アイコンとショートカット
コマンド |
アイコン |
ショートカット |
検索 |
|
Ctrl+F |
次を検索 |
|
F3 |


検索
検索 コマンド により、検索ダイアログが表示され、検索を行ないたい文字列の入力や、検索に伴う各種オプションを指定することができます。 使用しているビューに従って、検索ダイアログには異なるオプションが表示されます。 テキストの検索を行うには、検索対象テキストボックスにその文字列を入力するか、コンボボックスを使用して、最後に使用された10個ある検索文字列から選択を行い、検索に必要なオプションを指定します。
検索 と 次を検索 コマンドをプロジェクトウィンドウ内でプロジェクトが選択されるとファイルとフォルダーを検索するために使用することができます。
グリッドビュー
グリッドビューでは、次のダイアログボックスが表示されます。 必要なオプションを選択、または、ラジオボタンを選択します。使用することのできるオプションについては下で説明されています。
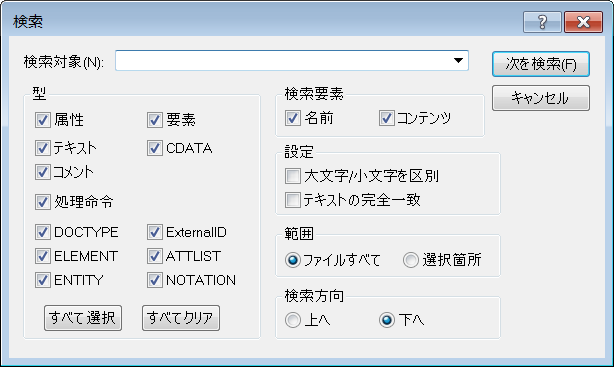
•型ペインでは、検索対象に含める XML ドキュメントのノードやコンポーネントを指定することができます。この機能により、特定の型のノードを検索から除外することができます。「全て選択」ボタンにより、ペイン内にある「全てのチェック」ボックスが有効になり、「全てクリア」ボタンにより、全てのチェックボックスが無効になります。
•検索対象ペインでは、入力された検索文字列に対して、ノード名、ノードのコンテンツ、またはそれら両方を検索対象に含めるか指定することができます。
•設定ペインでは、検索において大文字と小文字の区別を行うか、または検索対象が入力テキストに完全に一致するかを指定することができます。
•範囲ペインでは検索の範囲を指定することができます (ファイル全体、または、選択されたテキスト)。
•検索方向オプションでは、検索が行われる向きを指定することができます。
テキストビュー
編集することのできるテキストビューの検索機能に関しては、以下のセクションを参照してください: テキストビュー。 (XPath/XQuery ウィンドウ などの) 編集することのできないテキストビューの検索機能については下で説明されています。
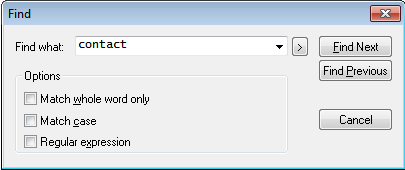
•単語の完全マッチ:テキスト内にある正確な単語だけが検索のマッチ対象となります。例えば、単語の完全マッチオプションを有効にして、fit という単語で検索を行うと、fit という文字列だけが検索結果として表示され、fitness という単語はマッチしません。
•大文字・小文字を区別:大文字と小文字を区別した検索を行います(Address と address は別物として扱われます)。
•正規表現:テキストボックスに入力された文字列を正規表現として、検索を行います。正規表現については、 正規表現 を参照ください。
以下の点に注意してください:
•検索ダイアログはモードレスになっており、テキストビューを使用中も、ダイアログを開いたままにしておくことができます。 ダイアログボックスが開いている間、 Enter を押すと、ダイアログボックスが閉じられます。ダイアログボックスを開く前にテキストがマークされると、マークされたテキストは自動的にテキストの検索ボックスに挿入されます。
•検索ダイアログが閉じられた後、F3 を押下することで現在の検索を継続して行うことができます。Shift+F3 により、反対方向へ検索が行われます。
•検索対象コンボボックスの右側にある「展開」ボタンをクリックすると正規表現 を使用するためのウィンドウが表示されます。
正規表現を使用することで、検索の条件をさらに絞り込むことができます。表示されるポップアップリストから正規表現を構築することができます。リストへのアクセスを行うには、検索文字列を入力するフィールドの右にある > ボタンをクリックします。
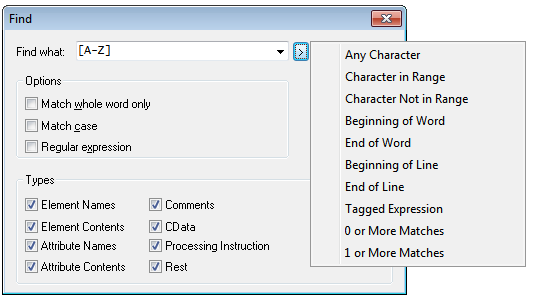
表示されているアイテムをクリックすることで、それに対応した正規表現が入力フィールドに入力されます。正規表現の構文文字とその説明を以下に示します。
. |
全ての文字列にマッチします。これは1つの文字に対応したプレースホルダーです。 |
\( |
マッチのタグ付けを行うための開始マーク。. |
\) |
タグ付けの終了マーク |
\n |
ここでの n は 1 から 9 までの数値を表わしており、上でタグ付けされた範囲を置換えにて使用することができます。例えば、検索文字列が Fred\([1-9])XXX で、置換え文字列が Sam\2YYY である場合、Fred2XXX という文字列が Sam2YYY という文字列に置換えられます。 |
\< |
単語の開始位置にマッチします。 |
\> |
単語の終了位置にマッチします。 |
\x |
通常正規表現にて特別な意味を持つ x という文字を、通常の文字として扱います。例えば、\[ という文字列は、文字セットの開始ではなく [ として認識されます。 |
[...] |
文字のセットを表します。例えば、[abc] という表現により、a、b、c 全ての文字がマッチするようになります。それ以外にも [a-z] という形で範囲を指定することにより、この例では小文字全てをマッチの対象とすることができます。 |
[^...] |
指定された文字セット以外のものにマッチします。例えば、[^A-Za-z] という表現では、アルファベット以外の文字列がマッチの対象になります。 |
^ |
行頭を表します(上で述べられている文字のセットで使用される場合を除く)。 |
$ |
行末を表します。例えば A+$ という表現で、行末に1つ以上連続して並んでいる A を検索します。 |
* |
0 回以上の繰り返しにマッチします。例えば、Sa*m という表現は、Sm、Sam、Saam、Saaam といった文字列にマッチします。 |
+ |
例えば、Sa+m という表現は、Sam、Saam、Saaam といった文字列にマッチします。 |
| メモ: | 置換 フィールドにて正規表現はサポートされていません。 |
次を検索
次を検索 コマンドは、最後に実行された検索コマンドを再度実行し、目的のテキスト内で次に出現する検索結果を表示します。