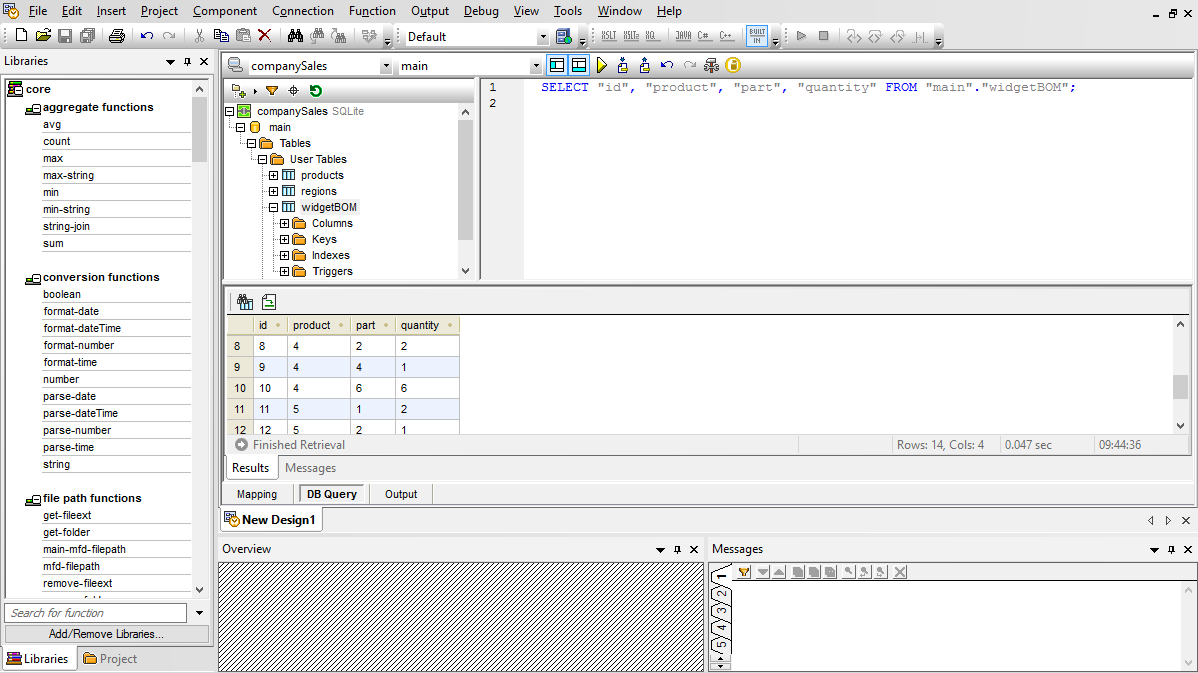
Para utilizadores que trabalham com SQL, o MapForce inclui uma aba "Consulta de Base de Dados" para realizar consultas diretas à base de dados. Quando se conecta a uma base de dados através da aba "Consulta de Base de Dados", o MapForce exibe as tabelas da base de dados numa estrutura hierárquica na janela do navegador.
Pode, então, utilizar a aba do editor SQL para visualizar, editar e executar instruções SQL ou SQL/XML, seja abrindo ficheiros SQL existentes ou criando instruções SQL do zero, utilizando funcionalidades de arrastar e soltar e de autocompletar.
Pode executar o seu script SQL e visualizar os resultados em formato tabular, e também pode guardar tanto os dados obtidos como o próprio script SQL, individualmente, em ficheiros separados.
