Uma aplicação comum do MapForce é a migração de dados entre bases de dados MySQL e PostgreSQL. O MapForce facilita este processo com ferramentas gráficas de mapeamento de dados, que funcionam por arrastar e soltar, e que incluem uma vasta biblioteca de filtros e funções de processamento de dados para transformar os dados de origem.
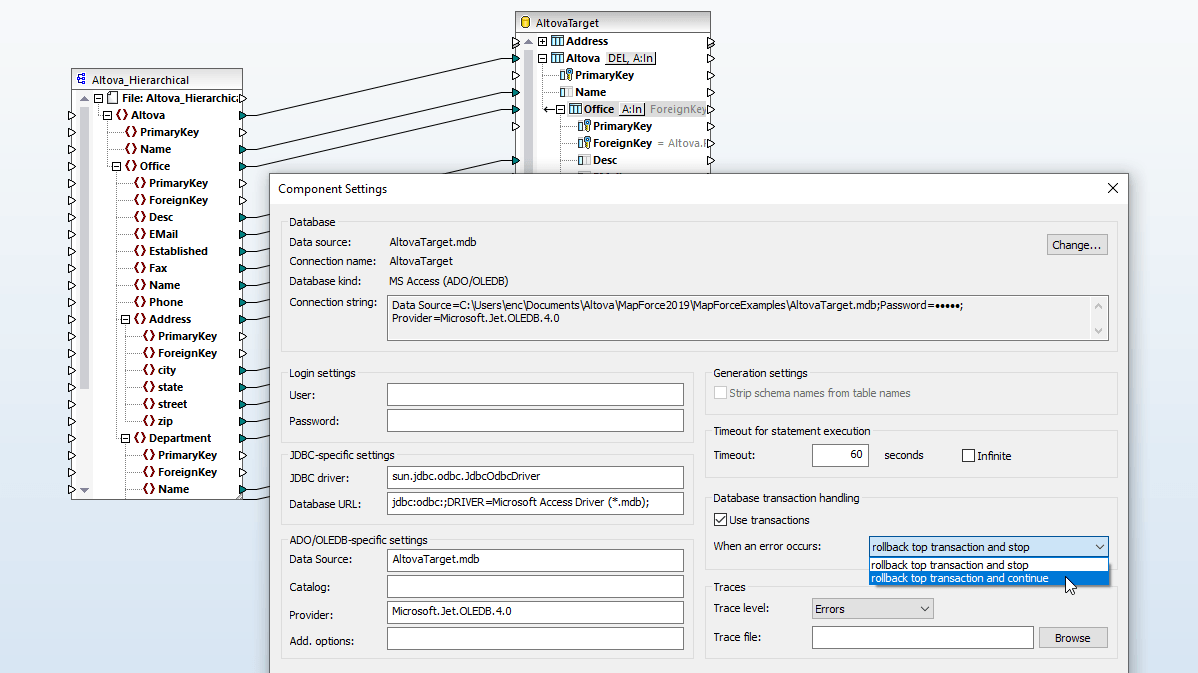
O Assistente de Conexão de Base de Dados no MapForce facilita a conexão. As conexões com o SQLite são suportadas como conexões nativas, diretamente ao ficheiro de base de dados SQLite. Não são necessários drivers adicionais. As conexões com o PostgreSQL são suportadas tanto como conexões nativas como através de drivers, utilizando interfaces como ODBC ou JDBC. As conexões nativas não requerem nenhum driver.
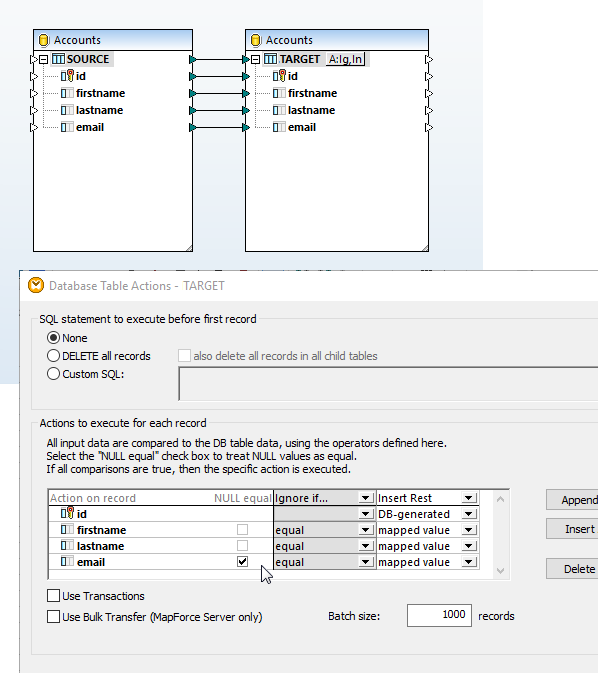
Quando carrega as estruturas de bases de dados MySQL e PostgreSQL no painel de mapeamento, o MapForce interpreta automaticamente os esquemas das bases de dados, permite-lhe selecionar as tabelas e vistas disponíveis e reconhece as relações entre as tabelas.
