Mappatura avanzata di database e processi ETL
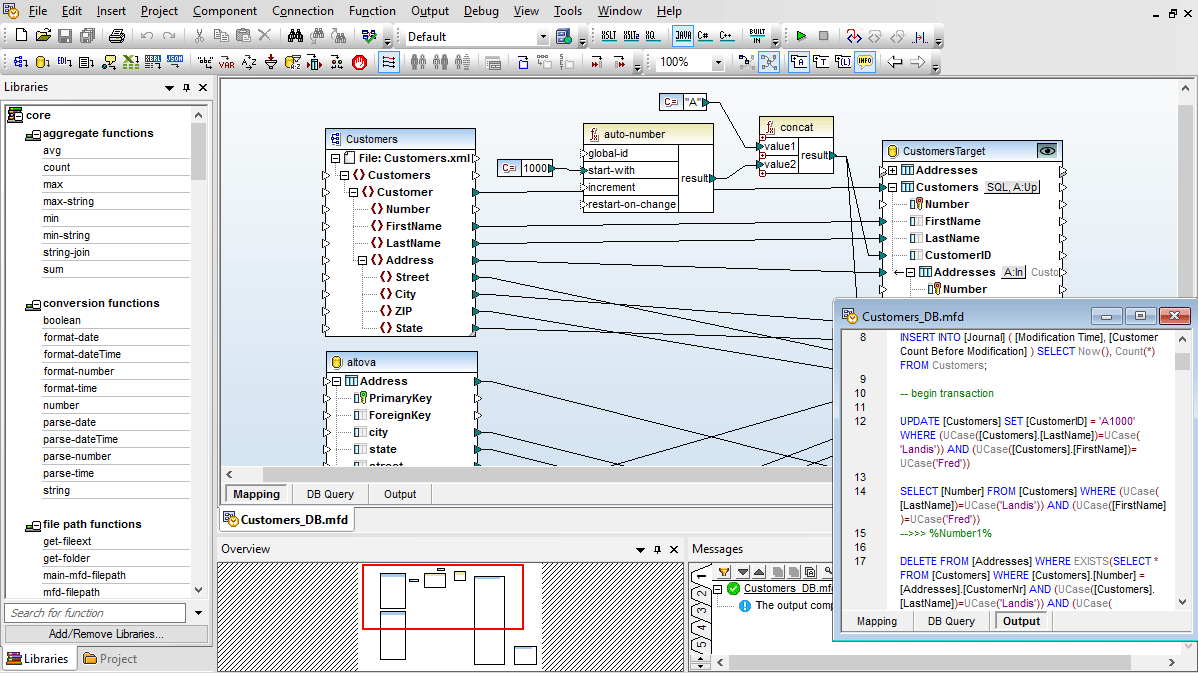
Per gli utenti che lavorano con SQL, MapForce include una scheda "Query del database" per eseguire query dirette al database. Quando ci si connette a un database tramite la scheda "Query del database", MapForce visualizza le tabelle del database in una struttura ad albero gerarchica nella finestra del browser.
Potete quindi utilizzare la scheda dell'editor SQL per visualizzare, modificare ed eseguire istruzioni SQL o SQL/XML, sia aprendo file SQL esistenti, sia creando nuove istruzioni SQL partendo da zero, utilizzando le funzionalità di trascinamento e rilascio e il completamento automatico.
È possibile eseguire il proprio script SQL e visualizzare i risultati in forma tabellare, nonché salvare sia i dati recuperati che lo script SQL separatamente, in file distinti.
