Options pour la comparaison XML
L’onglet XML du dialogue Options de comparaison affiche les options qui sont utilisées pour la comparaison XML
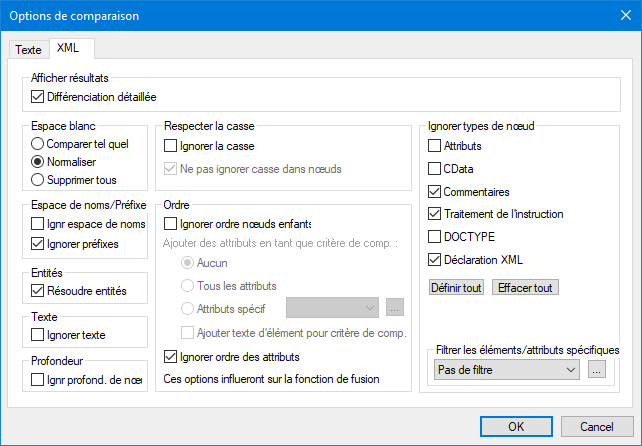
Voir les résultats
L’option Différenciation détaillée vous permet de montrer les différences en détail ou de réduire le nombre de différences (pour que la navigation soit plus rapide). Si la différenciation détaillée est éteinte, les nœuds consécutifs qui sont différents sont affichés en tant qu’un seul nœud. Cela s'applique aussi aux nœuds consécutifs à des niveaux hiérarchiques différents, comme un nœud d’élément et son nœud d’attribut enfant.
Veuillez prendre note des points suivants :
•Dans le Mode Grille les différences consécutives sont comptabilisées ensemble comme une différence, tandis que, dans le Mode Grille, ils sont comptabilisés comme différences séparées. En guise de résultat, le compte des différences dans le Mode Texte pourrait être plus élevé.
•La différentiation détaillée doit être sélectionnée pour permettre la fusion et l’exportation des différences.
Espace blanc
Voir Options de comparaison pour les caractères d’espace blanc.
Espace de noms/Préfixe
Il s’agit d’options pour ignorer les espaces de noms et les préfixes lorsque vous cherchez des différences.
Entités
Si Résoudre entités a été sélectionné, toutes les entités dans le document sont résolues. Sinon, les fichiers sont comparés avec les entités tels quel.
Texte
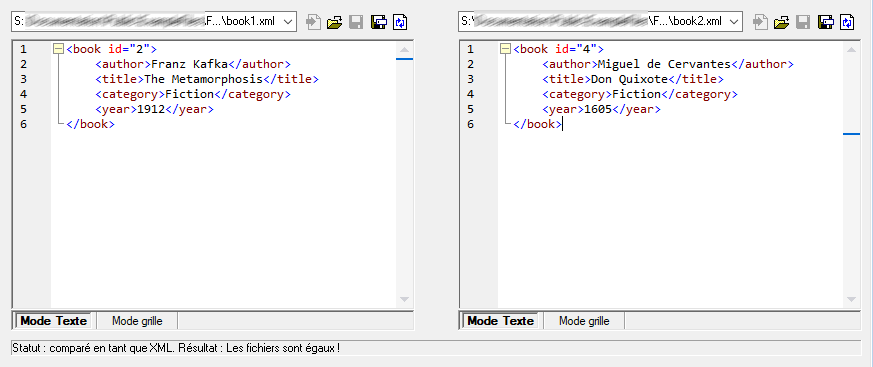
Si Ignorer texte a été sélectionné, les différences dans la comparaison des nœuds de texte ne sont pas rapportées. Seule la structure XML est comparée mais pas le contenu de texte. Cela est utile lorsque vous souhaitez comparer deux structures XML et ignorer le contenu. Par exemple, nous partons du principe que la case à cocher Ignorer texte a été cochée. Dans ce cas, les deux fichiers XML suivants sont égaux (même si leur contenu diffère).
Profondeur
Si Ignorer profondeur de nœud a été sélectionné, les éléments sont traités en tant qu’égaux quel que soit leur profondeur. Par exemple, partons du principe que la case à cocher Ignorer profondeur de nœud a été sélectionnée. Dans ce cas, dans une comparaison comme celle ci-dessous, l’élément <c> est égal des deux côtés, bien qu’il soit imbriqué plus profondément du côté droit.
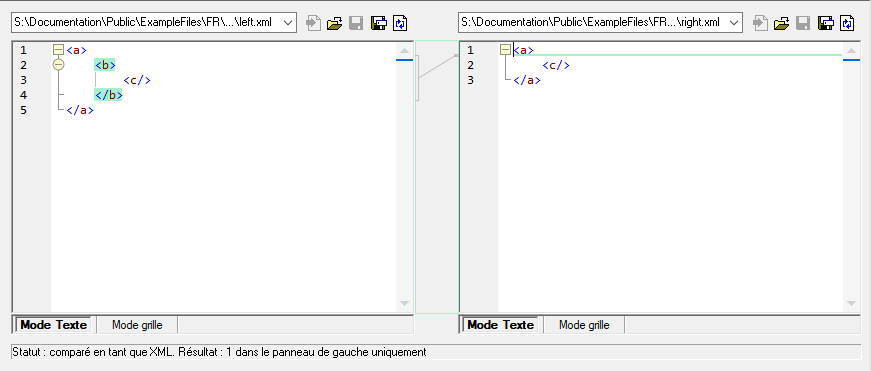
Note : si la case à cocher Ignorer profondeur de nœud a été sélectionnée, il n’est pas possible d’effectuer des fusions et des exportation de différences.
Sensibilité à la casse
Si la case à cocher Ignorer casse a été cochée, la casse est ignorée et vous avez la possibilité d’ignorer ou de ne pas ignorer la casse dans les noms de nœud.
Ordre
Si Ignorer ordre des nœuds enfant a été sélectionné, la position relative des nœuds enfant d’un élément est ignorée, si les nœuds individuels dans un niveau de nœud ont des noms de nœud uniques. Tant qu’un nœud d’élément avec le même nom existe dans chacun des deux ensembles de nœuds frères, les deux ensembles sont considérés être égaux. Dans l’exemple suivant, l’ordre des nœuds <Name> et <FirstName> est différent dans le fichier gauche et droite et est marqué comme différent si l’option Ignorer ordre des nœuds enfants est désactivée.

