Funcionamiento
Este tema ofrece una descripción general de la interfaz y las funciones de PDF Extractor.
Cómo ejecutar PDF Extractor
Para iniciar PDF Extractor, puede elegir una de las siguientes opciones:
•Puede ejecutar PDF Extractor directamente desde MapForce. Esta opción es útil cuando desea crear una nueva plantilla de extracción de PDF directamente desde MapForce.
•También puede iniciar PDF Extractor como programa independiente, ejecutando Altova MapForce PDF Extractor desde el menú Inicio o desde el directorio de instalación de MapForce.
Para más información sobre cómo crear una plantilla de extracción de PDF, consulte Crear una plantilla nueva.
Resumen de la interfaz gráfica del usuario
La imagen que aparece más abajo muestra la interfaz de PDF Extractor. La interfaz está organizada en cinco partes diferenciadas:
•la parte superior, que contiene los diferentes comandos de menú y de la barra de herramientas,
•el panel Esquema (parte superior izquierda), que le permite definir la estructura de su documento PDF y las reglas de extracción,
•el panel Vista PDF (parte superior derecha), en el que puede ver su archivo PDF y utilizar indicaciones visuales para definir las reglas de extracción,
•el panel Propiedades (parte inferior izquierda), que le permite definir diversas propiedades y calcular expresiones,
•el panel Resultados (parte inferior derecha), que muestra el aspecto que tendrán la estructura y los datos de su documento PDF, en función de las propiedades y el diseño que haya definido.
Paneles Esquema y Propiedades
La estructura de una plantilla en el panel Esquema consta de varios objetos plantilla, que son los bloques de construcción fundamentales de cualquier plantilla. Las propiedades de los objetos plantilla se definen en el panel Propiedades.
Panel Resultados
En el panel Resultados la estructura se representa como una jerarquía XML.
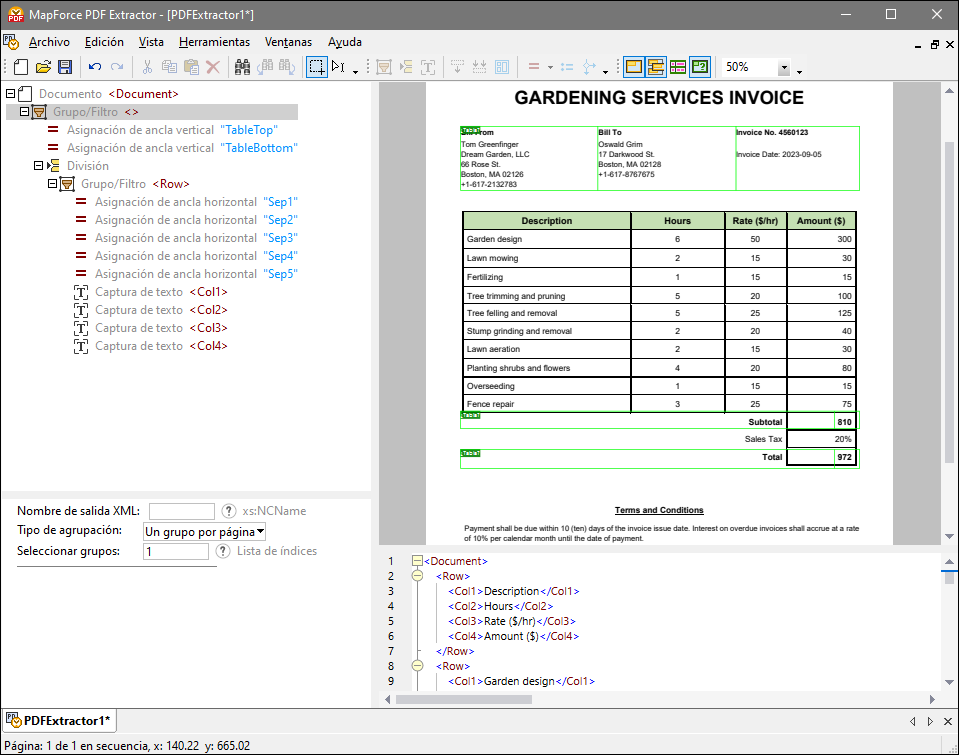
Varias plantillas
PDF Extractor le permite trabajar con varias plantillas a la vez. Cada plantilla tiene su propia ventana. En la imagen anterior, solo hay una plantilla llamada PDFExtractor1. Todas las plantillas de extracción de PDF creadas en PDF Extractor se guardan con la extensión .pxt.
Documentos escaneados y creados electrónicamente
Puede extraer texto de documentos PDF creados electrónicamente y escaneados. Para más información, haga clic en estos enlaces:
•Tutorial: le ayudará a empezar a usar PDF Extractor.
•Objetos de la plantilla: proporciona una descripción general de los objetos disponibles en una plantilla PDF.
•Documentos escaneados: proporciona una descripción general de la función de reconocimiento óptico de caracteres (OCR).
•Flujo de trabajo OCR: describe las principales fases de la extracción de texto de documentos PDF escaneados.
•Tutorial sobre OCR: Ofrece un ejemplo paso a paso de cómo aplicar el OCR a un archivo PDF escaneado.
Función de búsqueda
PDF Extractor dispone de una potente función de búsqueda de texto. Puede realizar búsquedas tanto en la interfaz gráfica del usuario como en tiempo de ejecución. Para más información, consulte Función de búsqueda y Buscar texto. Además, puede agrupar los datos PDF por texto encontrado o no encontrado en una página. Consulte Agrupar/Filtrar para obtener más información.