Impostazioni delle chiavi del database
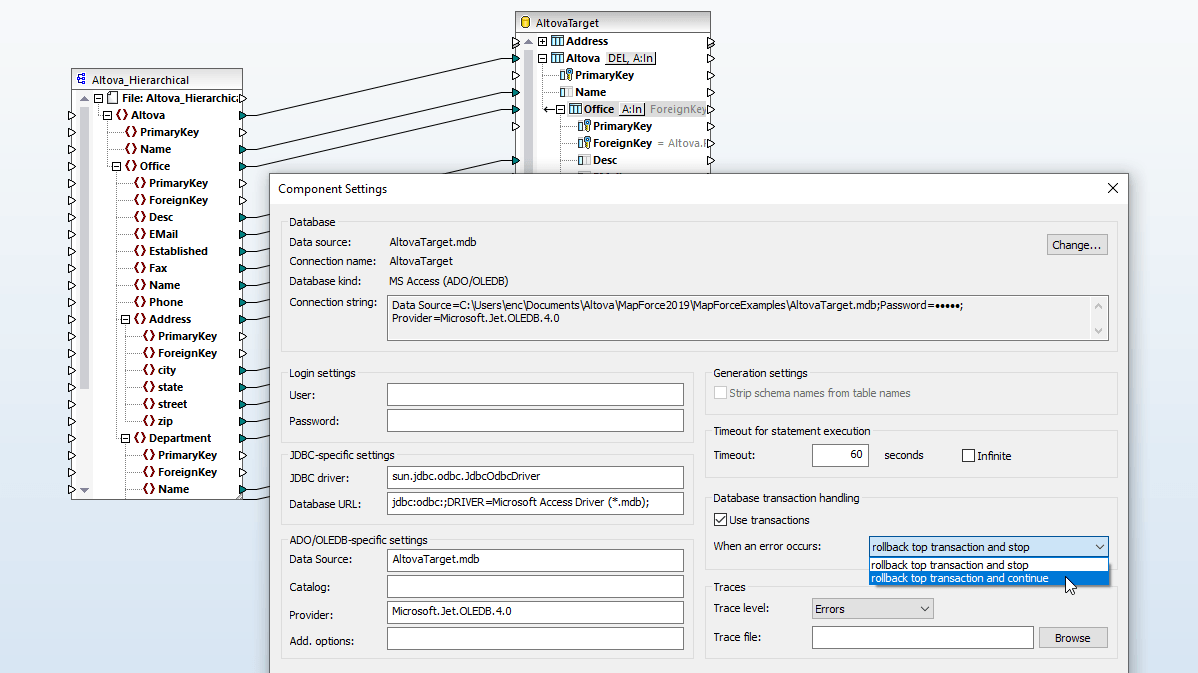
Le impostazioni delle chiavi del database in MapForce consentono di personalizzare il modo in cui i valori delle chiavi primarie e secondarie verranno aggiunti a un database che è l'obiettivo della mappatura dei dati. È possibile fornire i valori delle chiavi direttamente all'interno di MapForce, oppure è possibile lasciare che il sistema di database gestisca la generazione automatica di questi valori.
In situazioni in cui le relazioni di chiave primaria e/o chiave esterna non sono definite esplicitamente nelle tabelle del database, MapForce consente di definire queste relazioni direttamente, senza alterare i dati di origine.