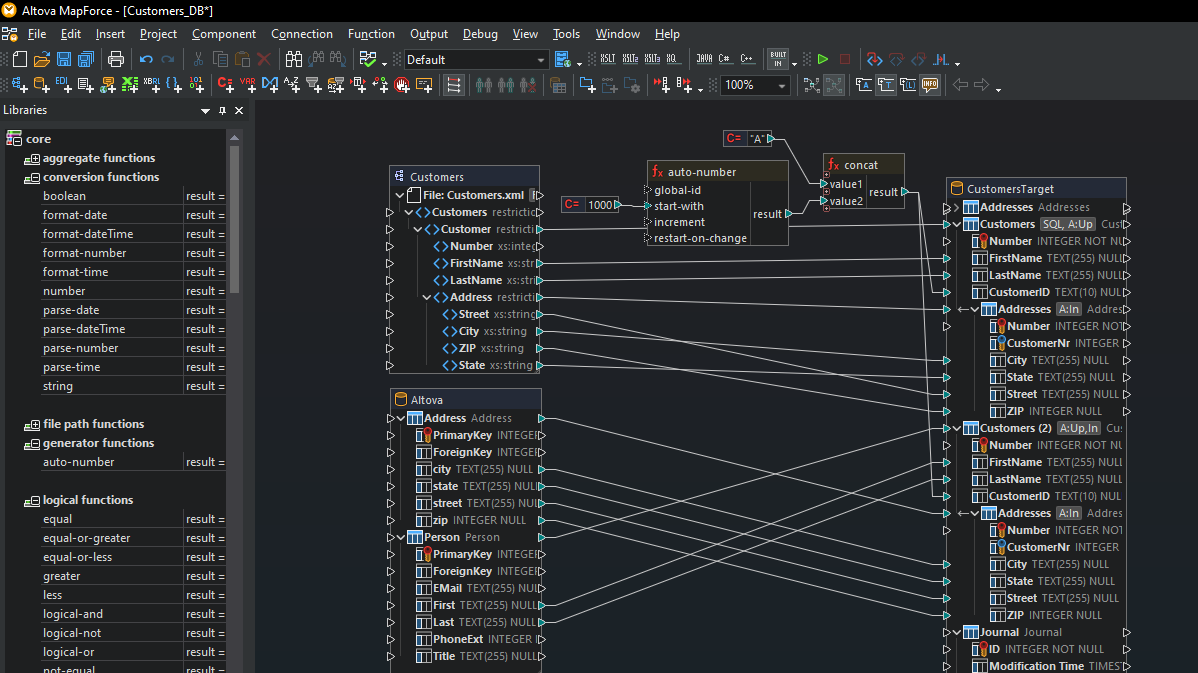
Depois de ter carregado todos os modelos de conteúdo necessários para o mapeamento da sua base de dados, complete o mapeamento simplesmente arrastando linhas de ligação entre as estruturas de origem e de destino.
Utilizando a abordagem sem código do MapForce, é fácil satisfazer requisitos comuns de transformação de dados, por exemplo:
- Converter PostgreSQL para MySQL
- Migrar do PostgreSQL para o MySQL
- Exportar dados do PostgreSQL para o MySQL
- Converter MySQL para PostgreSQL
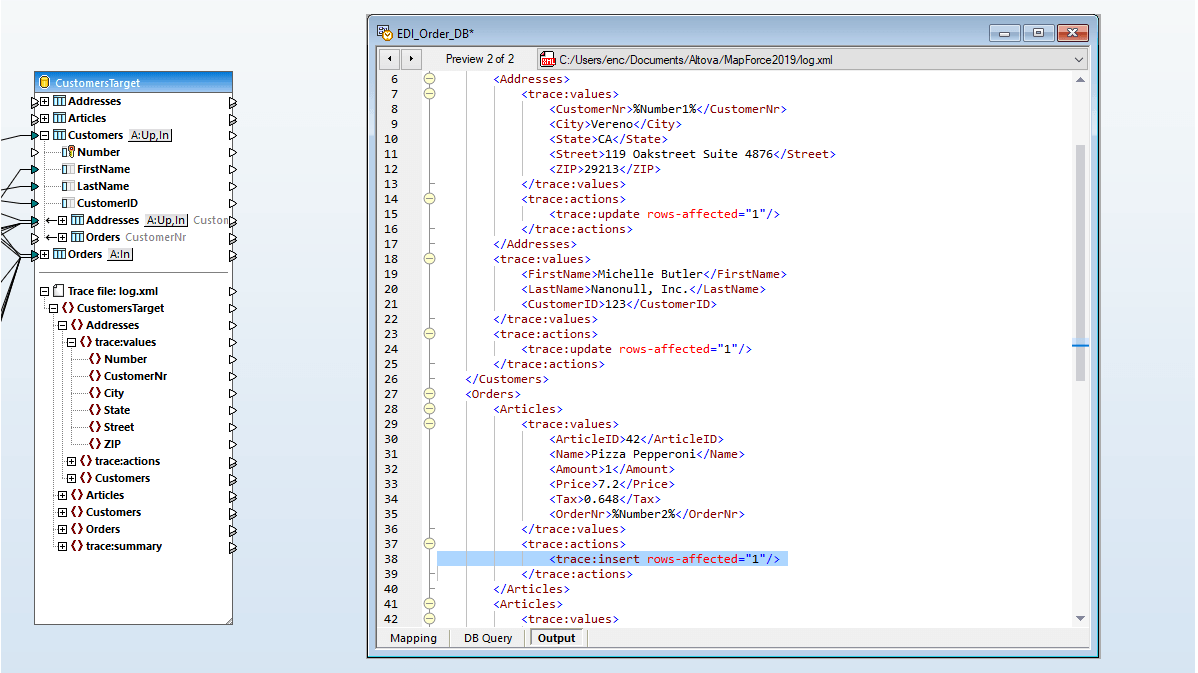
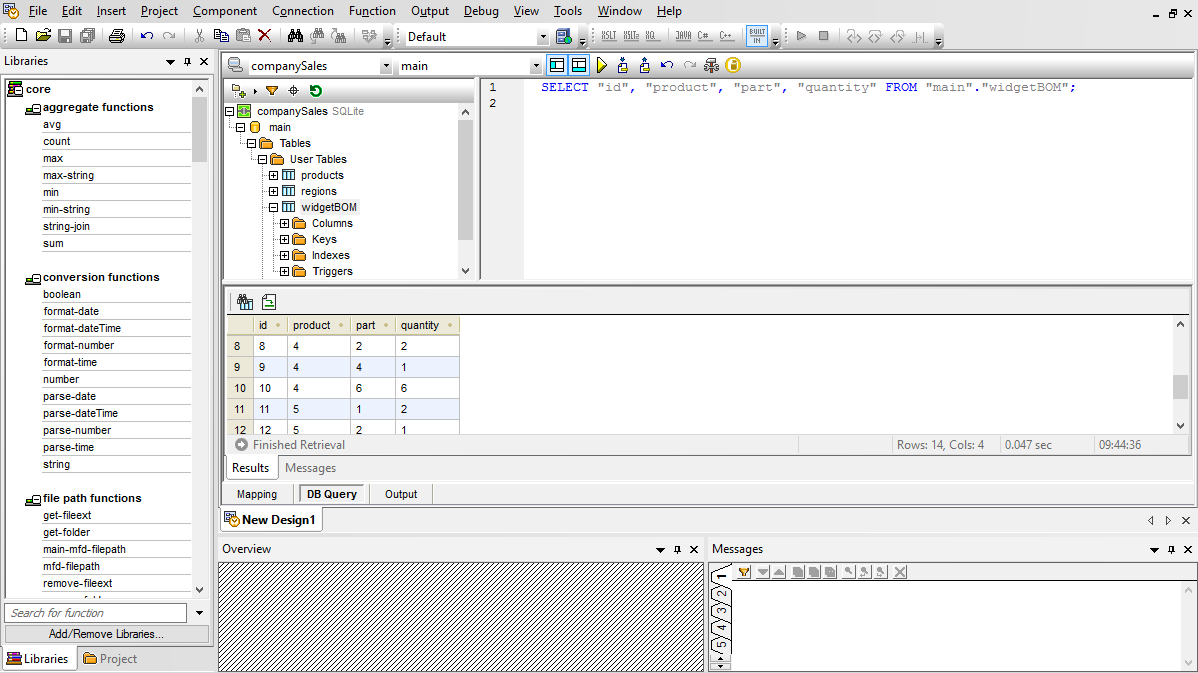
Muitas mapeações de bases de dados exigem a transformação de dados entre a fonte e o destino, com base em condições booleanas ou em instruções SQL e SQL/XML. Pode ser necessário realizar comparações lógicas, cálculos matemáticos ou operações com strings, verificar se os dados da base de dados correspondem a um determinado valor e efetuar outras modificações nos dados. Na captura de ecrã acima, as funções de processamento de dados aparecem como os retângulos entre as linhas que ligam o modelo de dados de origem e o modelo de dados de destino.
As funções de processamento de dados permitem realizar mapeamentos avançados de bases de dados em tempo real, para uma vasta gama de necessidades de transformação.
Depois de definir o mapeamento, o motor MapForce integrado permite visualizar e guardar os resultados com apenas um clique.
A correspondência entre o MySQL e o PostgreSQL irá gerar resultados na forma de scripts SQL (por exemplo, instruções SELECT, INSERT, UPDATE e DELETE) que serão executados diretamente na sua base de dados de destino, a partir do próprio MapForce.
Após visualizar o resultado, terá a opção de automatizar o processo de transformação de dados através do MapForce Server.