Overview
This topic provides an overview of the interface and features of the PDF Extractor.
How to run PDF Extractor
To launch the PDF Extractor, you can choose one of the following options:
•You can run the PDF Extractor directly from MapForce. This option is useful when you want to create a new PDF extraction template directly from MapForce.
•You can also start the PDF Extractor as a standalone program, by running the Altova MapForce PDF Extractor executable from the Start menu or the MapForce installation directory.
For more information about how to create a PDF extraction template, see Create a New Template.
GUI overview
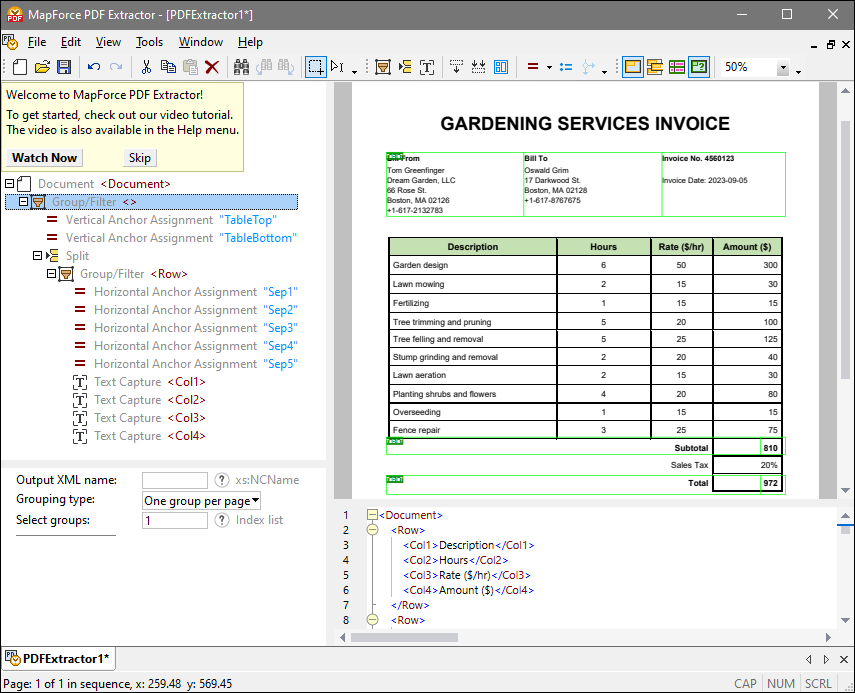
The screenshot below illustrates the interface of the PDF Extractor. The interface is organized into five distinct parts:
•the top part, which contains different menu and toolbar commands,
•the Schema Pane (top left part), which enables you to define the structure of your PDF document and extraction rules,
•the PDF View Pane (top right part), in which you can see your PDF file and use visual prompts to define extraction rules,
•the Properties Pane (bottom left part), which enables you to define various properties and calculate expressions,
•the Output Pane (bottom right part), which shows what the structure and data of your PDF document will look like, based on the properties and layout you have defined.
Schema and Properties panes
The structure of a template in the Schema pane consists of various template objects, which are the fundamental building blocks of any template. The properties of template objects are defined in the Properties Pane.
Output pane
The structure in the Output pane is represented as an XML tree.
Multiple templates
The PDF Extractor allows you to work on multiple templates at a time. Each template has its own separate window. In the screenshot above, there is only one template called PDFExtractor1. All PDF extraction templates created in the PDF Extractor are saved with a .pxt extension.
Electronically created and scanned documents
You can extract text from electronically created and scanned PDF documents. For more information, see the links below.
•Tutorial: Helps you quickly get started with PDF extraction.
•Template Objects: Provides an overview of the available objects in a PDF template.
•Scanned Documents: Provides an overview of the Optical Character Recognition (OCR) feature.
•OCR Workflow: Describes the main stages of text extraction from scanned PDF documents.
•OCR Tutorial: Provides a step-by-step example of applying OCR to a scanned PDF file.
Search functionality
The PDF Extractor has a powerful text-searching functionality. You can do a search in the GUI as well as at runtime. For more information, see Search Functionality and Find Text. Besides, you can group PDF data by text found or not found on a page. See Group/Filter for details.