API REST HTTP
RaptorXML+XBRL Server accepte les tâches soumises par HTTP (ou HTTPS). La description de la tâche ainsi que les résultats sont échangés dans le format JSON. Le flux de travail de base est tel que montré dans le diagramme ci-dessous.
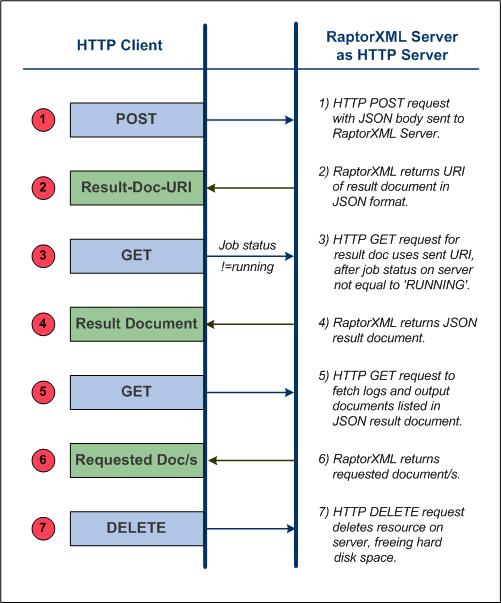
Préoccupations en matière de sécurité liées à l'API REST HTTPPar défaut, l'API REST HTTP permet d'enregistrer les documents de résultats à n'importe quel emplacement spécifié par le client (accessible via le protocole HTTP). Il est donc essentiel de prendre en compte cet aspect de sécurité lors de la configuration de RaptorXML+XBRL Server.
Si vous craignez que la sécurité soit compromise ou que l'interface soit utilisée de manière abusive, le serveur peut être configuré pour enregistrer les documents de résultats dans un répertoire de sortie dédié sur le serveur lui-même. Pour ce faire, définissez l'option server.unrestricted-filesystem-access du fichier de configuration du serveur sur false. Lorsque l'accès est restreint de cette manière, le client peut télécharger les documents de résultats à partir du répertoire de sortie dédié à l'aide de requêtes GET. Par ailleurs, un administrateur peut copier/télécharger les fichiers de résultats depuis le serveur vers l'emplacement cible. |
Dans cette section
Avant d'envoyer une requête client, RaptorXML+XBRL Server doit être lancé et configuré correctement. La procédure est décrite dans la section Configuration de serveur. La section Requêtes Client décrit comment envoyer des requêtes client. La rubrique Fichier de description OpenAPI décrit le fichier de définition OpenAPI fourni avec RaptorXML+XBRL Server qui vous permet d'interagir avec l'API HTTP. Enfin, la section C# Example pour API REST fournit une description de l’exemple de fichier API REST qui est installé avec votre package RaptorXML+XBRL Server.