Pasos Aplazar
Un trabajo de FlowForce normal devuelve un resultado después de que hayan finalizado todos los pasos de procesamiento, siempre y cuando no se encuentre ningún error. Para los trabajos expuestos como servicios web, esto significa que la transacción HTTP debe mantenerse abierta durante todo el tiempo en que se esté ejecutando el trabajo, lo que puede llevar varios minutos o, en algunos casos, incluso horas, en función del volumen de datos que se procese. Para gestionar estos casos de forma más eficiente, puede crear pasos aplazados.
Los pasos aplazados solo se llevan a cabo después de que se hayan procesado todos los pasos no aplazados y el trabajo haya devuelto un resultado. Aunque un trabajo con pasos aplazados pueda devolver un resultado antes de tiempo, se considera que el trabajo está en curso hasta que haya finalizado la ejecución de todos los pasos aplazados.
Agregar un paso Aplazar
Puede crear pasos aplazados en cualquier parte del trabajo que admita un paso. Para agregar un paso aplazado siga estos pasos:
1.Cree un nuevo trabajo o abra uno ya existente.
2.Haga clic en el botón nuevo paso Aplazar en la sección Pasos de ejecución.
3.Haga clic en  dentro del bloque Aplazar para agregar el paso o los pasos que quiera aplazar.
dentro del bloque Aplazar para agregar el paso o los pasos que quiera aplazar.
En función de sus necesidades, puede crear pasos de ejecución, pasos Opción, pasos For-Each y controladores de errores dentro de un bloque Aplazar. También puede anidar otros bloques Aplazar dentro de su bloque Aplazar.
Control de errores
Un trabajo puede contener varios bloques Aplazar (donde cada uno de ellos contiene un paso o varios que se aplazan) en distintos lugares del trabajo. Crear pasos aplazados puede ser útil para el control de errores: Si ocurre un error dentro de un bloque aplazado los demás pasos no se verán afectados. Un bloque aplazado es como un minitrabajo y se comporta igual que los trabajos normales:
•Si un paso de un bloque aplazado encuentra un error, ese paso se cancela, así como los pasos posteriores en el mismo bloque aplazado, y el error se guarda en el registro.
•Los bloques aplazados no se afectan unos a otros. En un trabajo que tiene varios bloques aplazados, un bloque aplazado se ejecuta incluso aunque la ejecución del anterior falle.
•Si un paso aplazado con un bloque protegido encuentra un error, se cancelan todos los pasos aplazados que forman parte de ese bloque.
Casos posibles
A continuación presentamos algunos casos en los que se podrían usar pasos aplazados.
Trabajo con varios pasos aplazados
El siguiente ejemplo de trabajo se ejecutará en el siguiente orden: A, C, B, D. Primero se ejecutan los pasos no aplazados, seguidos de los pasos aplazados. El paso C devuelve un resultado.
A
postpone B
C
postpone D
Pasos Aplazar en pasos Opción
También puede añadir pasos aplazados dentro pasos Opción. En este caso el paso aplazado solo se ejecuta si también se ejecuta la correspondiente rama Cuando o De lo contrario.
when expression=true
{
postpone A
B
C
}
otherwise
{
postpone D
E
F
}
En este trabajo, si la expresión es true, los pasos se ejecutarán en el siguiente orden: B, C*, A. De lo contrario, el orden de ejecución será: E, F*, D. Los asteriscos indican los pasos que devuelven resultados.
Pasos Aplazar en pasos For-Each
El trabajo de ejemplo que se muestra a continuación muestra un paso For-Each, en el que los pasos aplazados se procesarán después de los pasos no aplazados, en el mismo orden que en el bucle del que forman parte.
for each item in list
{
A
postpone B
}
Por ejemplo, si el bucle se ejecuta tres veces, los pasos anteriores se ejecutan en este orden: A1, A2, A3*, B1, B2, B3. Los dígitos indican la vuelta correspondiente en el bucle. El asterisco indica un paso que devuelve un resultado.
