Join Optimization
Join optimization accelerates execution of data mappings in which large sets of data are being filtered or joined.
Join optimization works by eliminating nested loops that occur internally as a mapping is being executed. A nested loop occurs when the mapping iterates each item of a set as many times as there are items in a second set. Note that it is normal for the mapping execution engine* to perform loops (iterations) over various sequences of items, by virtue of its design. When nested independent loops occur (that is, loops which iterate over other loops), the mapping can benefit from join optimization, which would significantly reduce the time required to execute the mapping. Nested loops are hardly noticeable when running mappings where the input data is not significantly large; however, this can become a challenge in case of mappings that process files or databases that consist of a very large number of records.
* The execution engine of a mapping can be MapForce, MapForce Server, or a C#, C++, or Java program generated by MapForce. Join optimization is available exclusively in the MapForce Server Advanced Edition.
To designate MapForce Server as target execution engine, click the BUILT-IN ( |
 ) toolbar button in MapForce. This will also ensure your mapping benefits from most available features. If you select another transformation language, certain MapForce features might not be supported in that language.
) toolbar button in MapForce. This will also ensure your mapping benefits from most available features. If you select another transformation language, certain MapForce features might not be supported in that language.
As mentioned above, the primary concern of join optimization is to address nested loops in an efficient way. Let's now have a closer look at how nested loops occur in first place.
The typical case when nested loops occur is when the mapping contains at least one Join component, and SQL JOIN mode** is not possible.
** When certain conditions are met in MapForce, mappings could allow for a special execution mode called "SQL Join mode". SQL Join mode is possible only if the mapping reads data from a database. When data is joined this way, the join operation is undertaken by the database (that is, an SQL JOIN takes place), and this eliminates the need for nested loops in the mapping execution engine. For more information about SQL Join mode, refer to the MapForce documentation (https://www.altova.com/documentation.html). |
For example, the image below illustrates a mapping (designed with Altova MapForce) which combines data from two XML files using a Join component. On the computer where MapForce is installed, this mapping is available at the following path: ..\Documents\Altova\MapForce2026\MapForceExamples\Tutorial\JoinPeopleInfo.mfd. Some people data is available only in the first XML file (Email, Phone), while some other data is available only in the second XML file (City, Street, Number). The goal of the mapping is to write to the target XML file the merged data of all people where FirstName and LastName correspond in both source structures.
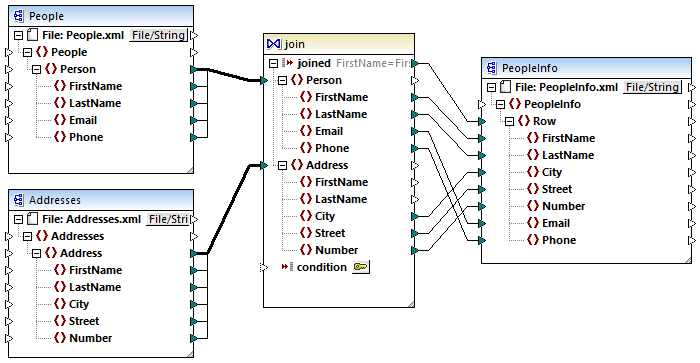
JoinPeopleInfo.mfd
In MapForce, a Join component pairs items in two sets according to some custom condition, which implies comparing each item in set 1 with each item in set 2. The total number of comparisons represents the cross-join (Cartesian product) of both sets. For example, if the first set contains 50 items, and if the second set contains 100 items, then a total of 5000 (50 x 100) comparisons will occur. In the mapping above, the sets that are being compared correspond to all instance items of the two XML structures connected to the Join component.
Note: Join optimization (a feature of MapForce Server Advanced Edition) should not be confused with Join components (a feature of MapForce). For more information about Join components, refer to the MapForce documentation (https://www.altova.com/documentation.html).
As expected, from a performance perspective, mappings that contain nested loops would need more time to run. Imagine a situation where both joined sets contain millions of records. This can easily affect performance, and this is where join optimization is useful. In very broad lines, join optimization behaves like a database engine that is optimized to look up (index) extremely large sets of data. Except that, as illustrated by the mapping above, join optimization deals not only with data originating from databases. Join optimization eliminates nested loops regardless of the data kind, by building, where possible, internal lookup tables which are queried at mapping runtime. This significantly improves the mapping performance and ultimately reduces the time required to execute the mapping.
Note: When join optimization occurs, running the mapping will take less time but typically require more memory as well. Be aware that memory usage patterns depend on various complex factors; therefore, observed behaviour may differ depending on the case.
Join optimization can accelerate not only mappings with joins, but also those which use filter components. In MapForce, a filter processes a sequence of items (that is, it checks a given Boolean condition for each instance of the item connected to the node/row input). If the Boolean condition is connected to a function which, in its turn, must iterate over another sequence of items, and if the mapping context demands it, then a situation similar to a join happens. If the filter must perform a cross-comparison of each item in two sets, then it qualifies for join optimization.
In order for the mapping to benefit from join optimization, it must be run by MapForce Server Advanced Edition. To execute a mapping with MapForce Server Advanced Edition, open it in MapForce, and compile it to a mapping execution (.mfx) file using the menu command File | Compile to MapForce Server Execution File. Then run the .mfx file by using an API method in your language of choice, or the run command of the command line interface (see also How It Works).