Aperçu
Cette rubrique présente une vue d'ensemble de l'interface et des fonctionnalités de PDF Extractor.
Comment exécuter l’Extracteur PDF
Pour lancer l'Extracteur PDF, vous pouvez choisir l’une des options suivantes :
•Vous pouvez exécuter l’Extracteur PDF directement depuis MapForce. Cette option est utile quand vous créez un nouveau modèle d’extraction PDF directement depuis MapForce.
•Vous pouvez aussi lancer l'Extracteur PDF en tant que programme autonome, en démarrant le fichier exécutable Altova MapForce Extracteur PDF depuis le menu Démarrage ou le répertoire d’installation MapForce.
Pour plus d’information sur la création d’un modèle d’extraction PDF, voir Créer un nouveau modèle.
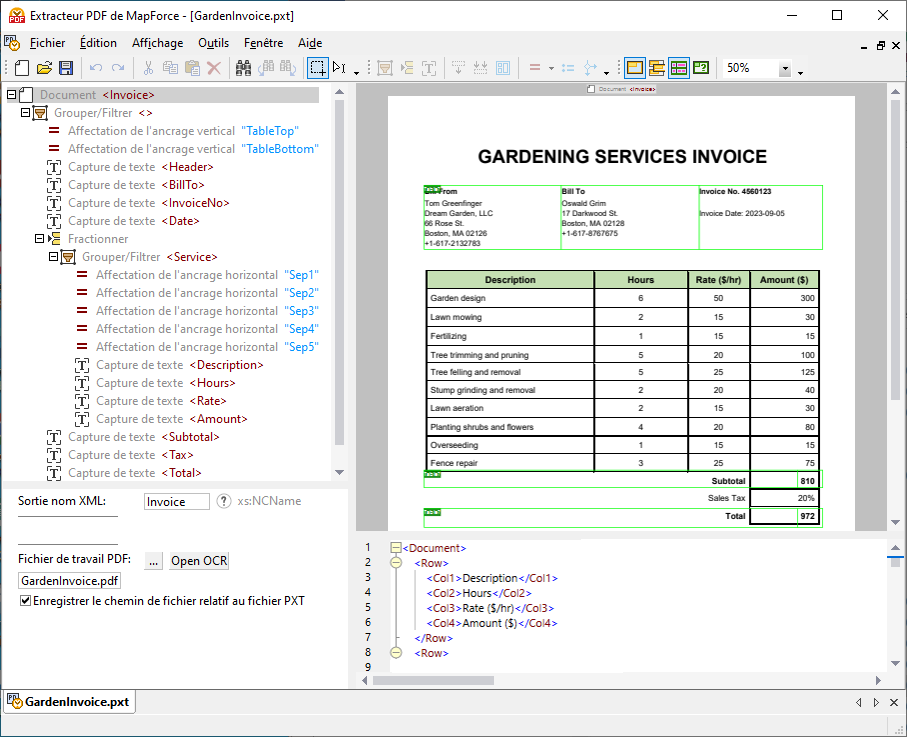
Aperçu GUI
La capture d’écran ci-dessous illustre l’interface de l’Extracteur PDF. L’interface est organisée en cinq parties distinctes :
•la partie supérieure, qui contient différents menus et commandes de la barre d'outils,
•le volet de schéma (partie supérieure gauche), qui vous permet de définir la structure de votre document PDF et les règles d’extraction,
•le volet d’affichage PDF (partie supérieure droite), dans laquelle vous pouvez consulter votre fichier PDF et utilisez les invites visuelles pour définir les règles d’extraction,
•le volet des propriétés (partie inférieure gauche), qui vous permet de définir différentes propriétés et calculer les expressions,
•le volet de sortie (partie inférieure droite), qui montre l’aspect qu’auront vos structure et données de votre document PDF, basés sur les propriétés et la mise en page que vous avez définies.
Volets de Propriétés et de Schéma
La structure d'un modèle dans le volet Schéma est composée de divers objets modèle, qui constituent les éléments fondamentaux de tout modèle. Les propriétés des objets modèles sont définies dans le volet Propriétés.
Volet Sortie
La structure dans le volet Sortie est représentée sous forme d'arborescence XML.
Multiples modèles
L’Extracteur PDF vous permet de travailler sur de multiples modèles en même temps. Chaque modèle a sa propre fenêtre séparée. Dans la capture d’écran ci-dessus, il existe uniquement un modèle appelé PDFExtractor1. Tous les modèles d’extraction PDF que vous créez dans l’Extracteur PDF sont enregistrés avec une extension .pxt.
Documents créés électroniquement et numérisés
Vous pouvez extraire du texte à partir de documents PDF créés électroniquement et numérisés. Pour plus d'informations, voir les liens ci-dessous.
•Tutoriel : vous aide à vous familiariser rapidement avec l'extraction de PDF.
•Objets modèle : fournit une vue d'ensemble des objets disponibles dans un modèle PDF.
•Documents numérisés : fournit une vue d'ensemble de la fonctionnalité de reconnaissance optique de caractères (OCR).
•Flux de travail OCR : décrit les principales étapes de l'extraction de texte à partir de documents PDF numérisés.
•Tutoriel OCR : fournit un exemple étape par étape de l'application de l'OCR à un fichier PDF numérisé.
Fonction Recherche
L’Extracteur PDF a une fonction puissante de recherche de texte. Vous pouvez également effectuer une recherche dans la GUI au moment de l´exécution. Pour plus d’information, voir Fonction Recherche et Recherche Texte. Vous pouvez de toute façon regrouper les données PDF par texte trouvé ou non sur une page. Voir Groupe/Filtre pour les détails.