Regrouper des données
Lorsque votre mappage doit regrouper des nœuds ou des lignes, vous pouvez compter sur les fonctions intégrées de MapForce suivantes :
•group-by
•group-adjacent
•group-into-blocks
•group-starting-with
•group-ending-with
Pour utiliser une de ces fonctions sur le mappage, glissez-les depuis la fenêtre de bibliothèque dans la zone de mappage. Voir aussi Ajouter une fonction au mappage.
| Note : | Les fonctions de regroupement sont disponibles dans les langages suivants : XSLT 2.0, XSLT 3.0, C++, C#, Java, Built-In. |
Les sections suivantes fournissent des exemples typiques d'utilisation pour des fonctions de regroupement. Ces exemples sont accompagnés par le mappage de démo suivant : <Documents>\Altova\MapForce2023\MapForceExamples\Tutorial\GroupingFunctions.mfd. Veuillez noter que le mappage de donnée contient plusieurs transformations, une pour chaque fonction. Puisque seule une sortie peut être consultée à la fois, n'oubliez pas de cliquer sur la touche Aperçu ![]() applicable pour la transformation désirée avant de cliquer sur l'onglet Sortie.
applicable pour la transformation désirée avant de cliquer sur l'onglet Sortie.
group-by
La fonction group-by crée des groupes d'enregistrements conformément à certaines clés de regroupement que vous aurez spécifiées.

Par exemple, dans la transformation abstraite illustrée ci-dessous, la clé de regroupement est "Department". Étant donné qu'il y a trois départements au total, l'application de la fonction group-by créera trois groupes :
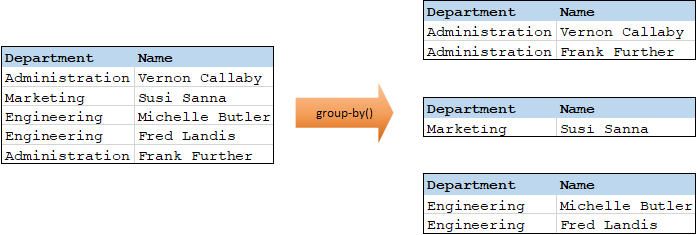
Pour plus d'informations, voir la référence à la fonction group-by.
group-adjacent
La fonction group-adjacent exige une clé de regroupement en tant qu'argument, comme pour la fonction group-by. Contrairement à group-by, cette fonction crée un nouveau groupe à chaque fois que la clé suivante est différente. Si deux enregistrements adjacents ont la même clé, ils seront placés dans le même groupe.
Par exemple, dans la transformation abstraite illustrée ci-dessous, la clé de regroupement est "Department". Le côté gauche du diagramme montre les données d'entrée tandis que le côté droit montre les données de sortie après le regroupement. Les événements suivants se produisent lorsque la transformation est exécutée :
•Tout d'abord, la première clé, "Administration", crée un nouveau groupe.
•La clé suivante est différente, donc un deuxième groupe est créé :"Marketing".
•La troisième clé est aussi différente, donc un groupe supplémentaire est créé : "Engineering".
•La quatrième clé est la même que la troisième, c'est pourquoi cet enregistrement est placé dans le groupe déjà existant.
•Enfin, la cinquième clé est différente de la quatrième et cela crée le dernier groupe.
Comme illustré ci-dessous, "Michelle Butler" et "Fred Landis" ont été regroupés car ils partagent la même clé et sont adjacents. Néanmoins, "Vernon Callaby" et "Frank Further" se trouvent dans des groupes séparés étant donné qu'ils ne sont pas adjacents, même s'ils possèdent la même clé.
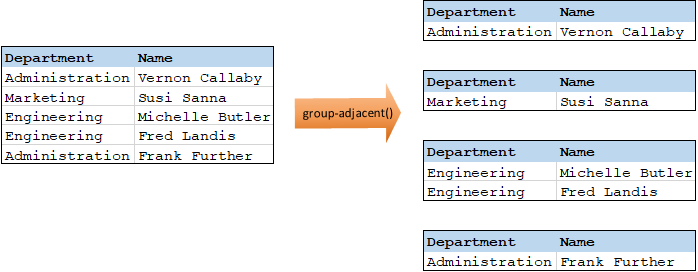
Pour plus d'informations, voir la référence à la fonction group-adjacent.
group-into-blocks
La fonction group-into-blocks crée des groupes égaux qui contiennent exactement N items, et où N est la valeur que vous fournissez à l'argument block-size. Veuillez noter que le dernier groupe peut contenir N items ou moins, selon le nombre d'items se trouvant dans la source.

Dans l'exemple ci-dessous, block-size est 2. Étant donné qu'il existe au total cinq items, chaque groupe contient exactement deux items, sauf pour le dernier.
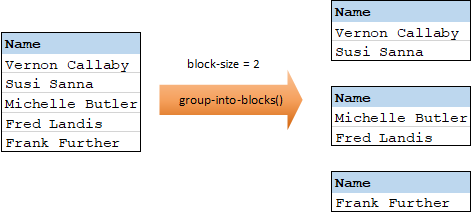
Pour plus d'informations, voir la référence à la fonction group-into-blocks.
group-starting-with
La fonction group-starting-with prend une condition booléenne en tant qu'argument. Si celle-ci est vraie, un nouveau groupe est créé, commençant avec l'enregistrement qui satisfait à la condition.

Dans l'exemple ci-dessous, la condition est que "Key" doit être égal à "heading". Cette condition est vraie pour le premier et le quatrième enregistrement, donc deux groupes sont créés :
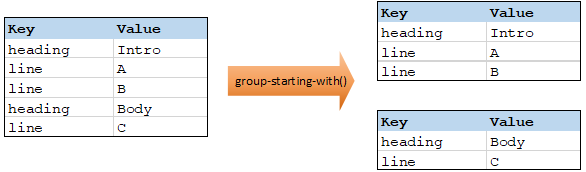
| Note: | Un groupe supplémentaire est créé si des enregistrements existent après le premier qui satisfait à la condition. Par exemple, s'il existait plus d'enregistrements "line" avant le premier enregistrement "heading", ceux-ci seraient tous placés dans un nouveau groupe. |
Pour plus d'informations, voir la référence à la fonction group-starting-with.
group-ending-with
La fonction group-ending-with prend une condition booléenne en tant qu'argument. Si la condition booléenne est vraie, un nouveau groupe est créé, terminant avec l'enregistrement qui satisfait la condition.

Dans l'exemple ci-dessous, la condition est que "Key" doit être égal à "trailing". Cette condition est vraie pour les troisième et quatrièmes enregistrements, en résultat, deux groupes sont créés :
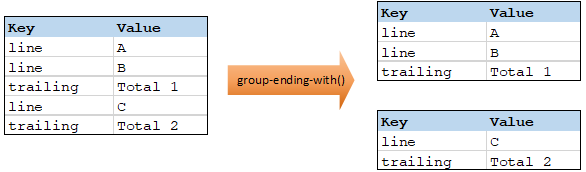
| Note : | Un groupe supplémentaire est créé si des enregistrements existent après le dernier qui satisfait à la condition. Par exemple, si il existait plus d'enregistrements "line" après le dernier enregistrement "trailing", ceux-ci seraient tous placés dans un nouveau groupe. |
Pour plus d'informations, voir la référence à la fonction group-ending-with.