HTTP REST Server API
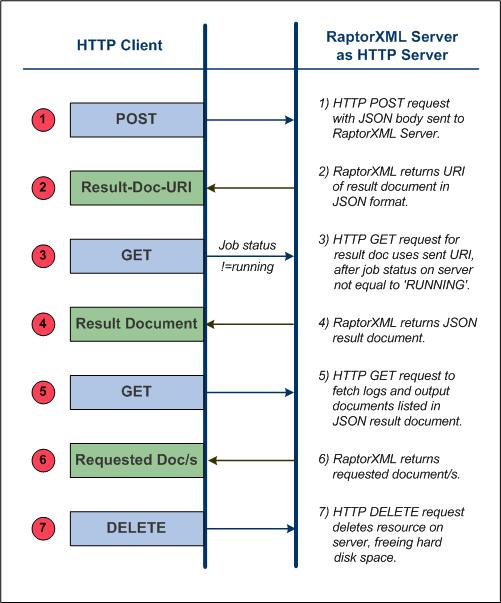
RaptorXML+XBRL Server accepts jobs submitted via HTTP (or HTTPS). The job description as well as the results are exchanged in JSON format. The basic workflow is as shown in the diagram below.
Security concerns related to the HTTP REST APIThe HTTP REST API, by default, allows result documents to be written to any location specified by the client (that is accessible with the HTTP protocol). It is important therefore to consider this security aspect when configuring RaptorXML+XBRL Server.
If there is a concern that security might be compromised or that the interface might be misused, the server can be configured to write result documents to a dedicated output directory on the server itself. This is specified by setting the server.unrestricted-filesystem-access option of the server configuration file to false. When access is restricted in this way, the client can download result documents from the dedicated output directory with GET requests. Alternatively, an administrator can copy/upload result document files from the server to the target location. |
In this section
Before sending a client request, RaptorXML+XBRL Server must be started and properly configured. How to do this is described in the section Server Setup. How to send client requests is described in the section Client Requests. The OpenAPI Description File topic describes the OpenAPI Definition file delivered with RaptorXML+XBRL Server that enables you to interact with the HTTP API. Finally, the section C# Example for REST API provides a description of the REST API example file that is installed with your RaptorXML+XBRL Server package.