Definire le azioni sulle tabelle del database
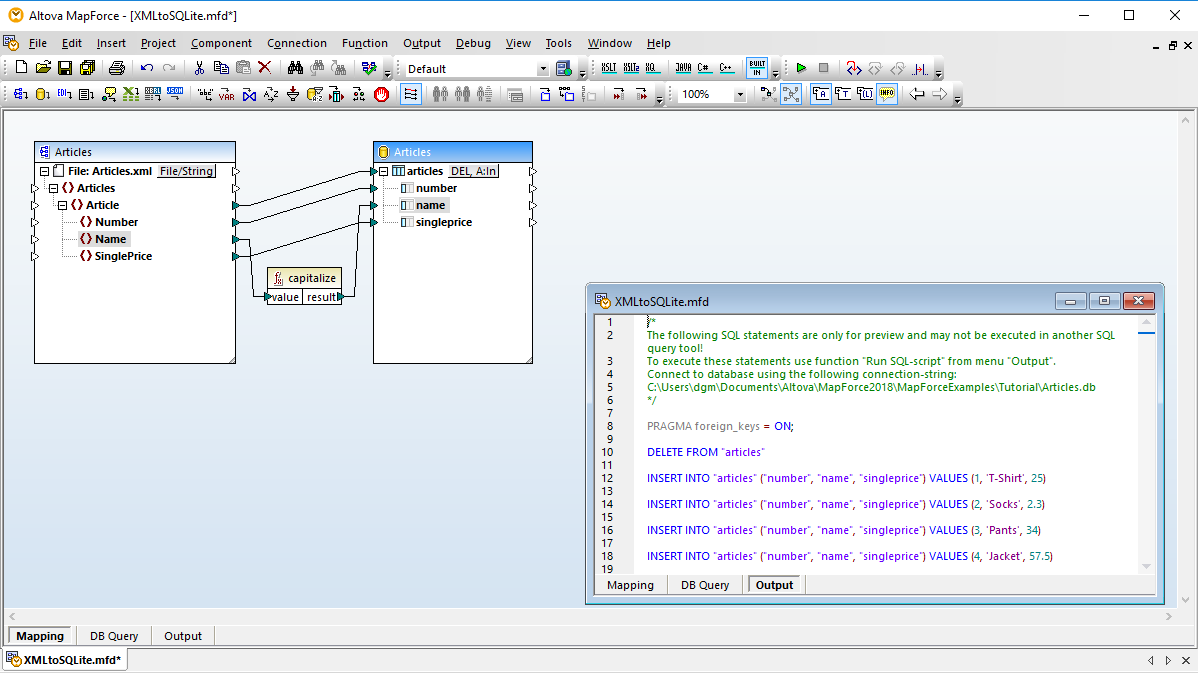
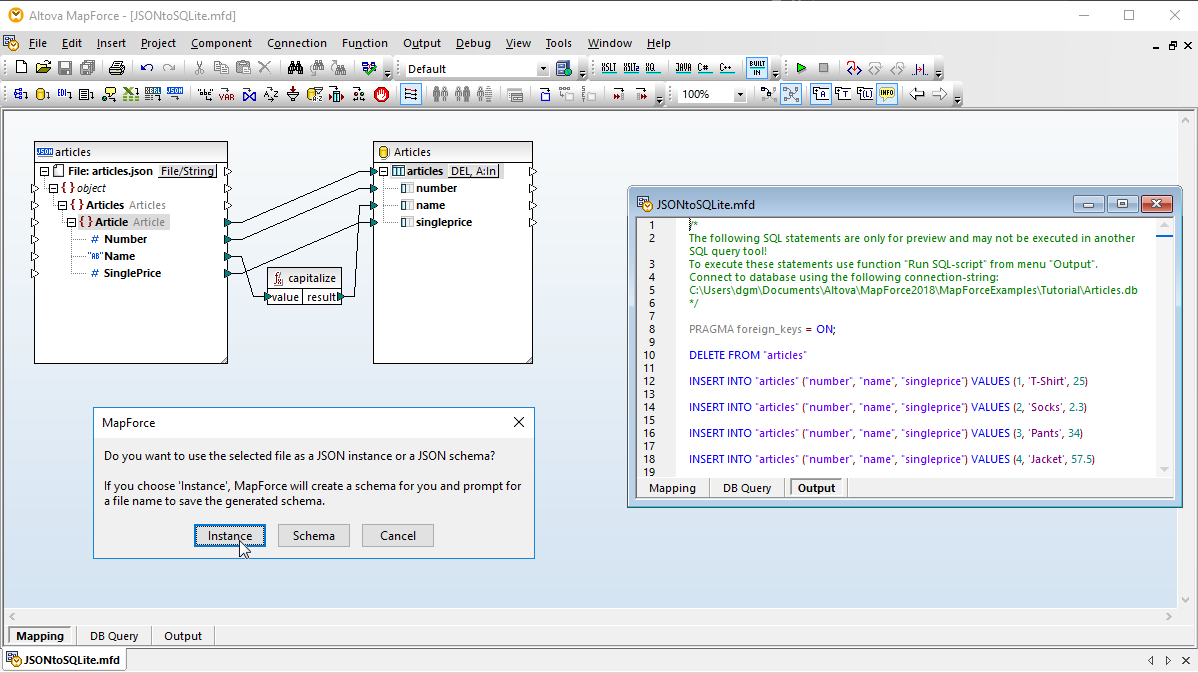
Quando si effettua una mappatura verso un database, MapForce consente di selezionare le azioni relative alle tabelle del database per controllare come i dati vengono scritti nel database. Questo offre la massima flessibilità per automatizzare anche le attività di gestione dei dati più complesse.
La finestra di dialogo "Azioni sulla tabella del database", facile da usare, consente di definire le colonne all'interno della tabella selezionata, che verranno utilizzate per determinare quale azione (INSERIMENTO, AGGIORNAMENTO, ELIMINAZIONE) deve essere eseguita nel database.