Configurações das chaves da base de dados
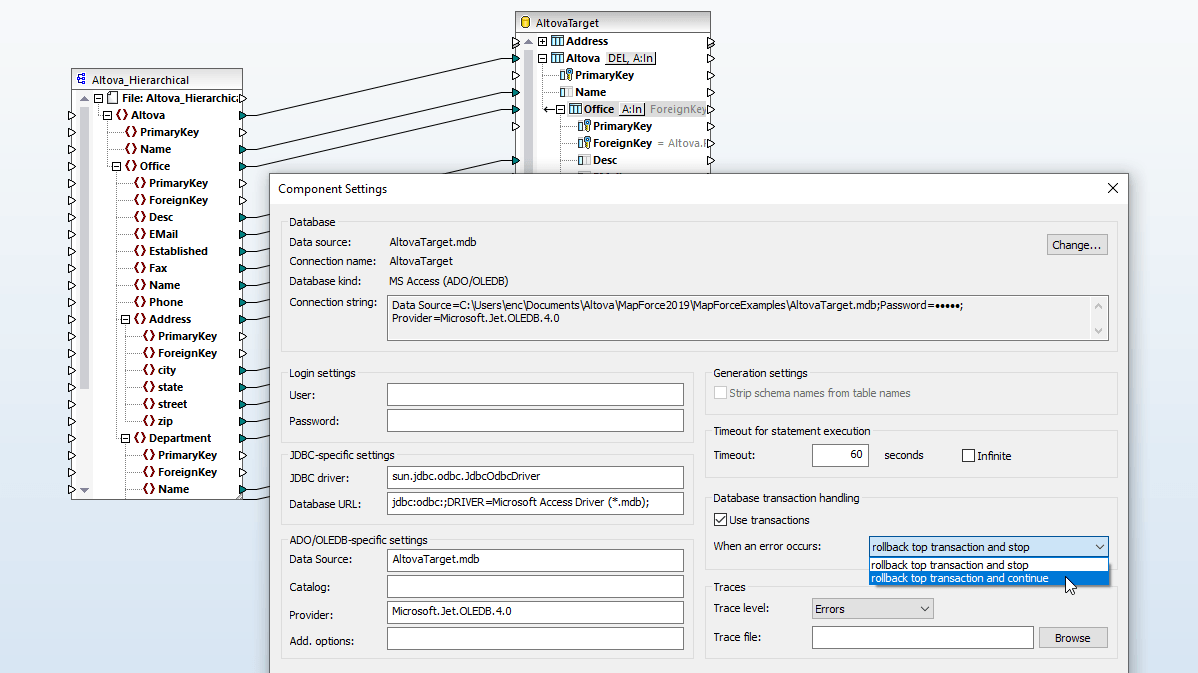
As configurações de chaves de base de dados no MapForce permitem personalizar a forma como os valores das chaves primárias e estrangeiras serão adicionados a uma base de dados que é o destino do mapeamento de dados. Pode fornecer os valores das chaves diretamente no MapForce, ou pode deixar que o sistema de base de dados gere automaticamente esses valores.
Em situações em que as relações de chave primária e/ou chave estrangeira não estão explicitamente definidas nas suas tabelas de base de dados, o MapForce permite que defina estas relações diretamente, sem qualquer impacto nos dados de origem.
Definir ações para tabelas de base de dados
Quando está a mapear para uma base de dados, o MapForce permite-lhe selecionar ações para as tabelas da base de dados, permitindo controlar como os dados são gravados na base de dados. Isto oferece-lhe total flexibilidade para automatizar as tarefas de gestão de dados mais avançadas.
A caixa de diálogo "Ações da Tabela de Base de Dados", de fácil utilização, permite definir as colunas da tabela selecionada que serão utilizadas para determinar qual ação (INSERIR, ATUALIZAR, ELIMINAR) deve ser executada na base de dados.
Isto oferece uma flexibilidade sem precedentes na manipulação de linhas de bases de dados, em resposta a dados XML, de bases de dados, EDI, XBRL, ficheiros simples, Excel, JSON, JSON5, serviços web ou outros dados de bases de dados, através do MapForce.