Pasos aplazados anidados en pasos aplazados
También puede anidar pasos aplazados en otros pasos aplazados (véase el extracto de código más abajo). En este caso, primero se ejecutan los pasos exteriores de la misma profundidad y los pasos aplazados anidados se ejecutan solo después de que haya finalizado el procesamiento de la secuencia principal. En nuestro ejemplo, los pasos se ejecutarán en el siguiente orden: A, G, N, B, D, F, C, E, H, K, M, J, L. El paso N devuelve un resultado.
A
postpone
[
B
postpone C
D
postpone E
F
]
G
postpone
[
H
postpone J
K
postpone L
M
]
N
Si necesita crear y probar configuraciones avanzadas como la anterior, recuerde que siempre puede hacer un seguimiento del orden de ejecución de los pasos desde el registro.
Ejemplo
Este ejemplo muestra un posible uso de los pasos aplazados. Este trabajo se ejecuta como un servicio web y puede ser invocado en cualquier momento por un cliente, incluso desde el navegador.
El paso A ejecuta un comando de shell que lleva mucho tiempo y que enumera de forma recursiva todos los directorios y archivos dentro de un directorio grande del sistema. Por esta razón, el paso A se define como paso aplazado. El paso B toma el resultado estándar (stdout) generado por A y lo escribe en un archivo. El paso B depende de la salida que genere A y, por tanto, también debe formar parte de la secuencia aplazada. El paso C informa a los emisores de llamadasa al servicio de que la tarea se ha enviado correctamente. Siempre que se llama al servicio web, los pasos anteriores se ejecutan en este orden: C, A, B. El motivo es que A y B son pasos aplazados, por lo que C se ejecuta primero.
La ventaja de esta configuración es que el trabajo devuelve un resultado inmediatamente después de ejecutar el paso C y la transacción HTTP puede terminar, lo que libera recursos del servidor para otras solicitudes. Después de devolver el resultado del trabajo, FlowForce procede a ejecutar los pasos aplazados A y B en la secuencia habitual.
Cuando invoque el trabajo anterior en su navegador, aparecerá el mensaje La tarea se ha enviado correctamente en el navegador. Al mismo tiempo, el trabajo continúa ejecutándose hasta que crea el archivo output.txt. Si ni A ni B fallan se crea el archivo de salida en la ruta de acceso: C:\FlowForce\Postponed\output.txt.
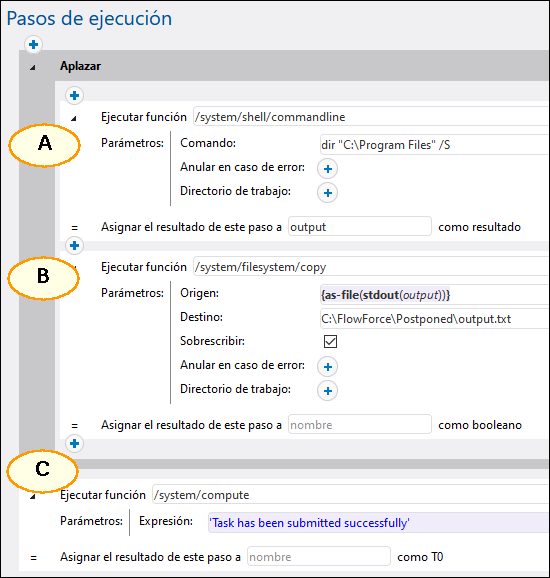
Nota sobre el orden de los pasos
En este ejemplo, el paso C tiene que ser el último del trabajo porque produce el resultado que se envía al explorador. Si coloca el paso C en el primer puesto, se sigue ejecutando primero y el paso B sigue siendo el último que se ejecuta. Sin embargo, esto cambiaría el resultado del trabajo y el explorador mostraría una salida vacía parecida a []. La razón es que el resultado de un trabajo de FlowForce es siempre el resultado del último paso que se ejecuta. Los pasos aplazados no tienen un valor devuelto, pero generan una secuencia vacía.