Questo offre una flessibilità senza precedenti nella manipolazione delle righe del database in risposta a dati XML, dati di database, EDI, XBRL, file di testo, Excel, JSON, JSON5, servizi web o altri dati di database, grazie a MapForce.
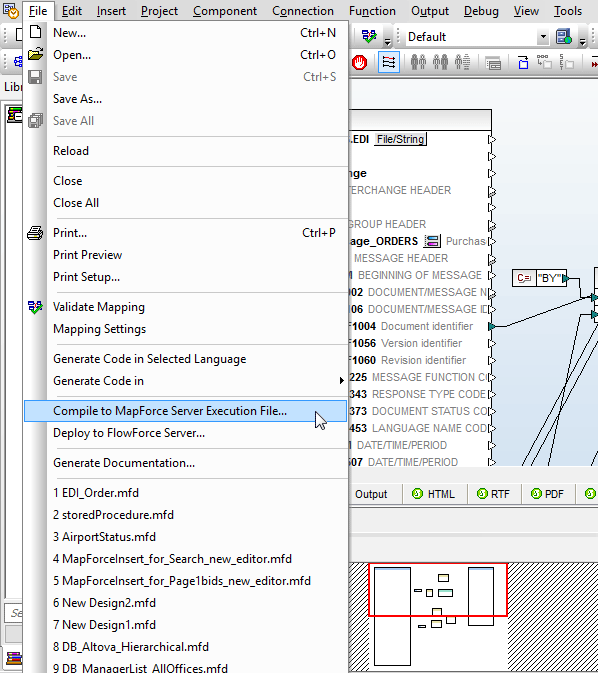
Supporto per le stored procedure SQL
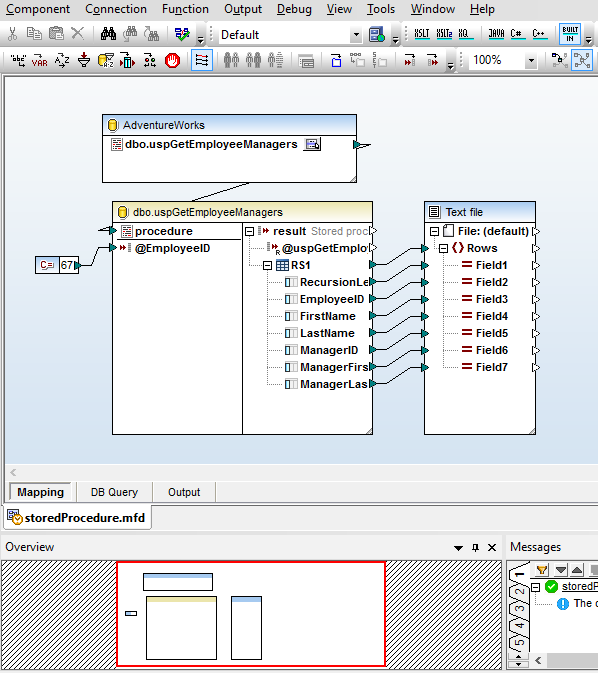
MapForce offre un supporto completo per le stored procedure, che possono essere utilizzate come componenti di input (procedure che forniscono risultati) o come componenti di output (procedure che inseriscono o aggiornano dati). In alternativa, le stored procedure possono essere utilizzate come chiamate di funzioni, consentendo agli utenti di fornire dati di input, eseguire la stored procedure e leggere/mappare i dati di output ad altri componenti.
Questa schermata mostra la mappatura di una stored procedure in SQL Server utilizzata per creare un file XML. La procedura restituisce una tabella di dati che mostra tutti i dirigenti nella gerarchia superiore all'ID del dipendente specificato, fornito come parametro di input: in questo esempio, il valore costante 67.
Il parametro può essere fornito anche come valore calcolato o come elemento dati recuperato da un'altra parte del database.
MapForce offre un menu contestuale che consente agli utenti di eseguire la stored procedure per visualizzare la struttura dei dati da mappare. L'esecuzione della mappatura illustrata genera l'output XML.