Si vous cochez l’option Ignorer ordre des nœuds enfants cette différence sera ignorée dans la fenêtre de comparaison.

Néanmoins, veuillez noter que DiffDog peut ignorer l’ordre des s enfants uniquement si les noms de nœud dans un certain niveau de nœud sont uniques. Si plusieurs occurrences d’un nœud apparaissent, par exemple avec une attribution de différents attributs, un nœud, s’il apparaît dans un ordre différent sera toujours considéré inégal par rapport à un élément portant le même nom et attribut dans l’ensemble frère, même si Ignorer l’ordre des nœuds enfants a été sélectionné. Si nous ajoutons des attributs différents dans le nœud <Phone> de notre exemple, alors la différence dans l’ordre des trois occurrences du nœud <Phone> apparaîtra dans la fenêtre de comparaison bien que la case Ignorer l’ordre des nœuds enfants a été sélectionnée.

Pour pouvoir ignorer l’ordre de plusieurs occurrences de nœuds enfants auxquels ont été attribués plusieurs attributs, vous pouvez ajouter ces attributs en tant que critères de comparaison. DiffDog permet deux options : (i) ajouter tous les attributs et (ii) définir une liste des attributs spécifiques, qui, dans notre exemple résulteront tous deux dans les nœuds <Phone> affichés en tant qu’égal. Néanmoins, si vous sélectionnez l’option Attributs spécifiques, vous devrez tout d'abord définir un groupe d’attributs en conséquence.

Il peut arriver que plusieurs occurrences de nœuds enfants apparaissent auxquels le même attribut a été attribué (dans notre exemple, une personne avec plus d’un numéro de téléphone mobile). Dans l’image ci-dessous, le bouton radio Tous les attributs a été sélectionné, néanmoins, les différences sont toujours rapportées puisque deux numéros de téléphones mobiles sont listés.

DiffDog vous permet de gérer ce type de scénario également en cochant la case Ajouter le texte d’élément en tant que critère de comparaison. Si le texte d’élément, la valeur d'attribut et le nom de nœud sont identiques si seul l’ordre des nœuds est différent, aucune différence ne sera rapportée.

Veuillez noter que, si l’option Ignorer ordre est spécifiée, la fonction de fusion ignorera aussi l’ordre. Si Ignorer ordre des nœuds enfants est décochée, les différences d’ordre sont représentées en tant que différences.
L’option d’ignorer l’ordre des attributs est aussi disponible et s’applique à l’ordre des attributs d’un élément unique. Dans l’exemple ci-dessus, l’option Ignorer ordre des attributs a été cochée et DiffDog, a donc ignoré l’ordre des attributs du nœud <Person>. Veuillez noter que l’ordre des attributs sera toujours ignoré si la case Ignorer ordre des nœuds enfants a été activée. Dans la capture d’écran ci-dessous, les deux cases Ignorer ordre des nœuds enfants et Ignorer ordre des attributs ont été décochées.

Ignorer types de nœud
Cocher les types de nœud qui ne seront pas comparés dans la session Comparer. Les types de nœud qui peuvent être ignorés sont : Attributs, CDATA, Commentaires, Instructions de traitement, instructions DOCTYPE et déclarations XML.
Filtrer les éléments/attributs spécifiques
Vous permet de définir des filtres pour définir les éléments et/ou les attributs qui ne doivent pas être considérés pour une comparaison. Un filtre est défini au niveau de l’application, ce qui signifie qu’une fois qu’un filtre a été défini, il est disponible pour toutes les comparaisons. Il est possible de définir plus d’un filtre, et pour chaque comparaison, le filtre à utiliser est sélectionné dans la liste déroulante dans le groupe Filtrer les éléments/attributs spécifiques.