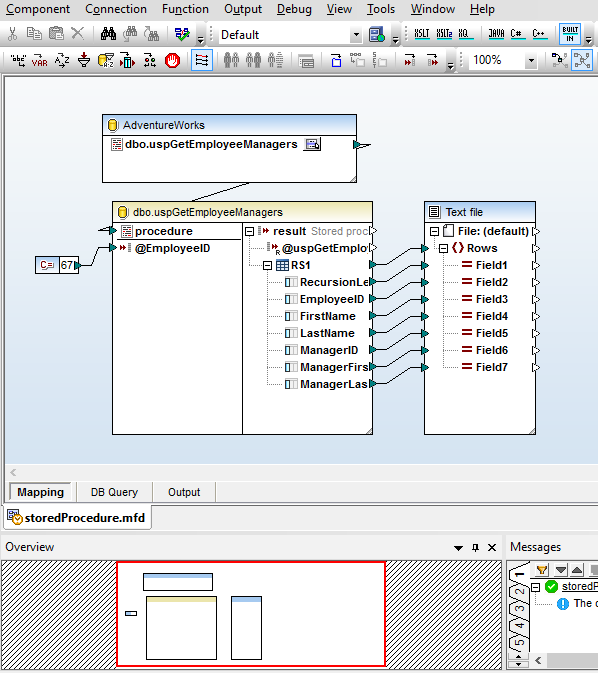
Suporte para procedimentos armazenados SQL
O MapForce oferece um suporte robusto para procedimentos armazenados, que podem ser utilizados como componentes de entrada (procedimentos que fornecem resultados) ou como componentes de saída (procedimentos que inserem ou atualizam dados). Alternativamente, os procedimentos armazenados podem ser integrados como chamadas de função, permitindo que os utilizadores forneçam dados de entrada, executem o procedimento armazenado e leiam/transformem os dados de saída para outros componentes.
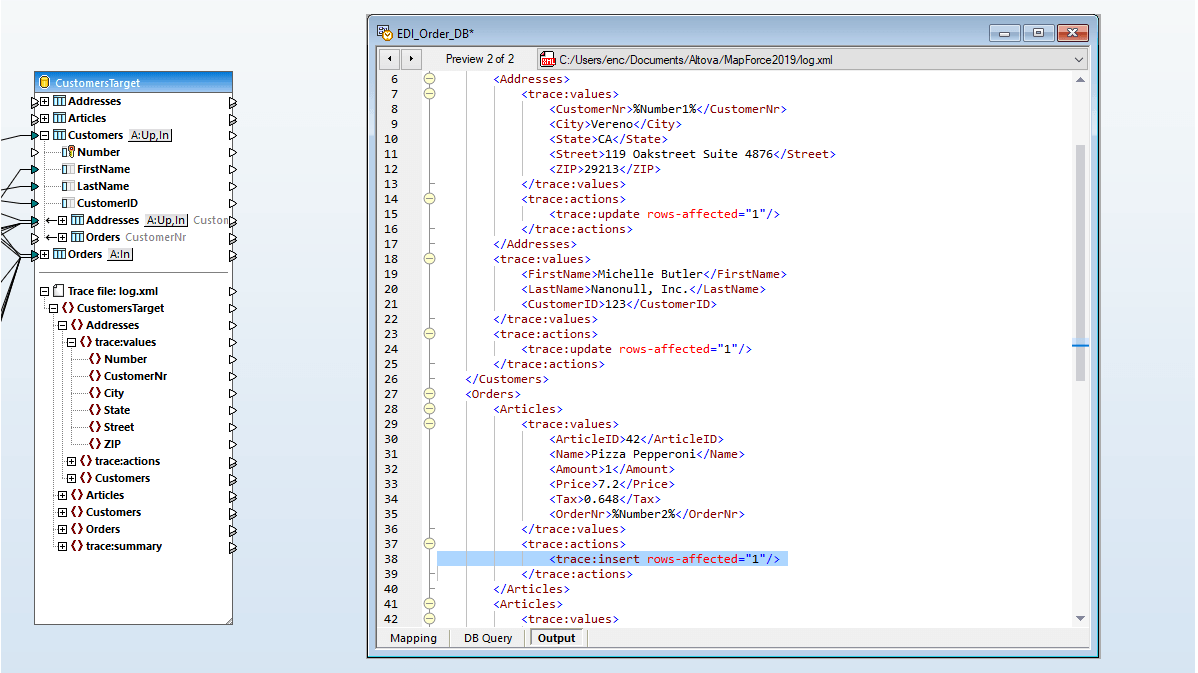
Esta captura de ecrã mostra a utilização de um procedimento armazenado no SQL Server para criar um ficheiro XML. O procedimento devolve uma tabela de dados que mostra todos os gestores na hierarquia acima do identificador do funcionário especificado, que é fornecido como um parâmetro de entrada – neste exemplo, o valor constante 67.