Mappe XML memorizzate nei campi del database
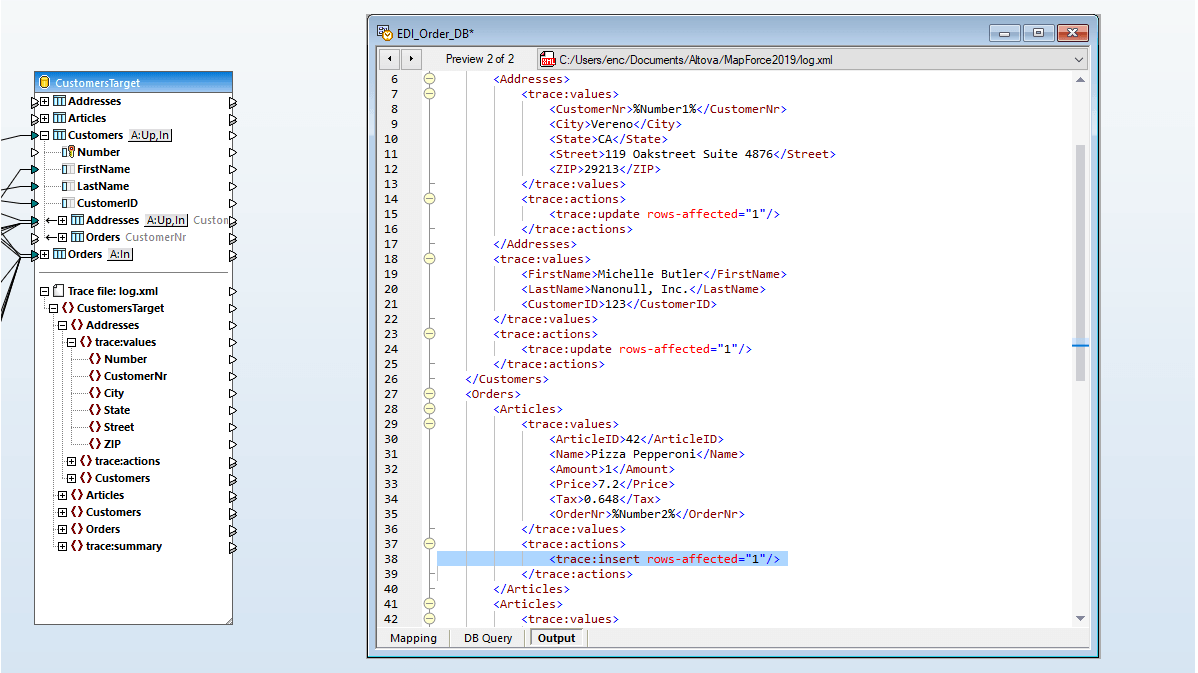
MapForce consente anche di connettersi e mappare dati XML memorizzati in campi di database relazionali (attualmente supportato per SQL Server e IBM DB2). È sufficiente assegnare uno schema XML – registrato nel database o proveniente dal sistema di file locale – al campo, e MapForce visualizza lo schema come un sottoalbero del campo del database, al fine di facilitare la mappatura.
Organizzare i componenti di input del database
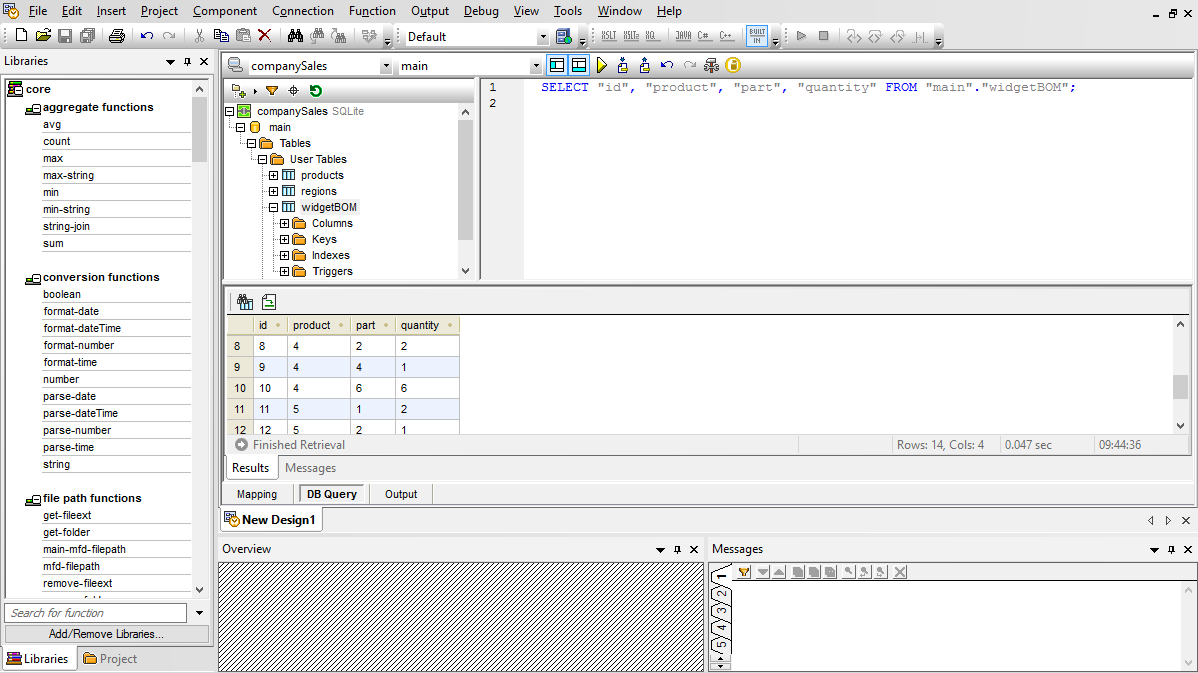
Le query SQL che operano all'interno del database non sono sempre sufficienti per attività di mappatura dati complesse. MapForce offre funzionalità aggiuntive di ordinamento dei dati tramite il componente SQL-WHERE/ORDER per l'input da database che richiedono un'elaborazione aggiuntiva, oppure quando altri dati o condizioni nella mappatura influenzano l'ordine di ordinamento delle righe di dati.
Supporto per i valori NULL nelle operazioni sulle tabelle del database
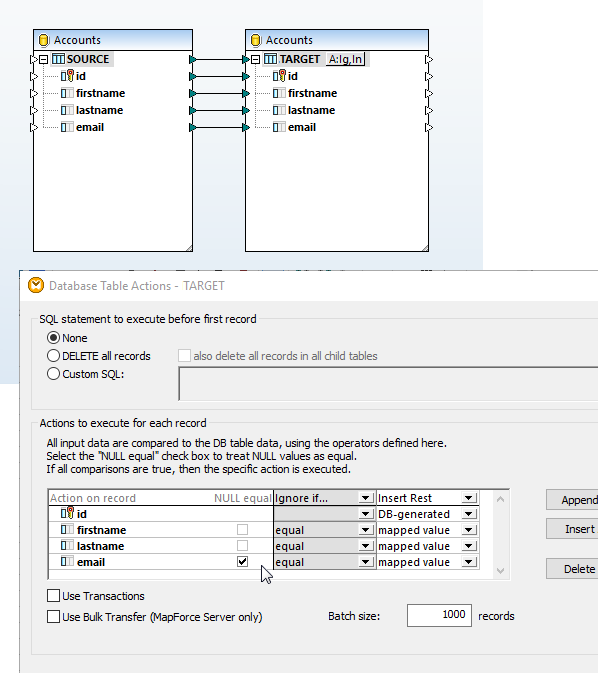
La finestra di dialogo "Azioni sulla tabella del database" supporta il confronto dei valori NULL. I confronti che tengono conto dei valori NULL offrono un modo più efficace per gestire database che contengono tali valori. Gli utenti di MapForce possono configurare una mappatura del database in modo che il confronto dei dati venga eseguito tenendo conto dei valori NULL, in base a regole applicabili al tipo di database coinvolto nella mappatura.
La mappatura dei dati mostrata a destra è progettata per aggiornare la tabella di destinazione senza inserire voci duplicate. Entrambe le tabelle sono definite in modo da consentire che il campo "email" possa essere vuoto (NULL), quindi potrebbero esistere voci con lo stesso nome ma con campi "email" vuoti in ciascuna tabella.
Cliccando sull'icona "Azioni" accanto alla tabella del database "TARGET", si apre la finestra di dialogo "Azioni del database". La casella di controllo "Uguale a NULL" accanto al campo email consente a MapForce di considerare i valori NULL presenti nei dati di origine e di destinazione come equivalenti ai fini della mappatura dei dati, anche se, secondo le regole del database, non sono considerati uguali.
![Mappatura di database che tiene conto dei valori null in MapForce]()