MapForce Offers Dynamic Access to Node Names
There are situations, especially when encountering loosely structured data, where you may want to map and transform structural components of a data stream along with content. MapForce can dynamically access node names of XML elements, attributes, or text file columns such as the contents of CSV files, to target components.
Dynamic access to node names allows creation on the fly of target elements and attributes whose names do not need to be known beforehand or specifically identified in the data mapping. This feature lets you create much more generic, flexible, and reusable mappings that require less manual intervention if data models evolve.

Here is an example of a very common style of CSV file where data fields are not identified by column names, but by labels in a neighboring cell within the row:
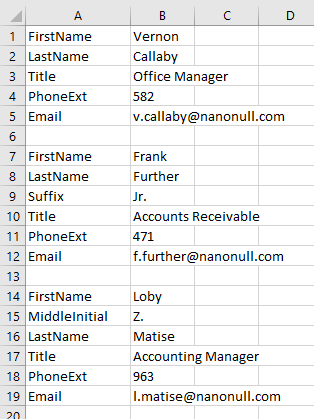
The records in this example are not even structured consistently, since one record includes a suffix after the last name and another record includes a middle initial.
A likely data mapping requirement for files like this is to map the cells in column A as XML element names and the cells in column B as values for each corresponding element. This is now easily accomplished with dynamic mapping of node names. Let’s look at how it’s done.
Dynamic Access to Node Names of XML Elements
We’ll start by creating a very simple XML Schema for the mapping target that uses the <xs:any> element to define a complex

We start the mapping by dropping in the CSV file and using a group function that will create a new
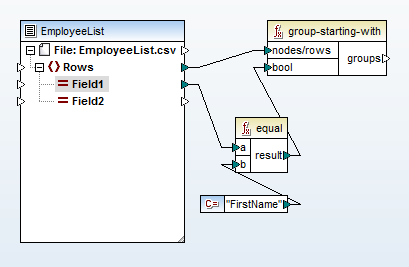
Next we drop in the target XML Schema, and right-click the
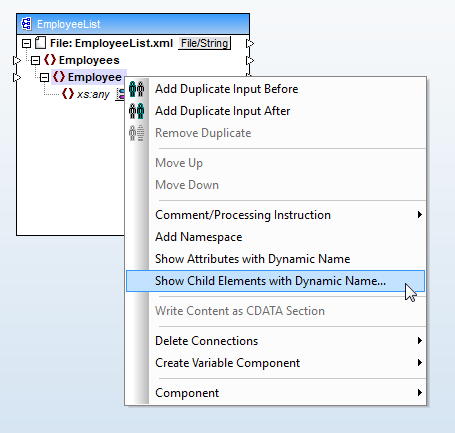
We will choose the option Show Child Elements with Dynamic Name, which opens a dialog where we will select text as the data type for child elements. This exposes the node name and content for child elements of
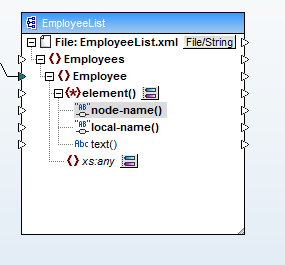
Now it’s a simple process to map from Field1 (column A of the CSV file) to the child element node names and from Field2 (column B) to the element content. Here is the final data mapping:
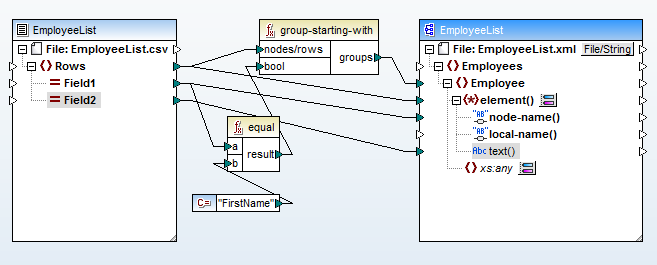
The function group-starting-with at the top creates a new
Output for the mapping above looks like this:
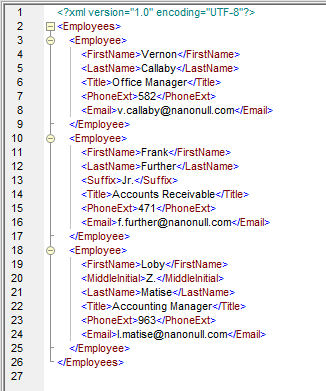
The advantage of a data mapping that uses dynamic access to the names of nodes is you do not have to do a comprehensive survey of the input data to identify and map every possible element name.
Consider a common production scenario where you accept multiple input files from one or more external sources and automate mapping execution with MapForce Server and FlowForce Server. If an input file arrives that suddenly contains an unexpected child element – OfficeLocation or MailStop, for instance – the data will not be lost.
Dynamic Access to Node Names of XML Attributes
You can also dynamically map the names of XML attributes, with the same ability to create target elements and attributes on the fly without necessarily identifying them all ahead of time.