O parâmetro também pode ser fornecido como um valor calculado ou como um elemento de dados obtido de outra parte da base de dados.
O MapForce oferece um menu de contexto que permite aos utilizadores executar o procedimento armazenado para visualizar a estrutura de dados utilizada no mapeamento. A execução do mapeamento ilustrado gera a saída em formato XML.
Mapas XML armazenados em campos de base de dados
O MapForce também permite conectar-se e mapear dados XML armazenados em campos de bases de dados relacionais (atualmente suportado para SQL Server e IBM DB2). Basta atribuir um esquema XML – seja um esquema registado na base de dados ou um esquema do seu sistema de ficheiros local – ao campo, e o MapForce renderiza o esquema como uma subárvore do campo da base de dados, para fins de mapeamento.
Ordenar os componentes de entrada da base de dados
As consultas SQL que operam dentro da base de dados nem sempre são suficientes para tarefas complexas de mapeamento de dados. O MapForce oferece funcionalidades adicionais de ordenação de bases de dados através do componente SQL-WHERE/ORDER, permitindo processar dados de entrada de bases de dados que necessitam de processamento adicional, ou quando outros dados ou condições no mapeamento afetam a ordem de classificação das linhas de dados.
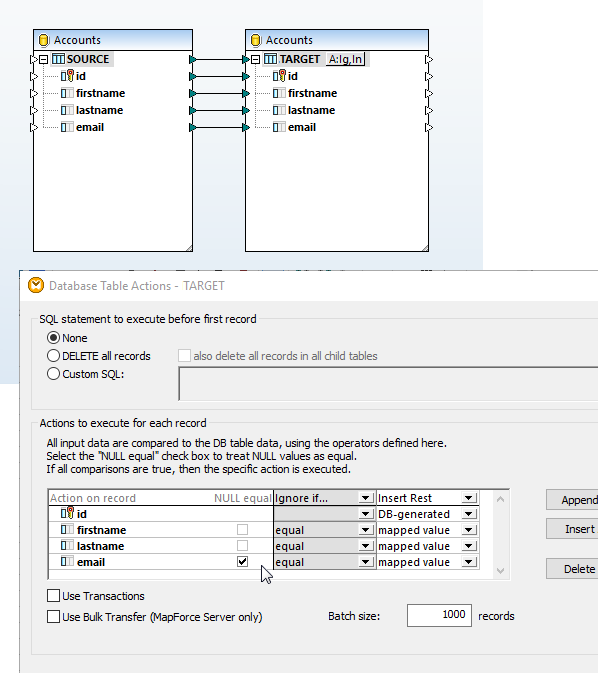
Suporte para valores nulos nas ações de tabelas de base de dados
A caixa de diálogo "Ações na Tabela de Base de Dados" suporta a comparação de valores NULL. As comparações que consideram os valores NULL oferecem uma forma mais eficiente de lidar com bases de dados que contêm valores nulos. Os utilizadores do MapForce podem configurar um mapeamento de base de dados de forma que a comparação de dados seja feita tendo em conta os valores NULL, de acordo com as regras aplicáveis ao tipo de base de dados envolvido no mapeamento.
O mapeamento de dados apresentado à direita tem como objetivo atualizar a tabela de destino sem inserir registos duplicados. Ambas as tabelas são definidas de forma a permitir que o campo de e-mail seja nulo, pelo que é possível que existam registos com o mesmo nome, mas com campos de e-mail nulos, em cada tabela.
Clicar no ícone "Ações" ao lado da tabela de base de dados "TARGET" abre a caixa de diálogo "Ações da Base de Dados". A caixa de seleção "Igual a NULL" ao lado do campo de e-mail permite que o MapForce trate os valores NULL na origem e no destino como iguais para fins de mapeamento de dados, mesmo que não sejam considerados iguais pelas regras da base de dados.
![Mapeamento de bases de dados com tratamento de valores nulos no MapForce]()